: A Production Architecture for Trustworthy AI Systems")
The Context Reliability Framework (CRF): A Production Architecture for Trustworthy AI Systems
Introducing the Context Reliability Framework (CRF) for Production-Grade AI Systems

Introduction
Most engineers blame the model when an AI system fails.
If an output is incorrect, hallucinated, or inconsistent, the immediate assumption is that the model is unreliable. Engineers start tweaking prompts, adjusting temperature settings, or swapping models entirely.
But in real production environments, that is rarely the root cause.
Failures usually happen before the model is invoked — inside the context pipeline that feeds the model.
This is the hidden reliability problem in modern AI systems.
Production AI deployments have revealed a consistent pattern: model failures are often symptoms, not causes. The true failures originate upstream, where context is assembled, validated, and delivered to the model.
The Hidden Reliability Problem
In production environments, AI failures frequently arise from context pipeline instability.
Examples include:
- Retrieval returning outdated data
- Tools executing with incompatible schemas
- Memory persisting corrupted state
- Recovery logic failing silently
- Logging failing to capture intermediate states
- Permission systems allowing unsafe execution
None of these failures are caused by the model itself.
They are context reliability failures.
And that realization changes how we design production AI systems.
Introducing the Context Reliability Framework (CRF)
The Context Reliability Framework (CRF) is a structured architecture designed to ensure that every model invocation operates on correct, traceable, recoverable, and governed context.
CRF focuses on building deterministic reliability into systems that are inherently probabilistic.
It ensures:
- Context correctness
- Context traceability
- Context recovery
- Context observability
- Context governance
Across production AI workflows.
The Five Core Layers of CRF
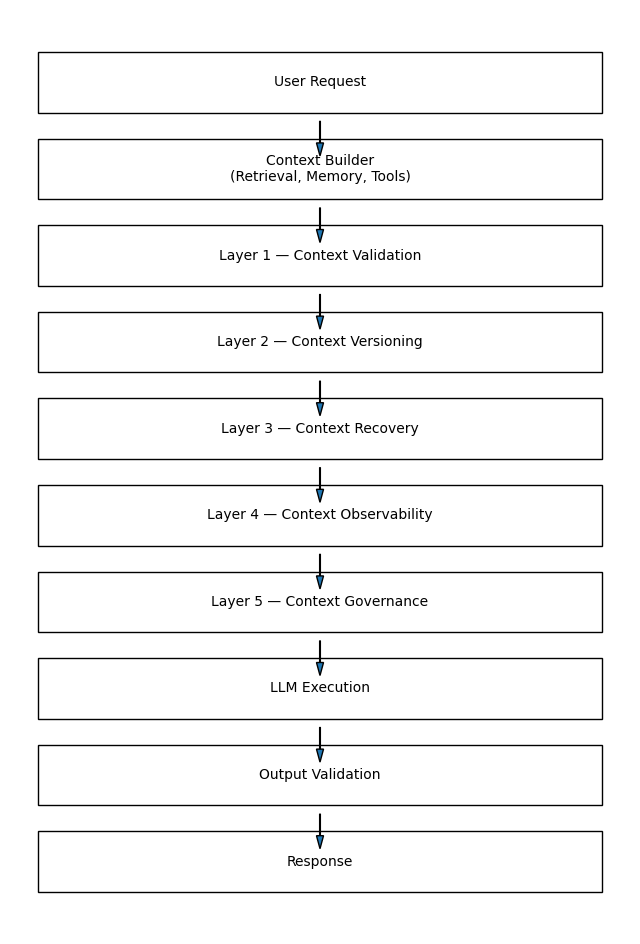
CRF is built on five reliability layers that operate before, during, and after model execution.
Layer 1 — Context Validation
Before context reaches the model, it must be validated.
Validation ensures:
- Structural correctness
- Semantic integrity
- Operational safety
Key mechanisms include:
- Schema validation
- Tool compatibility checks
- Retrieval sanity validation
- Input normalization
Without validation, small errors propagate into major failures.
Layer 2 — Context Versioning
Context changes constantly.
Documents update. Tools evolve. Memory grows.
Without versioning, debugging becomes nearly impossible.
CRF introduces context snapshots that enable rollback and replay.
Layer 3 — Context Recovery
Failures are inevitable.
Reliable systems do not eliminate failures — they recover from them automatically.
CRF introduces:
- Checkpoint restoration
- Retry logic
- Context rebuild pipelines
- Safe rollback mechanisms
Recovery transforms failures from catastrophic to recoverable.
Layer 4 — Context Observability
You cannot fix what you cannot see.
Observability introduces:
- Execution tracing
- Logging pipelines
- Latency monitoring
- Error tracking
Observability enables:
- Root cause analysis
- Performance optimization
- Debugging at scale
Layer 5 — Context Governance
Enterprise systems must enforce rules.
Governance introduces:
- Role-based access control
- Security validation
- Data masking
- Compliance auditing
Reliability alone is not enough — systems must also be safe.
A Real Production Failure — Tool Drift Incident
Tool drift is a common production failure pattern.
Symptoms:
- Incorrect tool execution
- Invalid outputs
- Silent data corruption
Root Cause:
Tool schema changed, but validation was missing.
CRF prevents this by:
- Detecting schema mismatch
- Restoring stable versions
- Logging anomalies
- Enabling rollback
Failures become controlled — not catastrophic.
CRF Data Flow Diagram
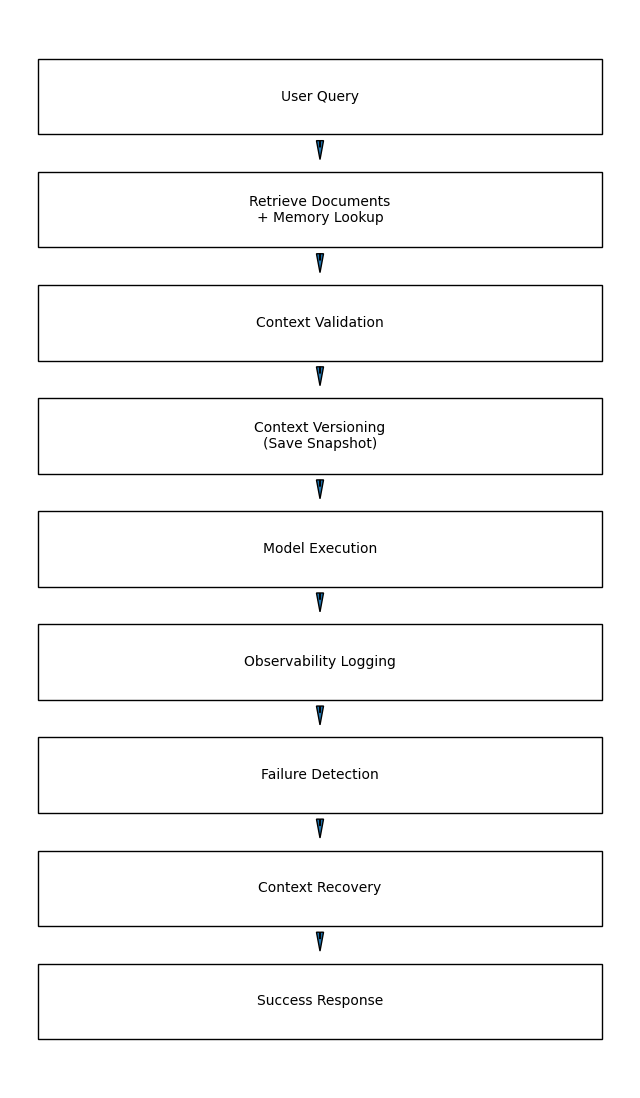
This runtime pipeline creates fault-tolerant behavior.
Instead of fragile pipelines, systems become resilient infrastructures.
Why CRF Matters for Enterprise AI
The need for structured context reliability becomes even more visible when examining real-world enterprise systems.
In financial services, automated decision systems often rely on multiple context sources, including transaction history, compliance policies, and risk scoring tools. A failure in context validation could result in incorrect financial recommendations or regulatory violations. CRF ensures that only validated, policy-compliant context reaches the model, reducing operational risk.
In healthcare systems, context reliability directly impacts patient safety. Clinical decision-support tools depend on accurate retrieval of patient records, treatment guidelines, and diagnostic tools. If outdated or incomplete medical context is supplied to the model, incorrect recommendations may occur. Versioning and recovery layers allow healthcare systems to maintain historical traceability and restore safe context states when errors occur.
Customer support automation also benefits significantly from CRF-based reliability. When AI agents access customer data, billing systems, and service logs, incorrect context assembly may lead to inconsistent responses or unauthorized actions. Governance layers enforce permission rules and restrict sensitive operations, ensuring secure and predictable system behavior.
These use cases demonstrate that context reliability is not just a technical concern — it is an operational requirement in industries where failure carries measurable consequences.
Enterprise systems require:
- Predictability
- Traceability
- Reliability
- Security
- Compliance
CRF enables:
- Deterministic workflows
- Safe automation
- Audit-ready infrastructure
Without reliability, AI cannot scale.
Reliability Metrics Enabled by CRF
CRF introduces measurable reliability signals.
Reliability metrics become meaningful only when they are connected to operational behavior.
For example, a high Context Validation Success Rate indicates that upstream data pipelines are delivering structurally valid inputs. A sudden drop in this metric often signals schema drift, integration failures, or data source inconsistencies.
Mean Time to Recovery (MTTR) is another critical indicator of system maturity. Lower MTTR values suggest that recovery mechanisms are functioning effectively and that failure handling pipelines are well-designed. In large-scale enterprise deployments, reducing MTTR can directly improve service availability and customer satisfaction.
Context Drift Detection Rate provides insight into how frequently system components evolve in incompatible ways. Monitoring this metric helps teams proactively address version mismatches and tool compatibility issues before they impact production workloads.
By translating reliability metrics into actionable insights, CRF transforms AI reliability from an abstract concept into a measurable engineering discipline.
Key metrics include:
- Context Validation Success Rate
- Recovery Success Rate
- Mean Time to Recovery (MTTR)
- Context Drift Detection Rate
- Tool Execution Reliability
These metrics transform AI systems into observable engineering systems.
The Shift From Prompt Engineering to Reliability Engineering
Early AI systems focused on prompt engineering.
Modern systems focus on context engineering.
Future systems will focus on reliability engineering.
CRF sits at the center of this transition.
Production Readiness Checklist
Adopting CRF does not require replacing existing infrastructure. Instead, it involves introducing reliability checkpoints into current pipelines.
Most organizations can begin by implementing validation layers using schema enforcement libraries and structured input validators. Versioning can be introduced through snapshot storage systems, allowing context states to be recorded and replayed during debugging.
Observability integration typically leverages existing logging platforms, such as centralized monitoring dashboards or distributed tracing tools. Recovery mechanisms can be implemented incrementally by defining rollback strategies and retry policies for critical workflows.
The incremental nature of CRF adoption makes it practical for both small teams and large enterprise organizations. Reliability improvements can be introduced step by step, without disrupting operational continuity.
Before deploying an AI system:
- Is context validated?
- Is context versioned?
- Can context be recovered?
- Is context observable?
- Is governance enforced?
If any answer is no, reliability risk exists.
The Future of Reliable AI Systems
Over the next five years, reliability frameworks will become standard infrastructure.
Not optional tooling.
Just as logging frameworks became mandatory in distributed systems, reliability frameworks will become mandatory in AI systems.
The systems that succeed will not be the smartest models.
They will be the most reliable systems.
Final Takeaway
Reliable AI systems are not built with better prompts.
They are built with reliable context pipelines.
And reliable context pipelines require structured reliability frameworks.
That is the purpose of the Context Reliability Framework (CRF).
Not just to make AI work.
But to make AI work consistently
References
[1] Google Cloud Architecture Framework — Reliability
https://cloud.google.com/architecture/framework/reliability
[2] AWS Well-Architected Framework — Reliability
https://aws.amazon.com/architecture/well-architected/
[3] Dean, J. & Barroso, L. (2013). The Tail at Scale. Communications of the ACM.
[4] Kleppmann, M. (2017). Designing Data-Intensive Applications. O’Reilly Media.
[5] OpenAI Documentation — Tool Reliability and Function Calling
https://platform.openai.com/docs
The Context Reliability Framework (CRF): A Production Architecture for Trustworthy AI Systems was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.