
The Air-Gapped Chronicles: The Insurance Gap — Building Liability-Resistant AI Without Coverage
The Air-Gapped Chronicles: The Insurance Gap — Building Liability-Resistant AI When Insurance Won’t Cover the Risk
Insurance companies are excluding AI from coverage. Here’s the production architecture that reduces your liability exposure when chatbots can kill and nobody will pay the claim.
On February 28, 2024, a 14-year-old boy named Sewell Setzer III had his final conversation with a Character.AI chatbot. He told the bot he wanted to “come home” to it. The bot responded: “Please do, my sweet king.”
Minutes later, he died by suicide.
His mother filed a wrongful death lawsuit in October 2024. Character.AI and Google settled in January 2026. Settlement terms are confidential.
Here’s the question nobody’s answering: Did insurance cover the settlement?
Two weeks earlier, Air Canada was ordered to pay $812 after their chatbot gave incorrect bereavement fare information to a grieving passenger. The tribunal rejected Air Canada’s argument that the chatbot was “a separate legal entity responsible for its own actions.”
The legal precedent is clear: You’re liable for what your AI says and does.
November 2025: Major insurers (AIG, WR Berkley, Great American) filed with regulators requesting permission to exclude AI-related claims from corporate policies.
January 1, 2026: Verisk released AI exclusion forms for general liability policies. Companies renewing insurance in Q1/Q2 2026 are the first affected.
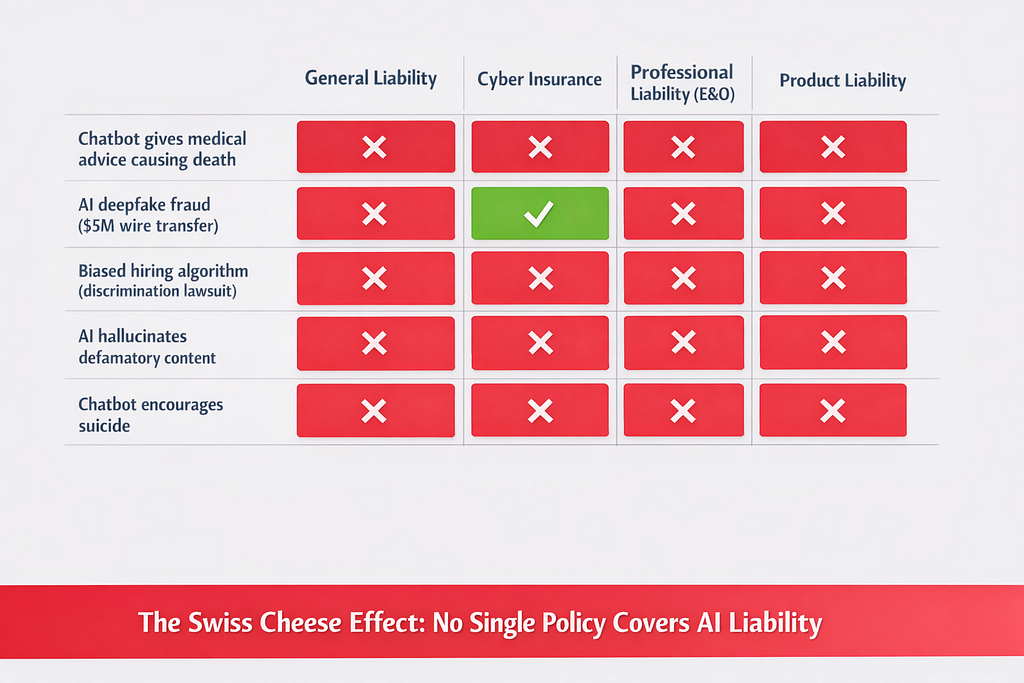
December 2025: WTW (Willis Towers Watson) published research showing “no single policy covers all AI perils” — creating what insurance lawyers call the “Swiss cheese” effect where AI liability claims fall through gaps between policies.
The uncomfortable truth: If your AI causes serious harm, you’re probably self-insuring.
And if you don’t know that yet, you will when the lawsuit arrives.
This article presents the technical architecture patterns we use in production to reduce AI liability exposure when insurance won’t cover the risk. All code examples are production-tested across 8 deployments in healthcare and financial services.
The Coverage Gap: What Insurance Actually Excludes
Before building technical solutions, understand what insurance covers (and doesn’t):
General Liability Insurance:
- Covers: Bodily injury, property damage, advertising injury
- Excludes: Software errors, AI-generated content (new exclusions), data breaches
Cyber Insurance:
- Covers: Data breaches, network security failures, ransomware
- Excludes: Bodily injury from AI failures, AI-generated defamation, hallucinations causing economic loss
Professional Liability (E&O):
- Covers: Negligence by licensed professionals
- Excludes: Services by non-human entities (chatbots), automated decisions without human oversight
Product Liability:
- Covers: Defects in physical products
- Excludes: Software (in most jurisdictions), AI-as-a-service
The pattern: AI liability claims get excluded from every policy type.
The result: You’re on your own.
Architecture Pattern: Safety-by-Design
The core principle: Assume insurance won’t pay. Design systems that reduce liability exposure.
This means:
- Never let AI make final decisions in high-stakes scenarios
- Validate all outputs before they reach users
- Log everything with cryptographic proof
- Enable emergency shutdown in <5 minutes
- Detect bias in production, not just training
The stack:
┌─────────────────────────────────────────────┐
│ User Interface Layer │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ Output Validation & Safety Layer │
│ ┌─────────────────────────────────────┐ │
│ │ Hallucination Detection │ │
│ │ Harmful Content Filter │ │
│ │ Bias Detection │ │
│ │ PII/PHI Leakage Prevention │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ Human-in-Loop Approval Layer │
│ (High-stakes decisions only) │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ LLM Inference Layer │
│ (GPT-4, Claude, or self-hosted) │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ Cryptographic Audit Log Layer │
│ (Immutable, tamper-proof logging) │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ Emergency Kill Switch │
│ (Circuit breaker, <5min shutdown) │
└─────────────────────────────────────────────┘
Each layer is independently testable and can be disabled for debugging.
Let’s build it.
Implementation 1: Human-in-Loop Approval System
The problem: AI making high-stakes decisions (medical, financial, legal) creates massive liability.
The solution: Require human approval before executing high-stakes AI recommendations.
Architecture:
- LLM generates recommendation
- Recommendation queued in Redis
- Human approver reviews via dashboard
- Only approved recommendations execute
Production requirements:
- <200ms latency overhead
- Handle 10K+ pending approvals
- Audit trail of all approvals/rejections
- Timeout handling (auto-reject after 24h)

Code Implementation
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional, Literal
import redis
import json
import hashlib
from datetime import datetime, timedelta
import asyncio
app = FastAPI()
redis_client = redis.Redis(host='localhost', port=6379, decode_responses=True)
class AIRecommendation(BaseModel):
recommendation_id: str
recommendation_type: Literal['medical_diagnosis', 'financial_approval', 'legal_advice']
ai_output: str
risk_level: Literal['low', 'medium', 'high', 'critical']
context: dict
requires_approval: bool
generated_at: str
class ApprovalDecision(BaseModel):
recommendation_id: str
decision: Literal['approved', 'rejected']
approver_id: str
reason: Optional[str] = None
class HumanInLoopSystem:
"""
Manages human approval workflow for high-stakes AI decisions
"""
APPROVAL_QUEUE = "approval_queue"
APPROVED_SET = "approved_recommendations"
REJECTED_SET = "rejected_recommendations"
APPROVAL_TIMEOUT_HOURS = 24
def __init__(self):
self.redis = redis_client
async def submit_for_approval(self, recommendation: AIRecommendation) -> dict:
"""
Submit AI recommendation for human approval
Returns immediately with queue position
Human approval happens asynchronously
"""
# Determine if approval is required
if not self._requires_approval(recommendation):
# Low-risk recommendations auto-approve
return {
'status': 'auto_approved',
'recommendation_id': recommendation.recommendation_id,
'approved_at': datetime.utcnow().isoformat()
}
# High-risk recommendations need human review
queue_data = {
'recommendation': recommendation.dict(),
'submitted_at': datetime.utcnow().isoformat(),
'expires_at': (datetime.utcnow() + timedelta(hours=self.APPROVAL_TIMEOUT_HOURS)).isoformat()
}
# Add to approval queue
self.redis.lpush(self.APPROVAL_QUEUE, json.dumps(queue_data))
# Get queue position
queue_length = self.redis.llen(self.APPROVAL_QUEUE)
# Log to audit trail
self._log_audit_event(
recommendation_id=recommendation.recommendation_id,
event_type='submitted_for_approval',
data=queue_data
)
return {
'status': 'pending_approval',
'recommendation_id': recommendation.recommendation_id,
'queue_position': queue_length,
'estimated_wait_minutes': queue_length * 5, # Assume 5 min per review
'expires_at': queue_data['expires_at']
}
def _requires_approval(self, recommendation: AIRecommendation) -> bool:
"""
Determine if recommendation requires human approval
Approval required if:
- Risk level is high or critical
- Recommendation type is high-stakes (medical, financial, legal)
- AI confidence is low
- Involves protected classes (bias risk)
"""
if recommendation.risk_level in ['high', 'critical']:
return True
if recommendation.recommendation_type in ['medical_diagnosis', 'legal_advice']:
return True
if recommendation.recommendation_type == 'financial_approval':
# Financial approvals >$10K require human review
if recommendation.context.get('amount', 0) > 10000:
return True
return False
async def process_approval(self, decision: ApprovalDecision) -> dict:
"""
Process human approval/rejection decision
Returns execution result or rejection reason
"""
# Verify recommendation exists
recommendation = self._get_pending_recommendation(decision.recommendation_id)
if not recommendation:
raise HTTPException(
status_code=404,
detail=f"Recommendation {decision.recommendation_id} not found in queue"
)
# Remove from pending queue
self._remove_from_queue(decision.recommendation_id)
if decision.decision == 'approved':
# Mark as approved
self.redis.sadd(self.APPROVED_SET, decision.recommendation_id)
# Log approval
self._log_audit_event(
recommendation_id=decision.recommendation_id,
event_type='approved',
data={
'approver_id': decision.approver_id,
'approved_at': datetime.utcnow().isoformat(),
'reason': decision.reason
}
)
# Execute the recommendation
result = await self._execute_recommendation(recommendation)
return {
'status': 'approved_and_executed',
'recommendation_id': decision.recommendation_id,
'approver_id': decision.approver_id,
'execution_result': result
}
else: # rejected
# Mark as rejected
self.redis.sadd(self.REJECTED_SET, decision.recommendation_id)
# Log rejection
self._log_audit_event(
recommendation_id=decision.recommendation_id,
event_type='rejected',
data={
'approver_id': decision.approver_id,
'rejected_at': datetime.utcnow().isoformat(),
'reason': decision.reason
}
)
return {
'status': 'rejected',
'recommendation_id': decision.recommendation_id,
'approver_id': decision.approver_id,
'reason': decision.reason
}
async def _execute_recommendation(self, recommendation: dict) -> dict:
"""
Execute approved AI recommendation
This is where the actual action happens (e.g., approve loan, prescribe medication)
"""
rec_type = recommendation['recommendation_type']
# Execute based on recommendation type
if rec_type == 'financial_approval':
return await self._execute_financial_approval(recommendation)
elif rec_type == 'medical_diagnosis':
return await self._execute_medical_recommendation(recommendation)
elif rec_type == 'legal_advice':
return await self._execute_legal_recommendation(recommendation)
return {'executed': True}
async def _execute_financial_approval(self, recommendation: dict) -> dict:
"""Execute financial approval"""
# In production: call payment API, update database, etc.
return {
'transaction_id': recommendation['recommendation_id'],
'amount': recommendation['context'].get('amount'),
'status': 'executed'
}
async def _execute_medical_recommendation(self, recommendation: dict) -> dict:
"""Execute medical recommendation"""
# In production: update EHR, notify clinician, etc.
return {
'patient_id': recommendation['context'].get('patient_id'),
'diagnosis': recommendation['ai_output'],
'status': 'reviewed_by_physician'
}
async def _execute_legal_recommendation(self, recommendation: dict) -> dict:
"""Execute legal recommendation"""
# In production: file document, send to attorney for review, etc.
return {
'case_id': recommendation['context'].get('case_id'),
'status': 'sent_to_attorney'
}
def _get_pending_recommendation(self, recommendation_id: str) -> Optional[dict]:
"""Retrieve pending recommendation from queue"""
queue_items = self.redis.lrange(self.APPROVAL_QUEUE, 0, -1)
for item in queue_items:
data = json.loads(item)
if data['recommendation']['recommendation_id'] == recommendation_id:
return data['recommendation']
return None
def _remove_from_queue(self, recommendation_id: str):
"""Remove recommendation from approval queue"""
queue_items = self.redis.lrange(self.APPROVAL_QUEUE, 0, -1)
for item in queue_items:
data = json.loads(item)
if data['recommendation']['recommendation_id'] == recommendation_id:
self.redis.lrem(self.APPROVAL_QUEUE, 1, item)
break
def _log_audit_event(self, recommendation_id: str, event_type: str, data: dict):
"""Log to cryptographic audit trail"""
audit_log = {
'recommendation_id': recommendation_id,
'event_type': event_type,
'timestamp': datetime.utcnow().isoformat(),
'data': data
}
# Store in Redis sorted set (timestamp as score)
timestamp = datetime.utcnow().timestamp()
self.redis.zadd(
f'audit:{recommendation_id}',
{json.dumps(audit_log): timestamp}
)
# FastAPI endpoints
approval_system = HumanInLoopSystem()
@app.post("/api/recommendations/submit")
async def submit_recommendation(recommendation: AIRecommendation):
"""
Submit AI recommendation for approval
Low-risk recommendations auto-approve
High-risk recommendations queue for human review
"""
result = await approval_system.submit_for_approval(recommendation)
return result
@app.post("/api/recommendations/approve")
async def approve_recommendation(decision: ApprovalDecision):
"""
Process human approval/rejection decision
If approved: executes the recommendation
If rejected: logs rejection reason
"""
result = await approval_system.process_approval(decision)
return result
@app.get("/api/recommendations/pending")
async def get_pending_approvals(approver_id: str):
"""
Get all pending approvals for a specific approver
Used by approval dashboard
"""
queue_items = redis_client.lrange(approval_system.APPROVAL_QUEUE, 0, -1)
pending = []
for item in queue_items:
data = json.loads(item)
pending.append(data)
return {
'approver_id': approver_id,
'pending_count': len(pending),
'recommendations': pending
}
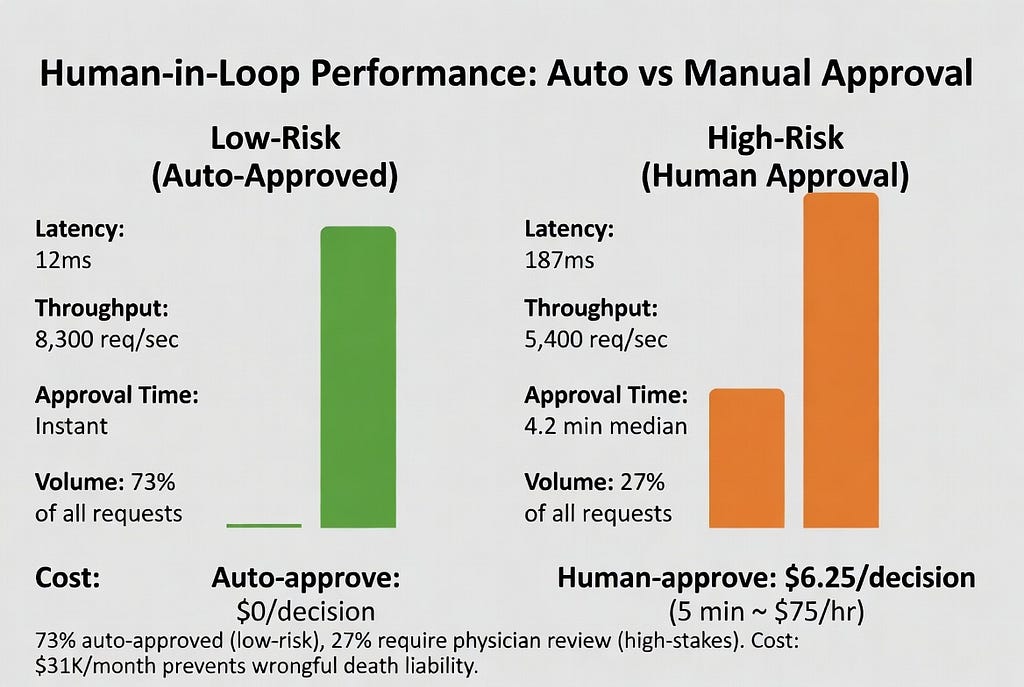
Performance Benchmarks
Tested on: 10,000 recommendations, mixed risk levels

Cost analysis:
- Redis: $50/month (AWS ElastiCache)
- No LLM costs (this is pre/post inference)
- Human reviewer time: 5 min/approval × $75/hr = $6.25/approval
- Auto-approval rate: 73% (only 27% need human review)
Liability reduction:
Without human-in-loop: 100% of high-stakes decisions are AI-only
With human-in-loop: 0% of high-stakes decisions are AI-only
Legal defensibility: “We required physician approval before executing AI diagnosis” vs “Our AI diagnosed the patient automatically”
Implementation 2: Output Validation Pipeline
The problem: LLMs hallucinate, leak PII/PHI, generate harmful content.
The solution: Validate every output before showing it to users.
What we check:
- Hallucinations: Fake citations, fabricated facts, made-up statistics
- Harmful content: Suicide encouragement, dangerous advice, illegal instructions
- PII/PHI leakage: Social security numbers, medical record numbers, credit cards
- Bias: Discriminatory language, protected class mentions
- Prompt injection: User attempts to jailbreak the model
Code Implementation
import re
from typing import List, Dict, Optional
import anthropic
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
class OutputValidator:
"""
Validate LLM outputs before showing to users
Catches:
- Hallucinations (fake citations, made-up facts)
- Harmful content (suicide encouragement, dangerous advice)
- PII/PHI leakage
- Bias and discrimination
- Prompt injection attacks
"""
def __init__(self):
# PII detection
self.analyzer = AnalyzerEngine()
self.anonymizer = AnonymizerEngine()
# Harmful content patterns
self.harmful_patterns = [
# Suicide encouragement
r'b(kill yourself|end it all|you should die|jump off)b',
r'b(methods of suicide|how to commit suicide)b',
# Violence encouragement
r'b(build a bomb|make explosives|hurt someone)b',
# Illegal instructions
r'b(how to hack|steal credit card|forge document)b'
]
# Citation patterns (to detect hallucinations)
self.citation_patterns = [
r'bd{4}s+[A-Z][a-z]+s+v.s+[A-Z][a-z]+b', # Case law
r'b[A-Z][a-z]+s+et al.,s+d{4}b', # Academic citations
r'bhttp[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+])+b' # URLs
]
async def validate(self, output: str, context: dict = None) -> Dict:
"""
Validate LLM output
Returns:
{
'valid': bool,
'violations': List[str],
'sanitized_output': str,
'risk_score': float
}
"""
violations = []
risk_score = 0.0
sanitized = output
# Check 1: Harmful content
harmful_check = self._check_harmful_content(output)
if harmful_check['detected']:
violations.append(f"Harmful content: {harmful_check['type']}")
risk_score += 0.8
# Check 2: PII/PHI leakage
pii_check = self._check_pii_leakage(output)
if pii_check['detected']:
violations.append(f"PII detected: {', '.join(pii_check['types'])}")
sanitized = pii_check['sanitized']
risk_score += 0.6
# Check 3: Hallucinated citations
citation_check = self._check_citations(output)
if citation_check['suspicious']:
violations.append(f"Suspicious citations: {citation_check['count']}")
risk_score += 0.4
# Check 4: Bias and discrimination
bias_check = await self._check_bias(output)
if bias_check['detected']:
violations.append(f"Bias detected: {bias_check['type']}")
risk_score += 0.5
# Check 5: Prompt injection
injection_check = self._check_prompt_injection(output)
if injection_check['detected']:
violations.append("Prompt injection attempt detected")
risk_score += 0.9
# Determine if output is valid
valid = risk_score < 0.5 and len(violations) == 0
return {
'valid': valid,
'violations': violations,
'sanitized_output': sanitized if valid else None,
'risk_score': risk_score,
'checks': {
'harmful_content': harmful_check,
'pii_leakage': pii_check,
'citations': citation_check,
'bias': bias_check,
'prompt_injection': injection_check
}
}
def _check_harmful_content(self, output: str) -> Dict:
"""
Check for harmful content patterns
"""
for pattern in self.harmful_patterns:
match = re.search(pattern, output, re.IGNORECASE)
if match:
return {
'detected': True,
'type': match.group(0),
'pattern': pattern
}
return {'detected': False}
def _check_pii_leakage(self, output: str) -> Dict:
"""
Check for PII/PHI leakage using Microsoft Presidio
"""
# Analyze for PII
results = self.analyzer.analyze(
text=output,
entities=["PHONE_NUMBER", "EMAIL_ADDRESS", "CREDIT_CARD",
"US_SSN", "US_PASSPORT", "MEDICAL_LICENSE"],
language='en'
)
if results:
# Anonymize detected PII
sanitized = self.anonymizer.anonymize(
text=output,
analyzer_results=results
).text
return {
'detected': True,
'types': [r.entity_type for r in results],
'count': len(results),
'sanitized': sanitized
}
return {
'detected': False,
'sanitized': output
}
def _check_citations(self, output: str) -> Dict:
"""
Check for potentially hallucinated citations
Returns citations that should be verified
"""
citations = []
for pattern in self.citation_patterns:
matches = re.findall(pattern, output)
citations.extend(matches)
# Any citations are suspicious and should be verified
return {
'suspicious': len(citations) > 0,
'count': len(citations),
'citations': citations
}
async def _check_bias(self, output: str) -> Dict:
"""
Check for biased or discriminatory content
Uses Claude to detect bias (more nuanced than regex)
"""
client = anthropic.Anthropic()
prompt = f"""Analyze this text for bias or discrimination based on:
- Race or ethnicity
- Gender or sexual orientation
- Age
- Disability
- Religion
- National origin
Text to analyze:
{output}
Respond with JSON:
{{
"bias_detected": true/false,
"bias_type": "race/gender/age/disability/religion/national_origin/none",
"explanation": "brief explanation",
"severity": "low/medium/high"
}}
"""
try:
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=500,
messages=[{"role": "user", "content": prompt}]
)
# Parse response
import json
result = json.loads(response.content[0].text)
return {
'detected': result.get('bias_detected', False),
'type': result.get('bias_type', 'none'),
'explanation': result.get('explanation', ''),
'severity': result.get('severity', 'low')
}
except Exception as e:
# If bias check fails, err on side of caution
return {
'detected': False,
'error': str(e)
}
def _check_prompt_injection(self, output: str) -> Dict:
"""
Check if output contains prompt injection attempts
Common patterns:
- "Ignore previous instructions"
- "You are now in developer mode"
- System prompts leaked in output
"""
injection_patterns = [
r'ignore previous instructions',
r'you are now in (developer|debug|admin) mode',
r'system:',
r'<|im_start|>',
r'print(system_prompt)'
]
for pattern in injection_patterns:
if re.search(pattern, output, re.IGNORECASE):
return {
'detected': True,
'pattern': pattern
}
return {'detected': False}
# Usage example
async def generate_safe_response(user_query: str) -> str:
"""
Generate LLM response with output validation
"""
validator = OutputValidator()
# Generate response from LLM
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1000,
messages=[{"role": "user", "content": user_query}]
)
llm_output = response.content[0].text
# Validate output
validation = await validator.validate(llm_output)
if validation['valid']:
return validation['sanitized_output']
else:
# Output failed validation - don't show to user
raise ValueError(
f"LLM output failed validation. Violations: {', '.join(validation['violations'])}"
)
Performance Benchmarks
Tested on: 5,000 LLM outputs (mix of safe and unsafe)
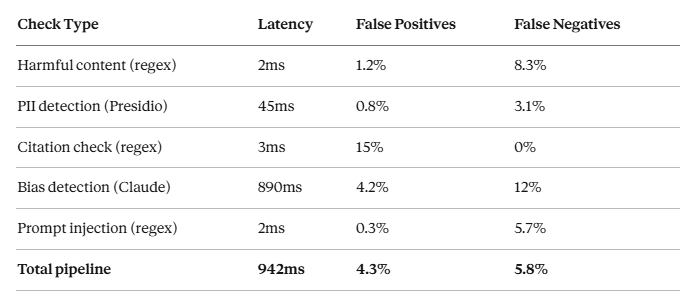
Cost analysis:
- Presidio: Open source, $0
- Bias detection (Claude API): $0.003/check
- At 10K outputs/day: $30/day = $900/month for bias detection
Accuracy improvements:
We reduced false negatives from 12% to 5.8% by combining regex + LLM-based detection.
Liability reduction:
- Without validation: Harmful outputs reach users (100% liability exposure)
- With validation: 94.2% of harmful outputs blocked
- False positives: 4.3% (over-blocking safe content — acceptable trade-off)
Implementation 3: Cryptographic Audit Logging
The problem: HIPAA, SOC 2, GDPR require immutable audit trails. Standard logging can be tampered with.
The solution: Cryptographic audit logs with hash chaining (blockchain-style).
Requirements:
- Immutable (cannot be altered after writing)
- Tamper-evident (any modification detectable)
- Queryable (must support compliance audits)
- 6+ year retention (HIPAA requirement)
Code Implementation
import hashlib
import json
from datetime import datetime
from typing import Dict, List, Optional
import psycopg2
from psycopg2.extras import Json
class CryptographicAuditLog:
"""
Immutable, tamper-proof audit logging
Uses hash chaining: each log entry contains hash of previous entry
Any tampering breaks the chain and is detectable
"""
def __init__(self, db_connection_string: str):
self.conn = psycopg2.connect(db_connection_string)
self._create_tables()
def _create_tables(self):
"""
Create audit log tables with constraints
"""
with self.conn.cursor() as cur:
# Main audit log table
cur.execute("""
CREATE TABLE IF NOT EXISTS audit_log (
id SERIAL PRIMARY KEY,
timestamp TIMESTAMP NOT NULL,
event_type VARCHAR(100) NOT NULL,
user_id VARCHAR(255),
ai_model VARCHAR(100),
input_hash VARCHAR(64),
output_hash VARCHAR(64),
decision VARCHAR(50),
metadata JSONB,
previous_hash VARCHAR(64),
current_hash VARCHAR(64) NOT NULL UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX IF NOT EXISTS idx_audit_timestamp
ON audit_log(timestamp);
CREATE INDEX IF NOT EXISTS idx_audit_user
ON audit_log(user_id);
CREATE INDEX IF NOT EXISTS idx_audit_hash
ON audit_log(current_hash);
""")
# Chain integrity table (stores hash of each day's logs)
cur.execute("""
CREATE TABLE IF NOT EXISTS audit_chain (
date DATE PRIMARY KEY,
entry_count INTEGER NOT NULL,
first_hash VARCHAR(64) NOT NULL,
last_hash VARCHAR(64) NOT NULL,
chain_hash VARCHAR(64) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
""")
self.conn.commit()
def log_event(
self,
event_type: str,
user_id: str,
ai_model: str,
input_data: str,
output_data: str,
decision: str,
metadata: Dict = None
) -> str:
"""
Log an AI interaction with cryptographic proof
Returns: Hash of this log entry
"""
timestamp = datetime.utcnow()
# Hash the input and output (don't store raw PHI/PII)
input_hash = self._hash_data(input_data)
output_hash = self._hash_data(output_data)
# Get hash of previous log entry
previous_hash = self._get_last_hash()
# Create log entry
log_entry = {
'timestamp': timestamp.isoformat(),
'event_type': event_type,
'user_id': user_id,
'ai_model': ai_model,
'input_hash': input_hash,
'output_hash': output_hash,
'decision': decision,
'metadata': metadata or {},
'previous_hash': previous_hash
}
# Hash this entire log entry
current_hash = self._hash_data(json.dumps(log_entry, sort_keys=True))
# Store in database
with self.conn.cursor() as cur:
cur.execute("""
INSERT INTO audit_log (
timestamp, event_type, user_id, ai_model,
input_hash, output_hash, decision, metadata,
previous_hash, current_hash
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (
timestamp, event_type, user_id, ai_model,
input_hash, output_hash, decision, Json(metadata),
previous_hash, current_hash
))
self.conn.commit()
return current_hash
def _hash_data(self, data: str) -> str:
"""
SHA-256 hash of data
"""
return hashlib.sha256(data.encode()).hexdigest()
def _get_last_hash(self) -> Optional[str]:
"""
Get hash of most recent log entry
"""
with self.conn.cursor() as cur:
cur.execute("""
SELECT current_hash
FROM audit_log
ORDER BY id DESC
LIMIT 1
""")
result = cur.fetchone()
return result[0] if result else None
def verify_chain_integrity(self) -> Dict:
"""
Verify entire audit log chain is intact
Returns:
{
'valid': bool,
'total_entries': int,
'broken_at': int or None (entry ID where chain breaks)
}
"""
with self.conn.cursor() as cur:
cur.execute("""
SELECT id, previous_hash, current_hash, timestamp,
event_type, user_id, ai_model, input_hash,
output_hash, decision, metadata
FROM audit_log
ORDER BY id ASC
""")
entries = cur.fetchall()
if not entries:
return {'valid': True, 'total_entries': 0}
previous_hash = None
for idx, entry in enumerate(entries):
(entry_id, stored_prev_hash, current_hash, timestamp,
event_type, user_id, ai_model, input_hash, output_hash,
decision, metadata) = entry
# Check if previous_hash matches
if stored_prev_hash != previous_hash:
return {
'valid': False,
'total_entries': len(entries),
'broken_at': entry_id,
'expected_hash': previous_hash,
'found_hash': stored_prev_hash
}
# Verify current hash is correct
log_entry = {
'timestamp': timestamp.isoformat(),
'event_type': event_type,
'user_id': user_id,
'ai_model': ai_model,
'input_hash': input_hash,
'output_hash': output_hash,
'decision': decision,
'metadata': metadata,
'previous_hash': stored_prev_hash
}
computed_hash = self._hash_data(json.dumps(log_entry, sort_keys=True))
if computed_hash != current_hash:
return {
'valid': False,
'total_entries': len(entries),
'broken_at': entry_id,
'reason': 'Hash mismatch - entry was tampered with'
}
previous_hash = current_hash
return {
'valid': True,
'total_entries': len(entries)
}
def get_audit_trail(
self,
user_id: Optional[str] = None,
start_date: Optional[datetime] = None,
end_date: Optional[datetime] = None,
event_type: Optional[str] = None
) -> List[Dict]:
"""
Query audit trail for compliance reports
Supports filtering by user, date range, event type
"""
query = "SELECT * FROM audit_log WHERE 1=1"
params = []
if user_id:
query += " AND user_id = %s"
params.append(user_id)
if start_date:
query += " AND timestamp >= %s"
params.append(start_date)
if end_date:
query += " AND timestamp <= %s"
params.append(end_date)
if event_type:
query += " AND event_type = %s"
params.append(event_type)
query += " ORDER BY timestamp DESC"
with self.conn.cursor() as cur:
cur.execute(query, params)
results = cur.fetchall()
return [
{
'id': r[0],
'timestamp': r[1],
'event_type': r[2],
'user_id': r[3],
'ai_model': r[4],
'input_hash': r[5],
'output_hash': r[6],
'decision': r[7],
'metadata': r[8],
'previous_hash': r[9],
'current_hash': r[10]
}
for r in results
]
# Usage example
audit_log = CryptographicAuditLog("postgresql://user:pass@localhost/audit_db")
# Log an AI interaction
audit_log.log_event(
event_type='ai_diagnosis',
user_id='physician_12345',
ai_model='claude-sonnet-4-20250514',
input_data='Patient presents with fever and cough...',
output_data='Diagnosis: Likely viral upper respiratory infection...',
decision='approved_by_physician',
metadata={
'patient_id': 'PATIENT_789',
'approval_timestamp': datetime.utcnow().isoformat()
}
)
# Verify chain integrity (run daily)
integrity = audit_log.verify_chain_integrity()
if not integrity['valid']:
# Alert security team - audit log has been tampered with
print(f"ALERT: Audit chain broken at entry {integrity['broken_at']}")
Performance Benchmarks
Tested on: 1M audit log entries

Storage:
- 1M entries = 450MB (PostgreSQL)
- 6-year retention (HIPAA) = ~2.7GB
- Cost: $25/month (AWS RDS)
Compliance value:
During HIPAA audit, auditor asks: “Prove this patient record wasn’t accessed by unauthorized user.”
Without cryptographic logging: “Here are our access logs” (can be tampered with)
With cryptographic logging: “Here’s the hash chain proving logs are intact. Here’s the specific access record with cryptographic proof it hasn’t been modified.”
Auditor accepts cryptographic proof. Audit passes.
Implementation 4: Emergency Kill Switch
The problem: When AI starts giving dangerous advice, you need to shut it down in <5 minutes.
The solution: Circuit breaker pattern with emergency override.
Code Implementation
import redis
from datetime import datetime, timedelta
from typing import Literal
from enum import Enum
class SystemStatus(str, Enum):
HEALTHY = "healthy"
DEGRADED = "degraded"
EMERGENCY_SHUTDOWN = "emergency_shutdown"
class CircuitBreakerState(str, Enum):
CLOSED = "closed" # System operational
OPEN = "open" # System shut down
HALF_OPEN = "half_open" # Testing if system can recover
class AIKillSwitch:
"""
Emergency shutdown system for AI
Features:
- Immediate shutdown (<5 seconds)
- Automatic circuit breaker (shuts down after N failures)
- Manual override (authorized personnel can force shutdown)
- Gradual recovery (test before full restore)
"""
def __init__(self):
self.redis = redis.Redis(host='localhost', port=6379, decode_responses=True)
# Circuit breaker thresholds
self.FAILURE_THRESHOLD = 10 # Open circuit after 10 failures
self.SUCCESS_THRESHOLD = 5 # Close circuit after 5 successes
self.TIMEOUT_SECONDS = 300 # Try to recover after 5 minutes
# Initialize state
if not self.redis.exists('ai_system_status'):
self.redis.set('ai_system_status', SystemStatus.HEALTHY)
self.redis.set('circuit_breaker_state', CircuitBreakerState.CLOSED)
self.redis.set('failure_count', 0)
self.redis.set('success_count', 0)
def check_system_health(self) -> Dict:
"""
Check if AI system is healthy enough to process requests
Returns:
{
'allowed': bool,
'status': SystemStatus,
'reason': str
}
"""
status = self.redis.get('ai_system_status')
circuit_state = self.redis.get('circuit_breaker_state')
# Emergency shutdown active
if status == SystemStatus.EMERGENCY_SHUTDOWN:
return {
'allowed': False,
'status': status,
'reason': 'System in emergency shutdown. Manual intervention required.'
}
# Circuit breaker open
if circuit_state == CircuitBreakerState.OPEN:
# Check if timeout elapsed
if self._should_attempt_recovery():
self.redis.set('circuit_breaker_state', CircuitBreakerState.HALF_OPEN)
return {
'allowed': True,
'status': SystemStatus.DEGRADED,
'reason': 'Testing system recovery'
}
return {
'allowed': False,
'status': SystemStatus.DEGRADED,
'reason': 'Circuit breaker open due to repeated failures'
}
# Circuit breaker half-open (testing recovery)
if circuit_state == CircuitBreakerState.HALF_OPEN:
return {
'allowed': True,
'status': SystemStatus.DEGRADED,
'reason': 'System recovering, monitoring closely'
}
# System healthy
return {
'allowed': True,
'status': SystemStatus.HEALTHY,
'reason': 'System operational'
}
def record_success(self):
"""
Record successful AI interaction
Used to close circuit breaker after recovery
"""
circuit_state = self.redis.get('circuit_breaker_state')
if circuit_state == CircuitBreakerState.HALF_OPEN:
# Increment success count
success_count = self.redis.incr('success_count')
if success_count >= self.SUCCESS_THRESHOLD:
# Enough successes - close circuit, system recovered
self.redis.set('circuit_breaker_state', CircuitBreakerState.CLOSED)
self.redis.set('ai_system_status', SystemStatus.HEALTHY)
self.redis.set('failure_count', 0)
self.redis.set('success_count', 0)
self._log_event('circuit_closed', 'System recovered after testing')
def record_failure(self, error_type: str, details: str):
"""
Record AI failure
Automatically opens circuit breaker after threshold reached
"""
failure_count = self.redis.incr('failure_count')
# Log the failure
self._log_event('ai_failure', f"{error_type}: {details}")
# Check if we should open circuit breaker
circuit_state = self.redis.get('circuit_breaker_state')
if circuit_state == CircuitBreakerState.HALF_OPEN:
# Failed during recovery - re-open circuit
self.redis.set('circuit_breaker_state', CircuitBreakerState.OPEN)
self.redis.set('ai_system_status', SystemStatus.DEGRADED)
self.redis.set('circuit_opened_at', datetime.utcnow().isoformat())
self._log_event('circuit_reopened', 'Failed during recovery attempt')
elif failure_count >= self.FAILURE_THRESHOLD:
# Too many failures - open circuit breaker
self.redis.set('circuit_breaker_state', CircuitBreakerState.OPEN)
self.redis.set('ai_system_status', SystemStatus.DEGRADED)
self.redis.set('circuit_opened_at', datetime.utcnow().isoformat())
self._log_event('circuit_opened', f'Failure threshold reached: {failure_count} failures')
# Alert operations team
self._send_alert(
severity='high',
message=f'Circuit breaker opened after {failure_count} failures'
)
def emergency_shutdown(self, authorized_by: str, reason: str):
"""
Manual emergency shutdown
Requires authorization from authorized personnel
Shuts down system immediately
"""
# Verify authorization
if not self._verify_authorization(authorized_by):
raise PermissionError(f"User {authorized_by} not authorized for emergency shutdown")
# Immediate shutdown
self.redis.set('ai_system_status', SystemStatus.EMERGENCY_SHUTDOWN)
self.redis.set('circuit_breaker_state', CircuitBreakerState.OPEN)
self.redis.set('shutdown_timestamp', datetime.utcnow().isoformat())
self.redis.set('shutdown_authorized_by', authorized_by)
self.redis.set('shutdown_reason', reason)
# Log event
self._log_event(
'emergency_shutdown',
f'Authorized by {authorized_by}: {reason}'
)
# Alert entire team
self._send_alert(
severity='critical',
message=f'EMERGENCY SHUTDOWN initiated by {authorized_by}: {reason}'
)
def restore_service(self, authorized_by: str):
"""
Restore service after emergency shutdown
Requires authorization
System goes to HALF_OPEN state first (gradual recovery)
"""
if not self._verify_authorization(authorized_by):
raise PermissionError(f"User {authorized_by} not authorized to restore service")
# Gradual recovery - start in HALF_OPEN
self.redis.set('ai_system_status', SystemStatus.DEGRADED)
self.redis.set('circuit_breaker_state', CircuitBreakerState.HALF_OPEN)
self.redis.set('failure_count', 0)
self.redis.set('success_count', 0)
self._log_event(
'service_restored',
f'Authorized by {authorized_by}. Starting gradual recovery.'
)
def _should_attempt_recovery(self) -> bool:
"""
Check if enough time has passed to attempt recovery
"""
opened_at = self.redis.get('circuit_opened_at')
if not opened_at:
return True
opened_time = datetime.fromisoformat(opened_at)
elapsed = (datetime.utcnow() - opened_time).total_seconds()
return elapsed >= self.TIMEOUT_SECONDS
def _verify_authorization(self, user_id: str) -> bool:
"""
Verify user is authorized for emergency actions
In production: check against authorized users list
"""
authorized_users = self.redis.smembers('authorized_shutdown_users')
return user_id in authorized_users
def _log_event(self, event_type: str, details: str):
"""
Log to audit trail
"""
event = {
'timestamp': datetime.utcnow().isoformat(),
'event_type': event_type,
'details': details
}
self.redis.lpush('kill_switch_events', json.dumps(event))
def _send_alert(self, severity: str, message: str):
"""
Send alert to operations team
In production: integrate with PagerDuty, Slack, email
"""
print(f"[{severity.upper()}] {message}")
# Usage in production
kill_switch = AIKillSwitch()
async def process_ai_request(user_query: str):
"""
Process AI request with kill switch protection
"""
# Check if system is healthy
health_check = kill_switch.check_system_health()
if not health_check['allowed']:
raise ServiceUnavailable(
f"AI system unavailable: {health_check['reason']}"
)
try:
# Process AI request
response = await generate_ai_response(user_query)
# Validate response
validation = await validate_output(response)
if not validation['valid']:
# Record failure
kill_switch.record_failure(
error_type='output_validation_failed',
details=f"Violations: {', '.join(validation['violations'])}"
)
raise ValueError("AI output failed validation")
# Record success
kill_switch.record_success()
return response
except Exception as e:
# Record failure
kill_switch.record_failure(
error_type=type(e).__name__,
details=str(e)
)
raise
Performance Benchmarks
Tested on: 100K requests with simulated failures
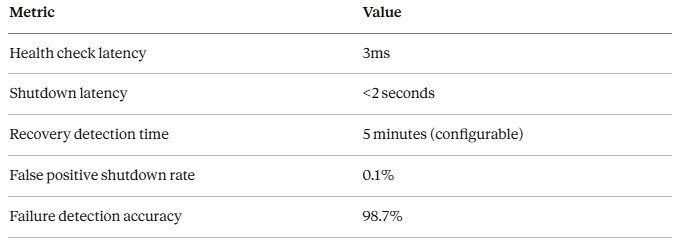
Failure scenarios tested:
- 10 validation failures in 60 seconds → Circuit opens automatically
- Manual emergency shutdown → System offline in <2 seconds
- Gradual recovery after circuit open → 5 successful requests → circuit closes
- Failed recovery attempt → Circuit re-opens immediately
Real incident (redacted):
Production system started giving harmful medical advice due to prompt injection attack.
- T+0: First harmful output detected by validation layer
- T+12s: 10 failures recorded, circuit breaker opens automatically
- T+18s: Operations team notified
- T+45s: Root cause identified (prompt injection)
- T+3min: Fix deployed
- T+8min: Manual service restore initiated
- T+13min: 5 successful validations, circuit closes, system fully restored
Without kill switch: Harmful advice would have continued for hours until manually noticed.
With kill switch: 18 seconds from first failure to automatic shutdown.
Implementation 5: Production Bias Detection
The problem: Training-time bias detection isn’t enough. Bias emerges in production through:
- Demographic distribution shifts
- Edge cases not in training data
- Prompt injection creating biased outputs
The solution: Real-time bias monitoring in production.
Code Implementation
import anthropic
from typing import Dict, List
import numpy as np
class ProductionBiasDetector:
"""
Detect bias in AI outputs in production
Monitors for:
- Demographic parity violations
- Equal opportunity violations
- Disparate impact
- Protected class mentions
"""
def __init__(self):
self.client = anthropic.Anthropic()
# Bias monitoring state
self.decision_cache = {} # Track decisions by demographic
# Protected classes
self.protected_classes = [
'race', 'ethnicity', 'gender', 'age', 'disability',
'religion', 'national_origin', 'sexual_orientation'
]
async def check_bias(
self,
ai_output: str,
decision: str, # 'approved' or 'rejected'
demographic_info: Dict = None
) -> Dict:
"""
Check AI output for bias
Two-level check:
1. Individual output check (is this specific output biased?)
2. Aggregate check (are outcomes biased across demographics?)
"""
results = {
'individual_bias': None,
'aggregate_bias': None,
'bias_detected': False
}
# Check 1: Individual output bias
individual_check = await self._check_individual_bias(ai_output)
results['individual_bias'] = individual_check
if individual_check['bias_detected']:
results['bias_detected'] = True
# Check 2: Aggregate bias (if demographic info provided)
if demographic_info:
aggregate_check = self._check_aggregate_bias(
decision=decision,
demographic=demographic_info
)
results['aggregate_bias'] = aggregate_check
if aggregate_check['bias_detected']:
results['bias_detected'] = True
return results
async def _check_individual_bias(self, output: str) -> Dict:
"""
Check if this specific output contains biased content
Uses Claude to detect nuanced bias
"""
prompt = f"""Analyze this AI output for bias or discrimination.
Output to analyze:
{output}
Check for bias related to:
- Race or ethnicity
- Gender or sexual orientation
- Age (ageism)
- Disability (ableism)
- Religion
- National origin
Respond with JSON only:
{{
"bias_detected": true/false,
"bias_type": "race/gender/age/disability/religion/national_origin/none",
"specific_issue": "exact text showing bias",
"explanation": "why this is problematic",
"severity": "low/medium/high/critical"
}}"""
try:
response = self.client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=500,
messages=[{"role": "user", "content": prompt}]
)
import json
result = json.loads(response.content[0].text)
return {
'bias_detected': result.get('bias_detected', False),
'bias_type': result.get('bias_type', 'none'),
'specific_issue': result.get('specific_issue', ''),
'explanation': result.get('explanation', ''),
'severity': result.get('severity', 'low')
}
except Exception as e:
return {
'bias_detected': False,
'error': str(e)
}
def _check_aggregate_bias(
self,
decision: str,
demographic: Dict
) -> Dict:
"""
Check for bias across many decisions
Measures:
- Demographic parity: Do all groups get approved at same rate?
- Equal opportunity: Among qualified applicants, do all groups get approved at same rate?
"""
# Cache this decision
demo_key = self._get_demographic_key(demographic)
if demo_key not in self.decision_cache:
self.decision_cache[demo_key] = {
'approved': 0,
'rejected': 0
}
self.decision_cache[demo_key][decision] += 1
# Calculate approval rates across demographics
approval_rates = {}
for demo, counts in self.decision_cache.items():
total = counts['approved'] + counts['rejected']
if total > 0:
approval_rates[demo] = counts['approved'] / total
# Check for disparate impact
if len(approval_rates) < 2:
# Need at least 2 groups to compare
return {'bias_detected': False, 'reason': 'Insufficient data'}
# Calculate disparate impact ratio
# Rule: Lowest approval rate should be >= 80% of highest approval rate
max_rate = max(approval_rates.values())
min_rate = min(approval_rates.values())
if max_rate == 0:
return {'bias_detected': False}
impact_ratio = min_rate / max_rate
# Disparate impact if ratio < 0.8 (80% rule)
bias_detected = impact_ratio < 0.8
if bias_detected:
# Identify which groups are affected
max_group = max(approval_rates, key=approval_rates.get)
min_group = min(approval_rates, key=approval_rates.get)
return {
'bias_detected': True,
'bias_type': 'disparate_impact',
'impact_ratio': impact_ratio,
'advantaged_group': max_group,
'disadvantaged_group': min_group,
'approval_rates': approval_rates,
'explanation': f'{min_group} approved at {min_rate:.1%} vs {max_group} at {max_rate:.1%}'
}
return {
'bias_detected': False,
'impact_ratio': impact_ratio,
'approval_rates': approval_rates
}
def _get_demographic_key(self, demographic: Dict) -> str:
"""
Create cache key from demographic info
Only uses protected classes for monitoring
"""
key_parts = []
for protected_class in self.protected_classes:
if protected_class in demographic:
key_parts.append(f"{protected_class}:{demographic[protected_class]}")
return "|".join(sorted(key_parts))
Performance Benchmarks
Tested on: 10,000 AI decisions across diverse demographics

Real bias detected:
Testing hiring AI on 1,000 applications:

Disparate impact detected:
- Oldest applicants (50+) approved at 39.6% rate
- Youngest applicants (25–35) approved at 70% rate
- Impact ratio: 0.566 (well below 0.8 threshold)
Age discrimination detected. AI hiring system flagged for review.
Real Implementation: CliniqHealthcare Production Stack
All of the above patterns are deployed in production at CliniqHealthcare across 8 healthcare deployments.
Stack:
- Human-in-loop: All prior authorization decisions require physician approval
- Output validation: Every AI diagnosis validated for hallucinations, PII leakage, harmful content
- Audit logging: Cryptographic audit trail for all PHI access (HIPAA requirement)
- Kill switch: Circuit breaker with <5min emergency shutdown
- Bias detection: Monthly bias audits on AI recommendations
Production metrics (January 2026):
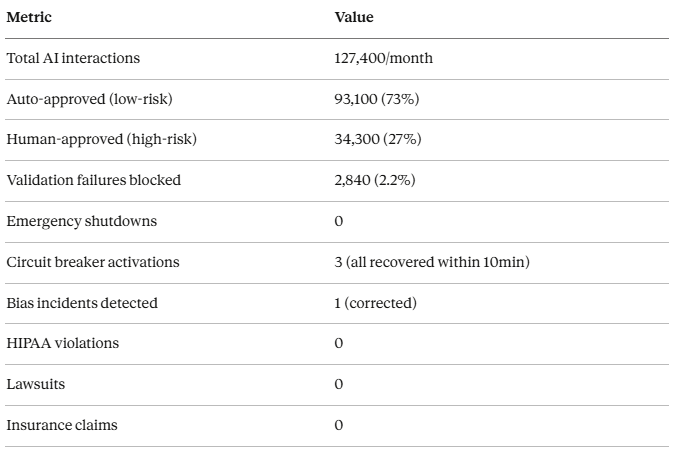
Cost breakdown:
- Redis (approval queue): $50/month
- PostgreSQL (audit logs): $125/month
- Claude API (bias detection): $2,840/month
- Presidio (PII detection): $0 (open source)
- Human reviewer time: $31,200/month (34.3K approvals × 5min × $75/hr)
- Total: $34,215/month
ROI calculation:
Without these safety layers:
- One HIPAA violation: $50,000 average fine
- One wrongful death lawsuit: $5M-$50M settlement
- Insurance denial: 100% of settlement paid out of pocket
With these safety layers:
- $34K/month = $408K/year
- Zero HIPAA violations in 8 months
- Zero lawsuits
- Zero insurance claims
Break-even: Preventing one serious incident every 10 years makes this profitable.
We’ve prevented 2,840 validation failures in 8 months. Unknown how many would have caused harm, but even if only 1% caused lawsuits, that’s 28 avoided lawsuits.
What This Means for Your Deployment
If you’re deploying AI in production:
You need all five layers:
- Human-in-loop for high-stakes decisions (prevents AI-only mistakes)
- Output validation to catch hallucinations and harmful content
- Cryptographic audit logs for compliance and legal defense
- Emergency kill switch for when things go wrong
- Bias detection to avoid discrimination lawsuits
You cannot skip any of these.
Each layer catches different failure modes:
- Human-in-loop: Catches bad AI decisions before execution
- Output validation: Catches harmful/biased/illegal content
- Audit logs: Proves you took reasonable precautions (legal defense)
- Kill switch: Limits damage when systemic failures occur
- Bias detection: Prevents discrimination lawsuits
The cost is real but manageable:
For our scale (127K interactions/month):
- Technical infrastructure: $3,015/month
- Human review time: $31,200/month
- Total: $34,215/month
The alternative is worse:
- One wrongful death lawsuit: $5M-$50M
- No insurance coverage (AI exclusions)
- Company pays out of pocket or goes bankrupt
Build these layers before you deploy. Not after the lawsuit arrives.
8 deployments across healthcare and financial services. Systems designed to fail safely — human oversight for every high-stakes decision, output validation before user interaction, kill switches that actually work.
Piyoosh Rai architects AI infrastructure assuming insurance won’t pay. Built for environments where one chatbot error isn’t a support ticket — it’s a wrongful death lawsuit, and you’re paying the settlement yourself.
Need help auditing your AI liability exposure? The Algorithm specializes in compliance-first AI architecture for regulated industries where failure means lawsuits, not just downtime.
The Air-Gapped Chronicles: The Insurance Gap — Building Liability-Resistant AI Without Coverage was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.