
Prompt to Protocol: Architecting Agent-Oriented Infrastructure for Production LLMs
The “Chatbot Era” is dead. Here is how to navigate the microservices moment for AI and choose between LangGraph and AutoGen.
If you’ve spent the last few years building AI applications, you’ve probably hit the same wall I did.
About a year ago, my team was trying to scale a complex Retrieval-Augmented Generation (RAG) pipeline for a heavy-duty enterprise client. We spent weeks agonizing over prompt engineering, tweaking hyperparameters, and stuffing context windows. The flow was entirely linear: Input -> Retrieve -> Generate -> Output.
It worked beautifully in our notebooks. But in production? It was a nightmare.
Because LLMs are inherently stochastic, if the model hallucinated or dropped context at step three of a five-step DAG (Directed Acyclic Graph), the entire pipeline failed. There was no recovery mechanism. It became painfully obvious that prompts are not infrastructure.
We are currently living through what industry analysts are calling the “Microservices Moment” for AI. We are shifting away from probabilistic token generation toward deterministic workflow orchestration. We are moving from single, monolithic prompts to Agent-Oriented Infrastructure.
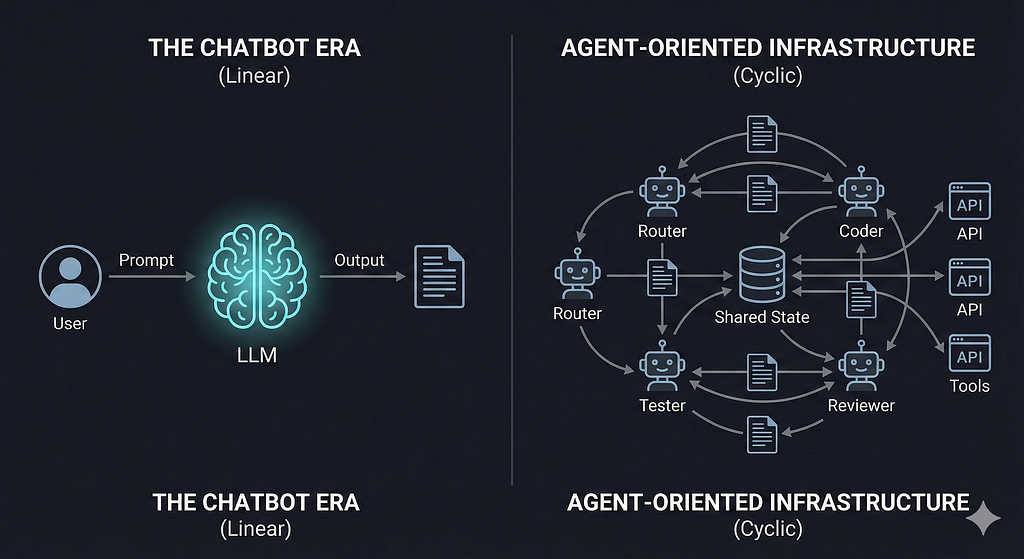
But when it comes time to actually build these cyclic, self-correcting systems, you run into the big architectural dilemma of 2026: How do you orchestrate them?
Having spent the last 8 years in distributed systems and the last few deep in LLM orchestration, I want to break down the two dominant paradigms right now i.e. Microsoft’s AutoGen and LangChain’s LangGraph, and how to think about them for production.
The Conversational Paradigm: AutoGen
AutoGen approaches multi-agent workflows through the lens of human-like conversation. Instead of defining strict programmatic paths, you define “Personas” (agents) and let them talk to each other to solve a problem.
It uses a message-passing architecture. You might set up a UserProxyAgent (acting on your behalf to execute code) and an AssistantAgent (writing the code).

from autogen import AssistantAgent, UserProxyAgent
# Defining the conversational agents
coder = AssistantAgent(
name="Senior_Developer",
llm_config={"model": "gpt-4o"}
)
executor = UserProxyAgent(
name="Code_Executor",
human_input_mode="NEVER",
code_execution_config={"work_dir": "build_dir"}
)
# Kicking off the orchestration
executor.initiate_chat(
coder,
message="Refactor this legacy Python script for PEP-8 compliance and write unit tests."
)
The Reality in Production: AutoGen is incredibly intuitive. If you understand how a dev team talks in a Slack channel, you understand AutoGen. It is phenomenal for rapid prototyping, brainstorming, and use cases where you want the LLMs to figure out the path to the solution themselves.
However, as a Lead Engineer, handing over control flow to the LLM’s conversational whims can be terrifying. As noted in recent framework comparisons, debugging a failed AutoGen workflow often means reading through raw chat logs to figure out where the agents misunderstood each other. It lacks strict, deterministic state transitions.
The State Machine Paradigm: LangGraph
LangGraph, on the other hand, treats agent orchestration like a state machine. It forces you to think in terms of nodes (functions/agents), edges (control flow), and a centralized state object that gets updated at each step.
Instead of agents chatting, they are mutating a shared state. Crucially, LangGraph introduces cyclic graphs, allowing you to build loops where an agent writes code, another tests it, and if it fails, the flow loops back to the coder.
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
# 1. Define the strict state schema
class WorkflowState(TypedDict):
code: str
errors: List[str]
iterations: int
# 2. Define the nodes (business logic)
def generate_code(state: WorkflowState):
# LLM generation logic here...
return {"code": new_code, "iterations": state["iterations"] + 1}
def run_tests(state: WorkflowState):
# Execution logic here...
return {"errors": test_results}
# 3. Define the routing logic
def route_next(state: WorkflowState):
if state["errors"] and state["iterations"] < 3:
return "generate" # Loop back
return END # Finish
# 4. Compile the graph
workflow = StateGraph(WorkflowState)
workflow.add_node("generate", generate_code)
workflow.add_node("test", run_tests)
workflow.add_conditional_edges("test", route_next)
workflow.set_entry_point("generate")
app = workflow.compile()
The Reality in Production: LangGraph has a steeper learning curve. You have to understand graph theory basics and handle state management explicitly.
But for enterprise production, it is usually my weapon of choice. It gives you deterministic guardrails. You know exactly why an agent moved to a specific node. Furthermore, LangGraph’s built-in checkpointing allows for “time-travel” — you can pause a workflow, let a human review the state, modify it, and resume.
The Protocol for Building
Whichever framework you choose, the rules of engagement for agent-oriented infrastructure remain the same. Over the last year of deployments, I’ve settled on a few harsh truths:

- Don’t Overcomplicate the Graph: As the team at Vellum AI rightly points out, a massive workflow with 15 specialized agents and 40 tools will just confuse the orchestration layer. Start with a “Supervisor” pattern: one router agent and two execution agents. Expand only when accuracy demands it.
- FinOps is an Architecture Concern: Cyclic graphs mean your LLM calls can loop endlessly if not capped. Using an expensive frontier model (like GPT-4o or Claude 3.5 Sonnet) for every node will bankrupt your project. Design your protocols so that cheap, fast models handle routing and simple formatting, reserving frontier models solely for heavy reasoning nodes.
- Structured Output is Mandatory: If your agents are passing unstructured strings to one another, your system will break. Enforce strict JSON schemas (using Pydantic or similar) at every edge in your graph.
Final Thoughts
We are moving away from the era of “vibes-based” AI development and into an era of rigorous software engineering.
We can no longer just throw a massive prompt at an API and cross our fingers. We have to architect protocols. We have to design systems that anticipate failure, reflect on their own mistakes, and iterate toward a solution. The tools are finally here to do it, now it’s just a matter of building the right infrastructure.
References & Further Reading
- Machine Learning Mastery (2026). 7 Agentic AI Trends to Watch in 2026. A great breakdown of the “Microservices Moment” in AI, detailing the industry shift from monolithic LLM prompts to orchestrated multi-agent systems and the importance of FinOps in AI architecture.
- Leanware (2025). LangGraph vs AutoGen: Multi-Agent AI Framework Comparison. An excellent technical comparison highlighting the core differences between AutoGen’s message-passing architecture and LangGraph’s explicit state transitions, particularly regarding debugging in production.
- TrueFoundry (2025). AutoGen vs LangGraph: Comparing Multi-Agent AI Frameworks. Explores the practical trade-offs of both frameworks, detailing when to use team-style autonomous collaboration versus strict, cyclic state-machine control for enterprise applications.
- Microsoft AutoGen Documentation. AutoGen: Enabling Next-Gen LLM Applications. The official framework documentation for exploring conversational multi-agent patterns.
- LangChain / LangGraph Documentation. LangGraph: Build Resilient Language Agents as Graphs. The official documentation for implementing cyclic graphs and state machines in LLM workflows.
Prompt to Protocol: Architecting Agent-Oriented Infrastructure for Production LLMs was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.