
Part3: Guide to Hugging-face AutoModels** for Audio
In series of AutoModel** for We have discussed for Text based NLP models in part 1 and Vision based Models in Part2
Now we will discuss the Audio Based Models in this part
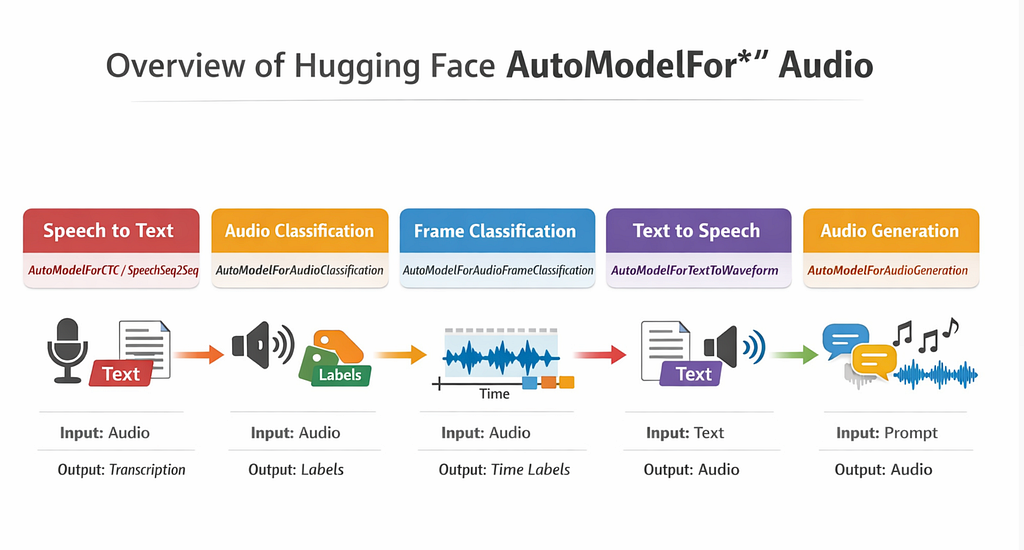
We will cover:
- How Hugging Face represents audio tasks
- Core AutoModelFor** classes for audio
- Common architectures behind them
- Practical examples (speech recognition, audio classification, text-to-speech)
- Tips for choosing the right class
Audio Tasks in Hugging Face
Audio models operate on waveforms or audio features instead of tokens. Hugging Face standardizes this workflow using:
- Datasets: audio columns with sampling rates
- Feature extractors / processors (e.g. AutoProcessor, AutoFeatureExtractor)
- Task-specific AutoModels
Unlike NLP, audio pipelines often combine signal processing + neural networks, which is why processors are especially important.
The AutoModelFor** Audio Family
| **Task** | **AutoModel Class** |
| ----------------------------------- | -------------------------------------- |
| Speech Recognition (ASR) | `AutoModelForSpeechSeq2Seq` |
| CTC-based Speech Recognition | `AutoModelForCTC` |
| Audio Classification | `AutoModelForAudioClassification` |
| Audio Frame Classification | `AutoModelForAudioFrameClassification` |
| Text-to-Speech (TTS) | `AutoModelForTextToWaveform` |
| Voice Conversion / Audio Generation | `AutoModelForAudioGeneration` |
AutoModelForCTC (Classic ASR)
Connectionist Temporal Classification (CTC) is commonly used when audio and text are misaligned. The model predicts token probabilities for each audio frame, and decoding collapses them into text.
AutoModelForCTC is a task-specific wrapper in Hugging Face for:
Speech recognition models trained with Connectionist Temporal Classification (CTC)
It is used when:
- Input = raw audio waveform
- Output = text tokens
- Alignment between audio and text is unknown or variable
Instead of predicting a full sentence at once, the model predicts token probabilities for each time frame of the audio.
Typical Models
- Wav2Vec2
- HuBERT
- XLS-R
When to Use
- You want fast, streaming-friendly ASR
- Your model outputs frame-level logits
Example Use Case
- Voice commands
- Transcription systems
How AutoModelForCTC Works Internally
Conceptually, the model has three main stages:
1. Feature Encoder
Converts raw audio → latent representations
(usually CNNs + Transformers)
2. Acoustic Model
Processes time-series features
Outputs logits for each time step
3. CTC Head
A linear layer that maps hidden states → vocabulary logits
AutoModelForCTC.from_pretrained("facebook/wav2vec2-base-960h")
Loading and inference
from transformers import AutoProcessor, AutoModelForCTC
import torch
import librosa
model_name = "facebook/wav2vec2-base-960h"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForCTC.from_pretrained(model_name)
model.eval()
### Load Audio
audio, sr = librosa.load("speech.wav", sr=16000)
### Preprocess
inputs = processor(
audio,
sampling_rate=16000,
return_tensors="pt",
padding=True
)
### inference
with torch.no_grad():
logits = model(**inputs).logits
### shape (batch_size, time_steps, vocab_size)
### decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
print(transcription[0])
We can train/finetune AutoModelForCTC but only for speech recognition
AutoModelForSpeechSeq2Seq
AutoModelForSpeechSeq2Seq is used for sequence-to-sequence speech models, meaning:
Speech → Text (or Text in another language)
using an encoder–decoder architecture
Unlike CTC, these models:
- Generate text token by token
- Use language modeling
- Understand context
This makes them more accurate, but also slower.
Architecture
Encoder (Audio → Hidden States)
- Processes raw waveform or features
- Extracts acoustic representations
Decoder (Hidden States → Tokens)
- Generates text one token at a time
- Uses attention over encoder outputs
- Acts like a language model
AutoModelForSpeechSeq2Seq.from_pretrained("openai/whisper-small")
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
import torch
import librosa
model_name = "openai/whisper-small"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_name)
model.eval()
### Load Audio
audio, sr = librosa.load("speech.wav", sr=16000)
### Preprocess
inputs = processor(
audio,
sampling_rate=16000,
return_tensors="pt"
)
### Generate Text
with torch.no_grad():
generated_ids = model.generate(**inputs)
transcription = processor.batch_decode(
generated_ids,
skip_special_tokens=True
)
print(transcription[0])
Can We Train AutoModelForSpeechSeq2Seq?
YES — for ASR and Translation
You can fine-tune it for:
- Speech recognition
- Speech translation
- Domain adaptation
Training Data: (audio.wav, target_text)
AutoModelForSpeechSeq2Seq is ideal for high-quality, multilingual, context-aware speech recognition and translation.
AutoModelForTextToWaveform (TTS & voice cloning)
| Model | Direction |
| ------------------------------ | ------------------- |
| AutoModelForCTC | 🎧 Speech → 📝 Text |
| AutoModelForSpeechSeq2Seq | 🎧 Speech → 📝 Text |
| **AutoModelForTextToWaveform** | 📝 Text → 🔊 Speech |
High Level Architecture
1. Text Encoder
- Converts text tokens into embeddings
- Learns pronunciation & prosody
2. Acoustic Model
- Predicts:
- Spectrograms, OR
- Discrete audio tokens, OR
- Direct waveform
3. Vocoder (sometimes internal)
- Converts spectrograms → waveform
- Some models bundle this, others don’t
AutoModelForTextToWaveform hides this complexity.
Typical Models Behind It
Common models loaded with this class:
- SpeechT5 (TTS mode)
- Bark
- VALL-E–style models (token-based audio)
Input
- Text (strings)
- Tokenized via AutoProcessor
O/P
Raw audio waveform (float tensor)
(batch_size, num_audio_samples)
Code Example — Text → Speech
from transformers import AutoProcessor, AutoModelForTextToWaveform
import torch
import soundfile as sf
model_name = "microsoft/speecht5_tts"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForTextToWaveform.from_pretrained(model_name)
model.eval()
### Prepare Text
text = "Hello, this is a text to speech example."
inputs = processor(text=text, return_tensors="pt")
### Generate Audio
with torch.no_grad():
audio = model.generate(**inputs)
### Save Waveform
sf.write("output.wav", audio[0].cpu().numpy(), samplerate=16000)
Can We Train It?
Yes: Training TTS requires:
- Large amounts of text + audio pairs
- Clean, aligned data
- Much more compute
Fine-Tuning Is More Common
Most people:
- Fine-tune on a single speaker
- Adapt pronunciation or style
Voice Cloning — Is It Possible?
YES (with conditions)
Voice cloning requires:
- A TTS model that supports speaker embeddings
- A short audio sample of the target speaker
Example:
- SpeechT5 uses a speaker embedding vector
- Bark uses prompt-based voice conditioning
Better models for voice cloning
OpenVoice (Open-Source, Zero-Shot Voice Cloning)
A Hugging Face model and research project that can:
- Clone a voice from a short audio sample
- Generate speech in multiple languages
- Offer style control (intonation, emotion, rhythm)
- Do zero-shot voice cloning — no retraining on the target speaker required
AutoModelForAudioGeneration
AutoModelForAudioGeneration is used for generating audio directly, not speech transcription and not classic TTS.
it is designed for Audio generation tasks such as
music, sound effects, ambient audio, or voice-like sounds
without requiring text → speech alignment
What Kind of Audio Can It Generate?
Depending on the model:
- 🎵 Music (melodies, beats, songs)
- 🌊 Ambient sounds (rain, wind, nature)
- 🔔 Sound effects (footsteps, alarms)
- 🗣 Voice-like audio (not linguistic TTS)
- 🎧 Continuations of existing audio
Architecture
Audio Tokenization
Raw waveform → discrete audio tokens
(using neural audio codecs like EnCodec)
Generative Model
- Transformer / diffusion / autoregressive model
- Predicts next audio tokens
Audio Decoder
Audio tokens → waveform
AutoModelForAudioGeneration hides all of this.
This is Typical Models Behind It
Common models loaded via this class:
- MusicGen (Meta)
- AudioGen
- SoundStorm-style models
- EnCodec-based generators
Code Example
from transformers import AutoProcessor, AutoModelForAudioGeneration
import torch
import soundfile as sf
model_name = "facebook/musicgen-small"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForAudioGeneration.from_pretrained(model_name)
model.eval()
### Prepare prompt
inputs = processor(
text="A calm ambient soundtrack with soft piano and rain",
return_tensors="pt"
)
### Generate Audio
with torch.no_grad():
audio = model.generate(**inputs)
### Save Audio
sf.write(
"music.wav",
audio[0].cpu().numpy(),
samplerate=32000
)
Can We Train or Fine-Tune It?
YES — but it’s expensive
Training requires:
- Massive audio datasets
- Audio tokenizers (e.g., EnCodec)
- Huge compute budgets
Most users:
- Use pretrained models
- Do limited fine-tuning or prompt engineering
AutoModelForAudioClassification
AutoModelForAudioFrameClassification
| Model | Classifies | Output |
| ---------------------------------------- | ---------------- | ------------------- |
| **AutoModelForAudioClassification** | Whole audio clip | One label per clip |
| **AutoModelForAudioFrameClassification** | Each time frame | One label per frame |
AutoModelForAudioClassification
Used when you want to assign one or more labels to an entire audio clip.
Typical Tasks
- Keyword spotting
- Speaker emotion recognition
- Music genre classification
- Environmental sound detection
- Accent / speaker classification
Input
- Raw audio waveform
- Shape: (batch_size, num_samples)
Output
- Logits: (batch_size, num_labels)
Code Example — Audio → Label
from transformers import AutoProcessor, AutoModelForAudioClassification
import torch
import librosa
model_name = "superb/wav2vec2-base-superb-ks"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForAudioClassification.from_pretrained(model_name)
model.eval()
audio, sr = librosa.load("audio.wav", sr=16000)
inputs = processor(
audio,
sampling_rate=16000,
return_tensors="pt"
)
with torch.no_grad():
logits = model(**inputs).logits
predicted_class = logits.argmax(dim=-1).item()
print(predicted_class)
When to Use It
Use AudioClassification if:
You need one label per audio clip
Timing is not important
You want simple outputs
AutoModelForAudioFrameClassification
Used when you need labels over time.
Typical Tasks
- Voice Activity Detection (speech / silence)
- Speaker diarization
- Phoneme recognition
- Music segmentation
- Emotion changes over time
Typical Models Behind It
- Wav2Vec2 (frame-level head)
- HuBERT (frame-level)
- Custom diarization models
Input
- Raw waveform
- Shape: (batch_size, num_samples)
Output
- Logits: (batch_size, time_steps, num_labels)
Code Example
from transformers import AutoProcessor, AutoModelForAudioFrameClassification
import torch
import librosa
model_name = "superb/wav2vec2-base-superb-vad"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForAudioFrameClassification.from_pretrained(model_name)
model.eval()
audio, sr = librosa.load("audio.wav", sr=16000)
inputs = processor(
audio,
sampling_rate=16000,
return_tensors="pt"
)
with torch.no_grad():
logits = model(**inputs).logits
frame_predictions = logits.argmax(dim=-1)
print(frame_predictions.shape)
Summarizing AutoModelFor** Audio
Speech Recognition (Audio → Text):
AutoModelForCTC
Output: frame-level logits
Best for:
Fast ASR
Streaming
Keyword or command recognition
AutoModelForSpeechSeq2Seq
- Output: generated token sequences
- Uses .generate() instead of logits
- Best for:
High-accuracy transcription
Multilingual ASR
Speech translation
Audio Classification (Audio → Labels)
AutoModelForAudioClassification
Output: clip-level logits
Best for:
Keyword spotting
Emotion detection
Music genre classification
Environmental sound recognition
AutoModelForAudioFrameClassification
- Output: time-aligned logits
Best for:
Voice Activity Detection (VAD)
Speaker diarization
Phoneme or event detection over time
Speech Generation (Text → Audio)
AutoModelForTextToWaveform
- Input: text
- Output: raw audio waveform
Best for:
Text-to-speech (TTS)
Voice assistants
Voice cloning (model-dependent)
General Audio Generation (Prompt → Sound)
AutoModelForAudioGeneration
- Input:
- Text prompts
- Optional audio prompts
- Output: generated audio waveform
Best for:
Music generation
Sound effects
Ambient audio
Creative audio applications
Speech → Text → CTC / SpeechSeq2Seq
Audio → Labels → AudioClassification
Audio → Time Labels → AudioFrameClassification
Text → Speech → TextToWaveform
Prompt → Sound → AudioGeneration
Part3: Guide to Hugging-face AutoModels** for Audio was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.