
One Developer, Two AI Agents, 43 Sprints: Running a Product Team of One
I built DealInspect — a deal intelligence platform in React on Domo’s App Framework — in about a week. 17 pillars of functionality. 43 sprints. A 6,800-line strategy document. One developer.
But I didn’t build it alone. I had two AI agents: Cursor for application code and product strategy, and Cortex CLI for everything that runs inside Snowflake. Together, the three of us ran what would normally require a product manager, a data engineer, a frontend engineer, and a Snowflake architect.
This isn’t a story about vibe coding. I didn’t point an AI at a blank repo and say “build me a deal review app.” I ran structured product development — requirements, roadmap, sprints, UAT, iteration — the same process a software product team would follow. The AI agents were team members with clear roles, not autocomplete tools.
Act 1: The Operating Model
The Strategy Document
Before writing a line of application code, I built the roadmap. IMPLEMENTATION_STRATEGY.md started as a one-page outline and grew to 6,800 lines across 6.5 draft versions. It contains everything a product team would produce: executive summary, architecture diagrams, schema designs, API specifications, sprint plans with effort estimates and dependencies, risk assessments, and — most importantly — a set of 17 independently valuable pillars that define what the platform does.

I didn’t write this document alone. I provided the product direction — “we need propensity-to-close scoring that composes with TDR complexity” — and Cursor translated that into structured strategy: requirements, architecture options, sprint breakdowns, definitions of done. I reviewed, pushed back, redirected. Cursor revised. The document became the single source of truth for the entire project — the artifact that replaced Jira, Confluence, and a PM.
Here’s the pillar structure (condensed):
Pillar
What It Does
1. Persistent Memory
Every TDR session stored in Snowflake, append-only, full history
2. External Intelligence
Sumble (firmographics) + Perplexity (web research) enrich every deal
3. Inline Chat
Context-aware conversational AI in the TDR Workspace
4. Cortex AI Processing
6 Snowflake Cortex functions: briefs, classification, extraction, embeddings, NLQ
5. Enriched Scoring
TDR scores incorporate real-world signals, two-phase (Pre-TDR + Post-TDR)
6. Canonical Readout
One-click executive PDF + Slack distribution
7. Knowledge Base
Domo filesets (battle cards, playbooks) auto-surfaced per deal
8. Frontier Models
Every AI operation uses best-in-breed models (Claude, GPT-4.1, o4-mini)
9. Lean Operating Model
9 TDR steps → 5, forcing questions, 30-minute target
10. Action Plan Synthesis
All intelligence synthesized into a 7-section strategic action plan
11. Performance & Caching
KB summaries cached to Snowflake, bundle optimization, dead code audit
12. UX Cohesion
Intelligence panel redesigned from data-source-centric to decision-oriented
13. Documentation Hub
In-app interactive architecture diagrams, scoring reference, capabilities guide
14. ML Propensity
Snowflake ML.CLASSIFICATION predicts deal closure, SHAP factor explanations
15. AI Enhancement
Per-field AI enhancement with inline diff + context-source badges
16. UX Polish
Production refinement of ML/AI surfaces, data visibility recalibration
17. TDR Redesign
Framework rebuilt: fewer steps, pill inputs, AI as core step, versioning
Each pillar is independently valuable — you can ship persistence without chat, or intelligence without Cortex. But they compound: every piece of stored data makes the chat smarter, every chat answer can feed back into inputs, and every interaction is persisted for posterity.
The strategy doc tracked all of this. Sprint plans had goals, risk assessments (“Medium — major structural refactor of the largest component”), effort estimates, prerequisites, and definitions of done. When I finished a sprint, I updated the doc. When scope changed, I updated the doc. Cursor helped write every update, but I made every decision.
The Shaping Methodology
Before implementing any major feature, I shaped it. The shaping methodology comes from @rjs — a structured framework for defining problems (Requirements) and exploring solutions (Shapes) before writing code.
The project produced 12 shaping documents in /shaping/. Each one follows the same pattern: define the problem, enumerate requirements (R0, R1, R2…), sketch solution shapes (A, B, C…), run a fit check (binary pass/fail matrix of requirements × shapes), identify rabbit holes (what NOT to chase), and declare no-gos (what’s explicitly off the table).
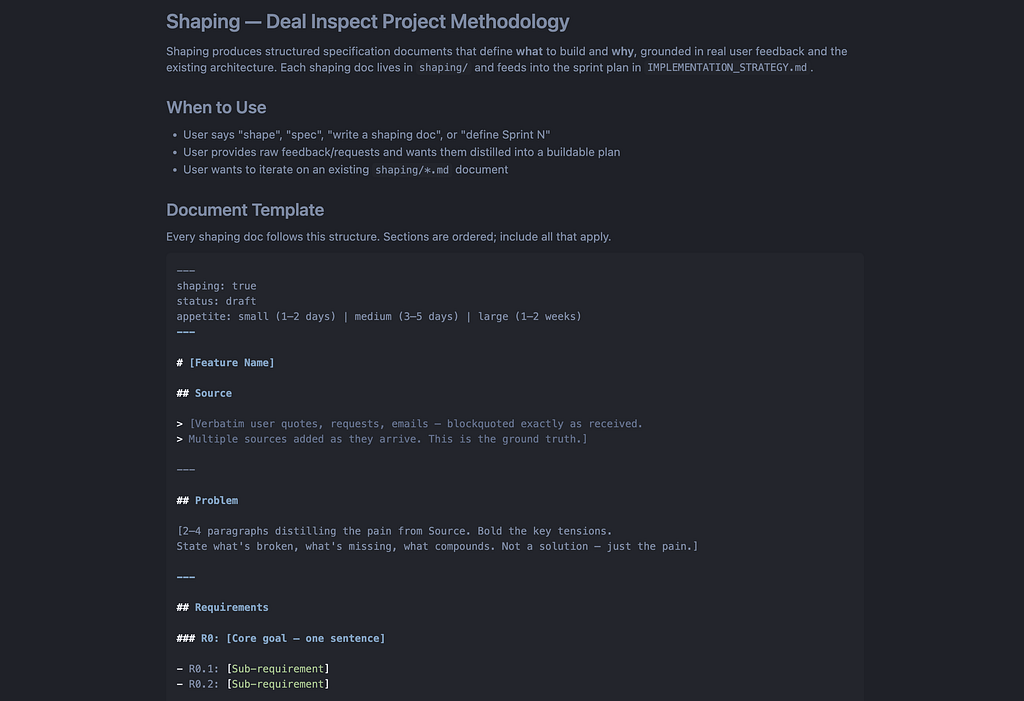
Here’s a condensed example from when I reshaped the ML pipeline. The original plan called for 4 Code Engine functions for real-time inference. I asked Cursor: does it make sense to just create a Snowflake predictions table instead? The shaping doc that came out:
## Problem
The original plan calls for 4 new Code Engine functions, each requiring
manifest mappings, a frontend service layer, and a dual data path.
This is significant plumbing for a single output: a propensity score per deal.
Meanwhile, propensity doesn't change minute-to-minute — it changes when deal
metadata flows through SFDC → Snowflake → Domo on a regular sync.
A score computed nightly is fresh enough.
## Proposed Simplification
Create a Snowflake predictions table. Join it with the opportunities data.
Let predictions flow through the existing Domo data pipeline as columns.
## What's Eliminated
| Original Plan | Predictions Table | Savings |
|----------------------------------|-----------------------|-------------------|
| getWinProbability() CE function | Eliminated | ~100 lines JS |
| batchScoreDeals() CE function | Eliminated | ~80 lines JS |
| getModelMetrics() CE function | Eliminated | ~60 lines JS |
| retrainModel() CE function | Eliminated | ~60 lines JS |
| mlPredictions.ts frontend service| Eliminated | ~150 lines TS |
| Real-time inference fallback | Eliminated | Frontend complexity|
| Total | | ~450 lines saved |
That’s the shaping process. The problem is stated. The requirements are clear. The fit check is binary. And the decision — predictions table vs. real-time inference — is made before a single line of code is written. No wasted sprints.
This is the layer that separates structured development from vibe coding. You don’t ask the agent to “add ML.” You define the problem, explore options, check fit, decide, THEN sprint.
The Sprint Cadence
Every feature followed the same cycle:
Shape → Sprint → Implement → UAT → Iterate → Ship
Shape: Define the problem and solution with Cursor, producing a shaping doc.
Sprint: Pull the sprint from the strategy doc, which has the goal, dependencies, effort estimate, and definition of done already written.
Implement: Cursor writes the code (TypeScript, React, SQL). I review, redirect, request changes.
UAT: I publish to Domo, click through every surface, and report what’s wrong. “The axis labels are overlapping.” “The tooltip is embarrassingly basic.” “That’s not an intuitive experience at all.” “AUC 0.997 — are you sure there’s no leakage?”
Iterate: Cursor fixes. I test again. Sometimes this takes three rounds. Sometimes five.
Ship: Update the strategy doc. Mark the sprint complete. Move on.
43 times.
Act 2: The Agent Collaboration
The Boundary Rule
The collaboration worked because the domains were explicit. I wrote a rule file (.cursor/rules/cortex-cli.mdc) that defined the boundary in one line:
If it runs IN Snowflake → ask Cortex CLI. If it runs OUTSIDE Snowflake → author it directly.
The full rule is more specific:
✅ USE Cortex CLI For:
- DDL: tables, schemas, views, stages, grants, permissions
- Stored procedures that run INSIDE Snowflake
- Snowflake Tasks, Alerts, Streams
- Cortex AI functions: AI_COMPLETE, AI_CLASSIFY, AI_EXTRACT, AI_EMBED, AI_AGG
- Snowflake ML: ML.CLASSIFICATION, Snowpark ML, Model Registry
- Data exploration: query live data, profile tables, validate features
🚫 DO NOT USE Cortex CLI For:
- Code Engine JavaScript
- Frontend TypeScript / React
- Application architecture decisions
- Git operations
- Testing / CI / Build

This rule stayed loaded in every Cursor session. It meant I never had to context-switch — I always knew which agent handled what.
What Each Agent Did
Cursor handled the application layer and product strategy:
- The entire IMPLEMENTATION_STRATEGY.md (6,800 lines, co-authored)
- 12 shaping documents
- All SQL authoring (sql/sprint_28c_ml_pipeline.sql — 500+ lines of DDL, views, procedures, tasks)
- TypeScript/React application code (components, hooks, services, types)
- PDF generation (@react-pdf/renderer)
- Pre-training data validation scripts
- Documentation components (7 in-app reference sections)
- All markdown, all git operations
Cortex CLI handled the Snowflake runtime:
- Executing SQL against Snowflake
- Self-healing type mismatches at runtime
- Training ML models (CREATE SNOWFLAKE.ML.CLASSIFICATION)
- Batch scoring (running stored procedures)
- Data exploration (querying live tables, profiling columns)
- Validating features against actual data types
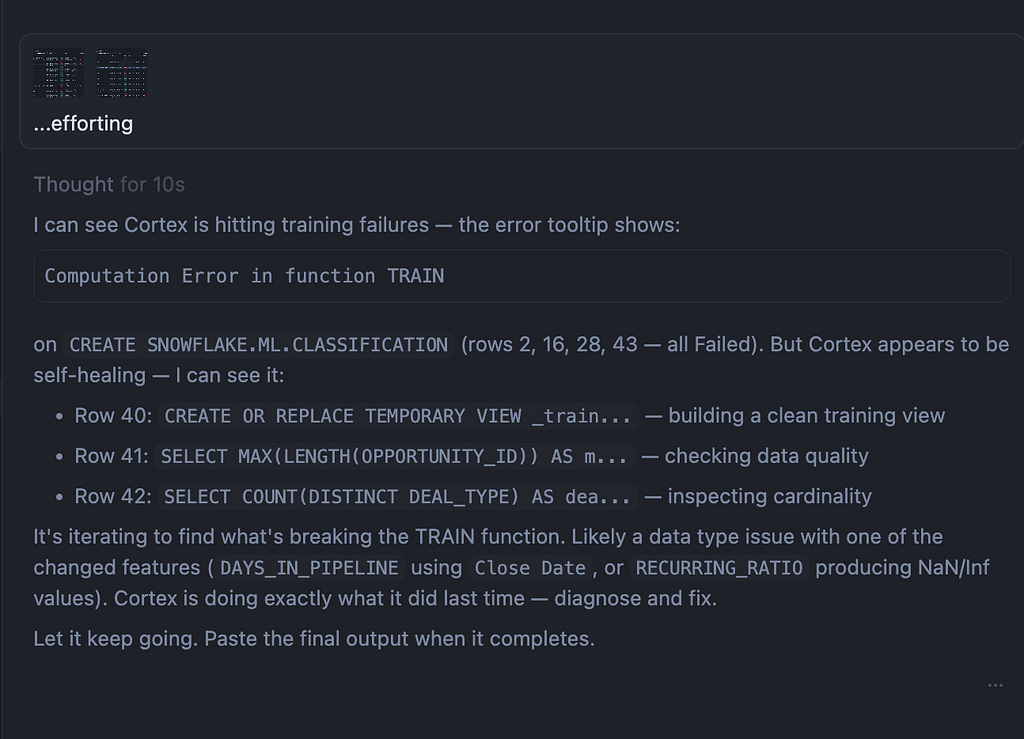
The Handoff Loop
The collaboration wasn’t “Cursor writes, Cortex executes.” It was a feedback loop:
- Cursor writes the SQL pipeline — schema, views, stored procedures, tasks
- I run it via Cortex CLI against Snowflake
- Cortex executes, hits a type mismatch, and self-heals — e.g., discovers People AI Engagement Level is FLOAT in the source, not VARCHAR as the SQL assumed, so it switches from string bucketing to numeric ranges (>= 80 → ‘Very High’, >= 60 → ‘High’)
- I reconcile those fixes back into the SQL file so the source of truth stays in sync
- Repeat
That reconciliation step is critical. Without it, the SQL file drifts from what actually runs. Cursor maintains the canonical pipeline; Cortex executes it. The human keeps them in sync.
In practice, the ML pipeline took three iterations. The first execution caught two type mismatches. The second trained successfully but produced suspicious metrics. The third — after a leakage audit — produced clean results.
The Human in the Loop
The agents wrote the code. I ran the product.
Product direction: I decided what to build and in what order. “We need a composite score that bridges ML propensity and TDR complexity.” “Reshape the TDR from 9 steps to 5.” “The Intelligence Panel should be organized by decisions, not data sources.” These were product decisions, not implementation details.
UAT: After every sprint, I published to Domo and clicked through every surface. I reported issues at every level — from layout bugs (“the column header is getting cut off”) to strategic misalignment (“there’s obvious misalignment between the TDR score and the propensity score”) to UX gaps (“when I land on this page, TDR brief is collapsed? it’s not an intuitive experience at all!”).
Quality gating: When the ML model returned AUC 0.997, I didn’t celebrate. I asked: “you sure no leakage?” Cursor audited the feature set and found five features that leaked the outcome — account-level rollups that included the current deal’s own result, stage age that measured time in “Closed Won” rather than time before close. We dropped the leakers, retrained, and got honest metrics: F1 92.3%. The agent didn’t question the features. The human did.
Architecture decisions: Predictions table vs. real-time inference. Three AI providers vs. one. Batch scoring vs. on-demand. These were shaped, evaluated, and decided before implementation. The agents presented options; I chose.
Act 3: What Emerged
Three AI Layers
The product that came out of this process has three reinforcing AI layers:
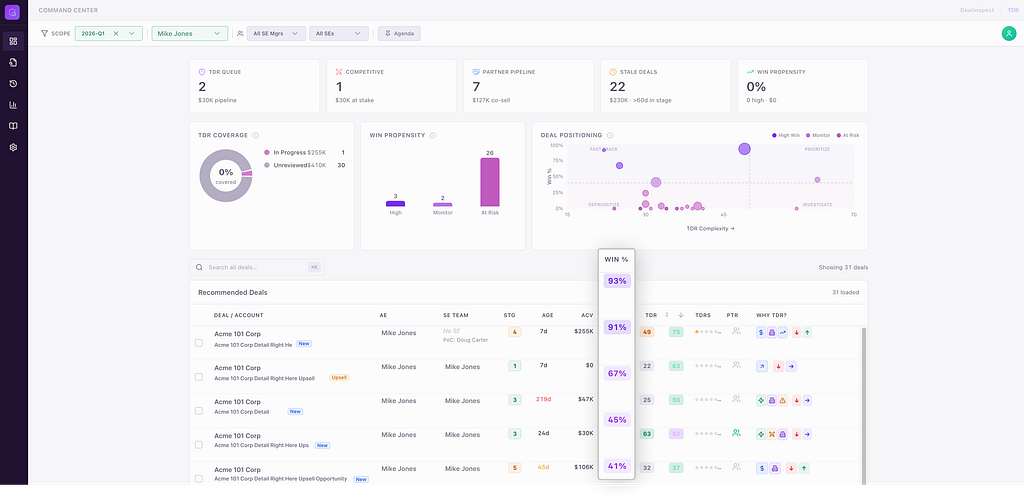
Predictive: A SNOWFLAKE.ML.CLASSIFICATION model scores every pipeline deal for close probability. No Python, no external compute — pure SQL. 6,569 deals scored nightly. Each prediction includes five SHAP-like factor explanations in plain English: “Days in Pipeline ↑ hurts close probability” or “Contract Type: New Logo ↓ lowers win rate.”
Generative: Six Cortex AI functions process stored data inside Snowflake — AI_COMPLETE for briefs and action plans, AI_CLASSIFY for finding categorization, AI_EXTRACT for entity extraction, AI_EMBED for semantic deal matching, Cortex Analyst for natural language SQL. Domo AI handles field enhancement with a 6-layer context stack (field purpose, step context, SE input, sibling fields, cross-step fields, deal metadata) and tech name extraction from Perplexity narrative signals.

Agentic: Multi-step workflows where outputs chain without human intervention. The readout workflow — Enrich → Research → Action Plan → TDR Brief — cascades through four AI calls, each one’s output feeding the next. When Perplexity returns market intel, two Cortex functions fire in parallel to classify findings and extract entities. The SE clicks one button; the system orchestrates the rest.
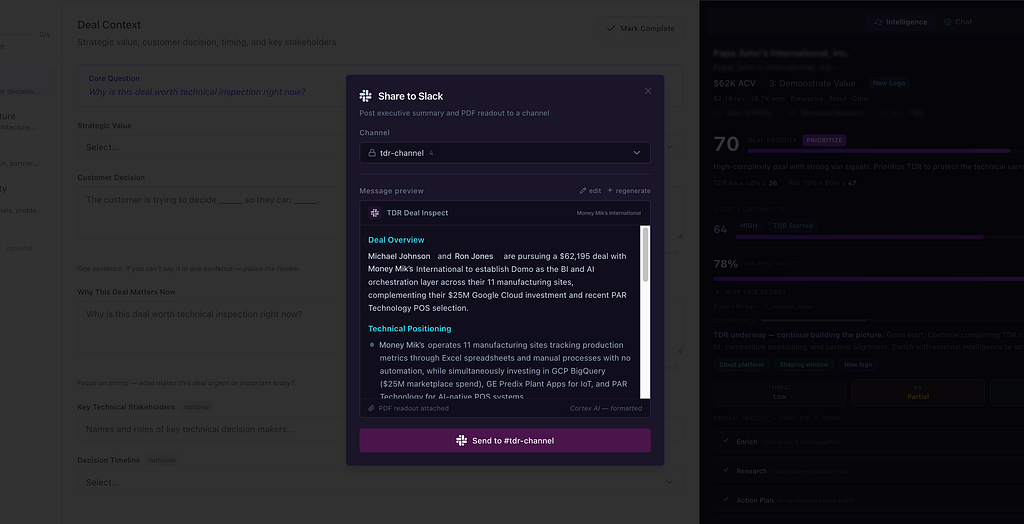
Three AI providers, each with a clear lane: Snowflake Cortex (data stays in the warehouse), Perplexity (real-time web research with citations), Domo AI (low-latency field enhancement). Code Engine routes to the right one. API keys stay server-side. The frontend is stateless.
The Composite Score
The predictive and generative layers converge in a single metric: Deal Priority.
Deal Priority = (Win Propensity × 60%) + (TDR Score × 40%)
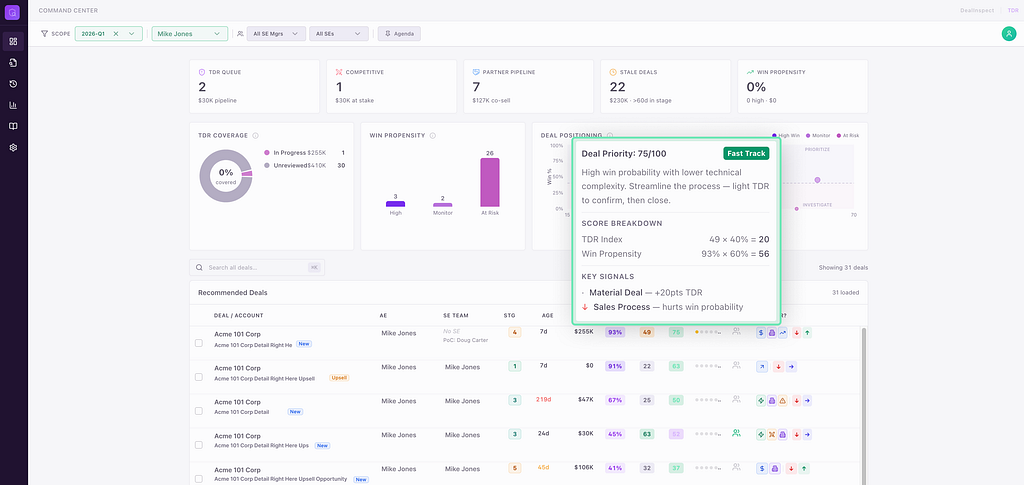
Win Propensity comes from the ML model. TDR Score comes from the SE’s structured inputs — enhanced by generative AI. The composite produces four quadrants:
Quadrant
Criteria
What It Means
PRIORITIZE
High TDR + High Win
Invest resources — both signals agree
FAST_TRACK
Low TDR + High Win
ML sees potential, needs TDR depth
INVESTIGATE
High TDR + Low Win
SE sees something the model doesn’t
DEPRIORITIZE
Low TDR + Low Win
Low signal from both
This is the bridge. ML says “73% chance of closing.” The SE’s TDR says “the architecture is complex but the customer decision is clear.” Deal Priority fuses both into a single sortable, visual signal. The scatter plot shows every deal positioned across both axes.
The Flywheel
The 17 pillars aren’t a feature list — they’re a flywheel. Better TDR inputs (Pillar 17) produce better AI extractions (Pillar 4), which produce better briefs and action plans (Pillar 10), which get shared via Slack (Pillar 6), which drives more TDRs on the right deals (Pillar 5), which produces more data for the ML model (Pillar 14), which improves prioritization, which focuses SE time on deals that matter.
Each pillar is a valid stopping point — the app works and delivers value at every increment. But together they compound. The strategy doc tracked this explicitly:
If you build…
The app becomes…
Pillar 1
A reliable, auditable TDR system with history
Pillars 1–4
A strategic platform that generates insights across all deals
Pillars 1–10
The complete platform — every data source synthesized into action plans
Pillars 1–14
The predictive platform — the system forecasts deal outcomes
All 17
The streamlined platform — the TDR itself is rebuilt, every downstream artifact gets better
43 sprints. ~1 month. One developer, two agents.
Takeaways
1. Structure beats speed. Shaping requirements before sprinting prevented rework. Every feature I built to spec; features I didn’t shape required more iteration. The 12 shaping documents saved more time than they cost.
2. The strategy doc IS the project manager. 6,800 lines of living strategy replaced Jira, Confluence, and a PM. Sprint plans, risk assessments, definitions of done, progress tracking — all in one markdown file, co-authored with Cursor, version-controlled in git.
3. Domain boundaries matter. The one-line rule — “If it runs IN Snowflake → Cortex CLI; if it runs OUTSIDE Snowflake → Cursor” — eliminated context switching. Each agent stayed in its lane. I never asked Cortex to write React or Cursor to run DDL.
4. The human runs the product, the agents run the code. I never wrote a line of application code. I shaped requirements, made architecture decisions, ran UAT, reported issues, and iterated. That’s the product manager’s job. The agents were the engineering team.
5. Self-healing agents reduce iteration. Cortex CLI didn’t just execute SQL — it fixed type mismatches at runtime and reported what it changed. I reconciled the fixes back into the source. The feedback loop was tight: write → execute → self-heal → reconcile.
6. Composition over capability. No single AI call in this app is remarkable. AI_CLASSIFY labels findings. AI_EXTRACT pulls names. AI_COMPLETE writes prose. The value is orchestration — cheap, focused calls wired together so each output enriches the next. The readout workflow is four AI calls; the result is better than one expensive call with a massive prompt.
7. This is reproducible. The operating model — strategy doc + shaping methodology + domain boundary rule + sprint cadence — isn’t specific to deal review apps or Domo or Snowflake. Any developer with domain expertise can run this pattern. The AI agents are the team. The human is the product owner. The strategy doc is the plan.
References
- IMPLEMENTATION_STRATEGY.md — 6,800-line product strategy and sprint tracker
- shaping/ — 12 shaping documents (requirements, shapes, fit checks)
- .cursor/rules/cortex-cli.mdc — the domain boundary rule
- sql/sprint_28c_ml_pipeline.sql — full ML pipeline (DDL, views, procedures, tasks)
- src/lib/cortexAi.ts — frontend Cortex AI service (20+ functions)
- src/lib/domoAi.ts — Domo AI service (enhancement, tech extraction)
- notebooks/02_pre_training_validation.py — pre-training data quality gate
The @rjs shaping methodology was the planning framework that made this work. Structure before code. Requirements before shapes. Shapes before sprints. The agents are fast enough to build anything — the human’s job is to make sure they build the right thing.
One Developer, Two AI Agents, 43 Sprints: Running a Product Team of One was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.