
Modern Questions vs Ancient Language
Why My RAG System Struggled with the Bible — and How I Fixed It

Introduction
I was building a Retrieval-Augmented Generation (RAG) system for a Bible question-answering application when I ran into a surprising problem. The system worked well for direct verse lookups, but when users asked natural questions like “Why do people suffer according to the Bible?”, the retrieved passages were often only loosely related.
The issue turned out to be neither the model nor the vector database — it was a more fundamental mismatch: modern conversational queries and 17th-century biblical English occupy very different regions of embedding space. This article walks through how I diagnosed the problem, redesigned the retrieval pipeline, and what I learned along the way.
The Language Distribution Problem
The King James Version (KJV) of the Bible was written in 17th-century English. Its vocabulary, phrasing, and sentence structures differ significantly from modern conversational language. This gap is wider than most practitioners expect when first working with historical texts.
Consider a simple example:
User question:
“Why do people suffer?”
Relevant verse:
“Man that is born of a woman is of few days, and full of trouble.” — Job 14:1 (KJV)
Although these are conceptually related, the wording is strikingly different. The embedding model must connect modern terms like “suffering” with archaic expressions like “full of trouble” — without any direct lexical overlap to anchor the similarity.
This is an instance of a well-known NLP challenge: language distribution shift. Embedding models struggle when queries and documents come from different linguistic eras or domains, because they were trained predominantly on modern English text. The result is a systematic gap between what users ask and what the retrieval system surfaces.
Key insight: The problem wasn’t the model or the database — it was that modern queries and biblical text are semantically distant in embedding space.
Initial RAG Architecture
The initial system followed a standard single-stage RAG pipeline:
User Query
→ Embedding Model
→ Vector Database (Similarity Search)
→ Top-K Retrieved Passages
→ LLM (Answer Generation)
→ Generated Answer

This worked well for direct lookups — questions like “What does John 3:16 say?” or “Where is the parable of the prodigal son?” But for abstract or thematic queries, it consistently underperformed. The root cause was that semantic similarity between a modern question and an archaic verse was too weak to reliably surface the most relevant passages.
Why Vector Search Alone Was Not Enough
Vector search excels when queries and documents share similar linguistic patterns. In this case, they did not. User queries tended to be conversational, modern, and question-based. Bible verses were poetic, declarative, and often context-dependent, relying on reader familiarity with broader narrative or theological context.
This mismatch was most pronounced for three types of queries:
- Abstract questions about emotions or experiences (e.g., “What does the Bible say about anxiety?”)
- Theological concepts without a direct modern equivalent (e.g., queries about grace, covenant, or atonement)
- Questions where the most relevant passages use indirect or metaphorical phrasing
An important early insight was that improving the generation model would not solve the problem. The root issue was retrieval quality — a better LLM generating answers from poorly retrieved passages still produces poor answers. The fix had to happen upstream.
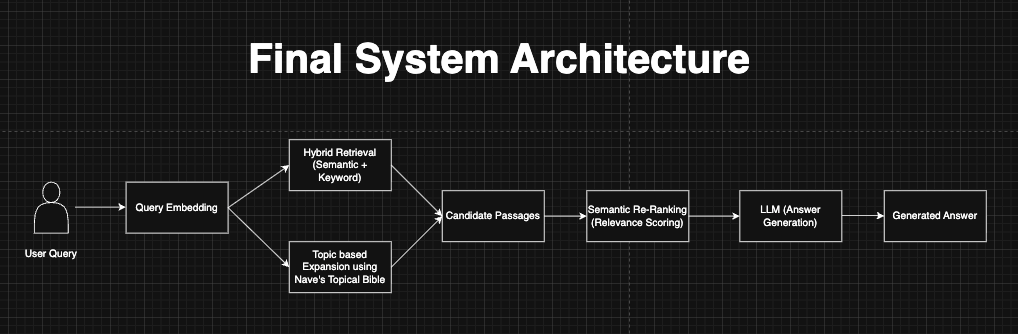
Moving to a Multi-Stage Retrieval Pipeline
To address the language distribution gap, I redesigned the system into a multi-stage pipeline that combined four complementary signals: semantic search, keyword-based retrieval, topic-based expansion, and semantic re-ranking.
Stage 1: Hybrid Retrieval (Semantic + BM25)
The first improvement was combining semantic search with BM25, a classical information retrieval scoring function that ranks documents based on term frequency and inverse document frequency. Unlike embedding-based search, BM25 operates purely on lexical overlap — it scores a document highly if it contains the same rare words as the query.
For biblical text, this turns out to be surprisingly effective. When a user asks about “anxiety,” BM25 can match verses containing related theological terms even when the embedding similarity is low. The two methods are complementary: semantic search captures meaning across different phrasings, while BM25 anchors retrieval to specific important terms.
A concrete example illustrates the gap that BM25 helps close:
Query:
“What does the Bible say about anxiety?”
Relevant verse:
“Be careful for nothing; but in every thing by prayer and supplication…” — Philippians 4:6 (KJV)
Here, “careful” is KJV English for “anxious” — a meaning that embedding models trained on modern text are unlikely to capture reliably. BM25’s term-matching helps surface it anyway via shared contextual vocabulary in surrounding verses.
Results from both methods were merged and deduplicated before downstream processing.
Stage 2: Topic-Based Expansion with Nave’s Topical Bible
Even with hybrid retrieval, some queries required concept-level understanding that neither embeddings nor term matching could fully provide. To address this, the system incorporated Nave’s Topical Bible — a curated index that maps theological topics to relevant scripture references.
When a user asks about “forgiveness,” a topic lookup returns a curated list of passages drawn from across the entire Bible, including narrative passages like the parable of the prodigal son (Luke 15:11–32) that pure statistical retrieval often missed. Before adding topic expansion, this parable — which most theologians would consider the most relevant passage on forgiveness — frequently failed to appear in the top results. After adding it, it consistently surfaced in the top three.
This approach allowed the system to retrieve through curated theological relationships rather than statistical similarity alone, which proved critical for abstract and conceptual queries.
Stage 3: Semantic Re-Ranking
After generating candidate passages from hybrid retrieval and topic expansion, the system applied a semantic re-ranking step. A secondary cross-encoder model scored each candidate passage against the original query and re-ranked them by relevance.
This final stage helped prioritize passages that best matched user intent rather than just surface similarity or keyword overlap. Re-ranking is computationally more expensive than the earlier retrieval stages, but because it operates on a small candidate set (rather than the full corpus), the overhead is manageable.
Final System Architecture
The complete pipeline combined all four stages:
Results and Observations
After implementing the multi-stage pipeline, retrieval quality improved noticeably across all query types. The most significant gains were on abstract and conceptual queries — exactly the cases where single-stage vector search had struggled most.
A few representative examples illustrate the improvement:
- “What does the Bible say about forgiveness?” — the parable of the prodigal son (Luke 15:11–32) went from rarely appearing to consistently ranking in the top 3.
- “Why do people suffer?” — results now included passages from Job, Psalms, and Romans rather than only surface-level matches.
- “What does the Bible say about anxiety?” — Philippians 4:6 moved from outside the top 10 to the top result.
The improvement in retrieval quality had a downstream effect on generation quality: the language model produced more grounded, contextually appropriate answers with fewer hallucinations, because it was working from better source material.
The pipeline did add complexity. The topic expansion step required maintaining and querying an external index, and re-ranking added latency. For most use cases the tradeoff was worth it, but teams operating under strict latency constraints may need to evaluate which stages to include.
Key insight: Improving retrieval had a larger impact on answer quality than any change to the language model.
What Surprised Me — and What I’d Do Differently
Three things caught me off guard during this project. First, how quickly retrieval quality degraded on archaic text — the KJV language gap was larger than I initially expected, and I underestimated how much modern embedding models depend on shared vocabulary. Second, how much a curated topical index outperformed pure statistical methods for conceptual queries. For theological questions, centuries of human curation in Nave’s index turned out to be more valuable than any automated similarity measure. Third, how little it mattered which language model I used once retrieval improved — the ceiling on answer quality was set almost entirely by retrieval, not generation.
If I were starting over, I’d evaluate BM25 recall on a held-out query set before writing a single line of embedding code. It’s fast to run and immediately reveals whether the language distribution problem is severe enough to warrant a multi-stage approach.
Broader Lessons for RAG Systems
The patterns from this project apply beyond biblical text. Any domain with historical sources, technical jargon, or specialized vocabulary will face similar distribution shift challenges. Legal archives, medical literature, historical records — all share this characteristic.
The core lessons translate directly:
- Retrieval failures are usually the real bottleneck. When a RAG system produces poor answers, check retrieval quality before tuning the generation model.
- Embeddings alone struggle across linguistic eras and domains. Hybrid search is often a simple, high-value fix.
- Domain-curated knowledge can outperform statistical methods. For conceptual queries, human-curated indexes or knowledge graphs may significantly improve recall.
- Multi-stage pipelines outperform single-step retrieval. Combining semantic, lexical, and domain signals produces more robust systems.
Final Thoughts
Building AI systems on historical or domain-specific texts introduces challenges that standard RAG benchmarks rarely surface. Language evolves, but knowledge sources often remain fixed — and that gap matters more than most practitioners expect.
This project reinforced a simple idea: the quality of your answers is bounded by the quality of your retrieval. As RAG systems expand into law, medicine, and historical archives, combining semantic search, lexical methods, and domain knowledge will be essential — not optional.
Modern Questions vs Ancient Language was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.