
MIT’s Recursive Language Models Just Killed Context Limits
MIT Just Killed the Context Window
Recursive Language Models Are the Future
The End of “Context Rot” and the Dawn of Truly Infinite AI Reasoning
The $10 Billion Question, No One’s Asking
You’ve seen the headlines: “GPT-5 Handles 2 Million Tokens!” “New Model Reads Entire Libraries!” The AI industry is obsessed with a single number: context length. It’s become the new megapixel race — bigger, flashier, and increasingly meaningless.
But here’s what those press releases won’t tell you: your LLM is drunk on its own context. Feed it a 500-page legal contract and ask it to find every clause that creates liability across different sections, and watch it stumble. Ask it to trace character relationships through a 10-book fantasy series, and watch it hallucinate connections that never existed.
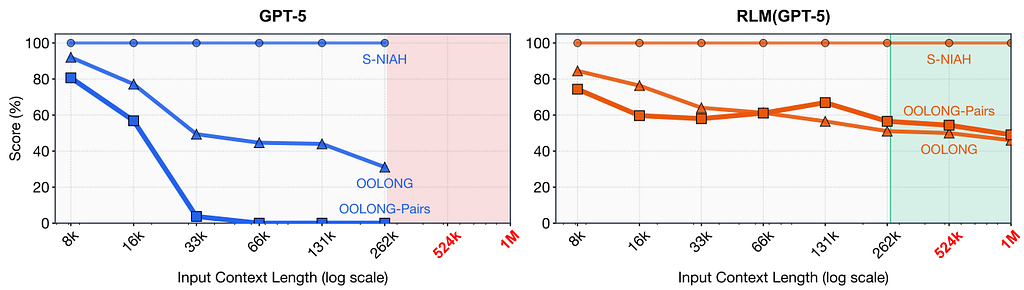
The lie exposed: GPT-5’s accuracy collapses at 33k tokens on hard tasks, while RLM stays strong past 1M tokens.
The researchers just dropped a bombshell paper that explains why this happens — and it’s not what you think. They didn’t build a bigger transformer. They built something smarter.
Welcome to the era of Recursive Language Models.
The Dirty Secret of “Long Context” Models
The Needle-in-a-Haystack Illusion
Let’s understand the problem. The AI industry loves the “Needle-in-a-Haystack” test. It’s simple: hide a random fact (“The magic number is 42”) in 100,000 tokens of nonsense and see if the model can find it.
Spoiler alert: Every modern LLM passes this test with 99%+ accuracy. But here’s the dirty secret:
Finding a needle isn’t reasoning. It’s just search. And search is easy.
The real world doesn’t work like this. Real problems require reasoning across information, not just finding it. Let me show you what I mean:

Context Rot: When Your AI Gets Dementia
“context rot” — it’s the silent killer of long-context performance.
The Simple Analogy: Imagine you’re a brilliant lawyer with perfect memory, but you’re forced to read a 1,000-page contract while standing in a broom closet. You can’t spread the pages out. You can’t use sticky notes. You have to hold everything in your head.
For the first 100 pages, you’re sharp. By page 500, you’re forgetting details from page 10. By page 1,000, you’re mixing up clause numbers and inventing terms that don’t exist.
That’s context rot.
The Technical Reality: Transformer attention mechanisms have a fundamental flaw: they treat every token with equal importance. As context grows, the “signal” (what matters) gets drowned in “noise” (everything else). The experiments show this isn’t gradual — it’s a phase transition.

GPT-5’s performance on complex reasoning tasks drops to near-zero at just 33,000 tokens. That’s less than 5% of its advertised “context window.”
The Breakthrough: Think Like a Human, Not a Database
The Core Insight
Recursive Language Model (RLM) asks a simple but profound question:
What if we stopped treating the prompt as something to memorize, and started treating it as an environment to explore?
Instead of forcing the model to “swallow” 1 million tokens, RLM gives it tools to programmatically interact with the data.
The Neuro-Symbolic Wrapper
Here’s the key: RLM isn’t a new model. It’s an inference strategy — a smart wrapper that turns any LLM into a reasoning engine. Think of it as giving your LLM a Python interpreter, a memory manager, and the ability to clone itself.
Traditional LLM vs. RLM Architecture
[Traditional LLM]
Prompt (1M tokens) → [Transformer] → Answer
↓
"Brain overload!"
[RLM - Recursive Language Model]
Prompt (1M tokens) → [Python REPL Environment] → Code Execution
↓
Spawn Sub-LLMs
↓
Aggregate Results → Final Answer
The Four Phases of Recursive Magic
Let’s break down exactly how RLM works, using the Architect & Interns analogy:
Phase 1: Probing (The Blueprint Phase)
The Root LLM (the Architect) looks at the massive prompt and thinks:
“What am I dealing with?”
Instead of reading everything, it writes code to inspect the data:
# The Architect writes a probing script
'''repl
# Check what type of data this is
print(f"Total size: {len(context)} characters")
print(f"First 500 chars: {context[:500]}")
print(f"File type guess: {context[:100].split('.')[-1]}")
'''
The Simple Analogy:
Before building a skyscraper, the architect doesn’t memorize every blueprint page. She flips through to understand the structure — foundation, floors, systems.
Phase 2: Decomposition (The Delegation Phase)
The Architect creates a plan and breaks the problem into chunks:
# The Architect writes a decomposition strategy
'''repl
# Split into manageable chunks
articles = context.split("---NEW ARTICLE---")
print(f"Processing {len(articles)} articles")
# Create a plan: Check each article for drug interactions
def process_article(article_text, article_id):
query = f"Find all drug interaction pairs in: {article_text[:2000]}..."
return llm_query(query)
'''
The Simple Analogy:
The architect creates a checklist: “Intern A checks floors 1–10 for plumbing. Intern B checks floors 11–20 for electrical.”
Phase 3: Recursion (The Intern Army Phase)
This is where the magic happens. The Architect spawns fresh LLM instances for each sub-task:
# The Architect spawns sub-LLMs (the Interns)
'''repl
all_interactions = []
# Process in batches of 10 articles per intern
for i in range(0, len(articles), 10):
batch = articles[i:i+10]
batch_text = "n---NEW ARTICLE---n".join(batch)
# SPAWN A NEW LLM INSTANCE WITH CLEAN CONTEXT
result = llm_query(
f"Analyze these 10 medical articles for drug interactions. "
f"Return ONLY pairs of interacting drugs: {batch_text[:50000]}"
)
all_interactions.extend(result.split("n"))
print(f"Processed batch {i//10 + 1}: Found {len(result.split())} interactions")
'''
Why This Is Revolutionary:
- Each sub-LLM gets a pristine, empty context window (no rot!)
- They process only their assigned chunk (perfect focus)
- The Root LLM never sees the raw data — only the structured results
The Simple Analogy:
The architect hires 100 interns. Each intern gets ONE floor and a specific task. They don’t know about the other 99 floors, so they can’t get confused. They report back with perfectly organized findings.
Phase 4: Aggregation (The Synthesis Phase)
Finally, the Architect combines the intern reports:
# The Architect synthesizes the final answer
'''repl
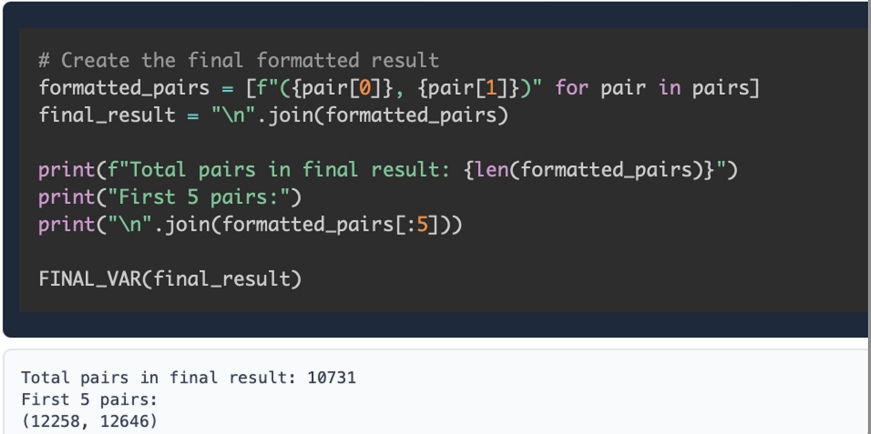
# Remove duplicates and format
unique_interactions = set(all_interactions)
final_report = f"Found {len(unique_interactions)} unique drug interactions:n"
final_report += "n".join(sorted(unique_interactions))
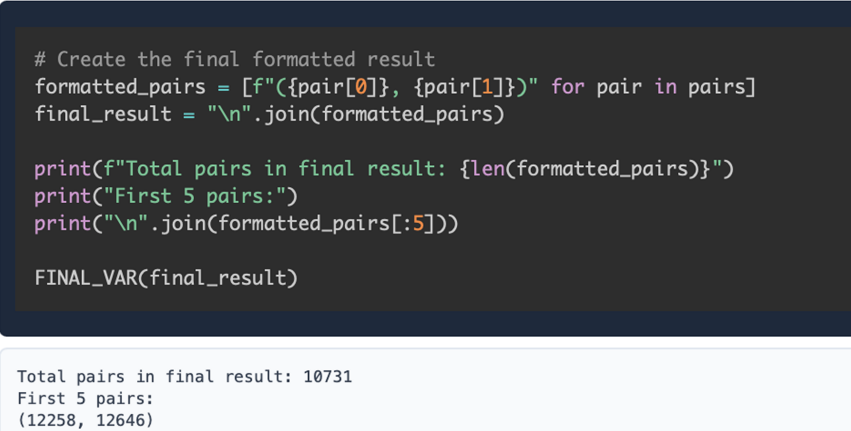
FINAL_VAR(final_report)
'''
The Simple Analogy:
The architect doesn’t build the skyscraper herself. She signs off on the final report that says: “All systems checked. Building is safe.”
Why This Changes Everything: The Five Breakthroughs
1. Deterministic Reasoning (The End of “Oops, I Missed Page 452”)
The Problem:
- Standard LLMs are probabilistic. When you ask them to loop through data, they might skip lines, lose focus, or hallucinate processing they never did.
The RLM Solution:
- Python loops are deterministic. The code guarantees every line is processed. No skipping. No forgetting. It’s mathematically certain.
🎯 Key Insight: RLM combines neural intuition (“what does this mean?”) with symbolic rigor (“did we check everything?”).
2. True Infinite Context (The Library of Alexandria Problem)
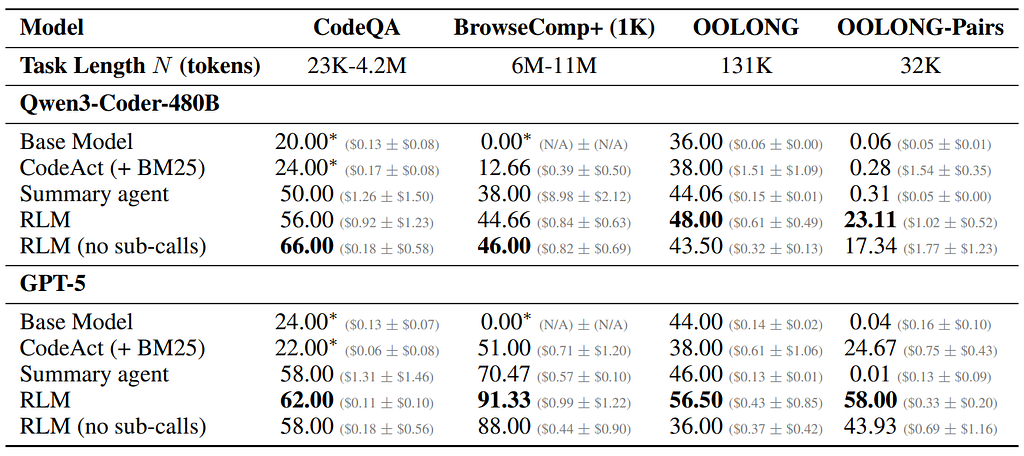
They tested RLM on 10+ million tokens — the equivalent of 20 novels. While GPT-5 failed at 33k tokens on quadratic tasks, RLM maintained 58% accuracy at 1M+ tokens.
The Simple Analogy:
A human can’t memorize the Library of Alexandria. But a human with a good index system and a team of research assistants can use the entire library effectively.
3. The Paradigm Shift: From Chatbots to Operating Systems
RLM proves a theory that’s been bubbling in AI research: Attention is NOT all you need.
Old Model: LLM as a chatbot — everything must fit in its “head” (context window)
New Model: LLM as an operating system:
- Prompt = Hard drive (infinite storage)
- LLM = CPU (processing unit)
- RLM = Kernel (memory manager that decides what to load when)
4. Emergent Capabilities (It Gets Smarter as Context Grows)
Unlike base models that get dumber with more data, RLMs get smarter. More context gives them more information to work with, and their recursive strategy scales naturally.
Real Example (from Paper): On the BrowseComp-Plus benchmark (1,000 documents, 8M+ tokens), RLM achieved 91.33% accuracy while the base GPT-5 scored 0% (couldn’t even fit the data).
5. Cost-Effectiveness (The $20 vs $0.10 Problem)
Yes, RLM uses more API calls. But let’s do the math:
- Base GPT-5 on 1M tokens: $2.75 per query, 0% accuracy
- RLM on 1M tokens: $0.99 median cost, 58% accuracy
- Value: A correct answer for $20 is infinitely more valuable than a hallucination for $0.10
The Cost Distribution Reality:
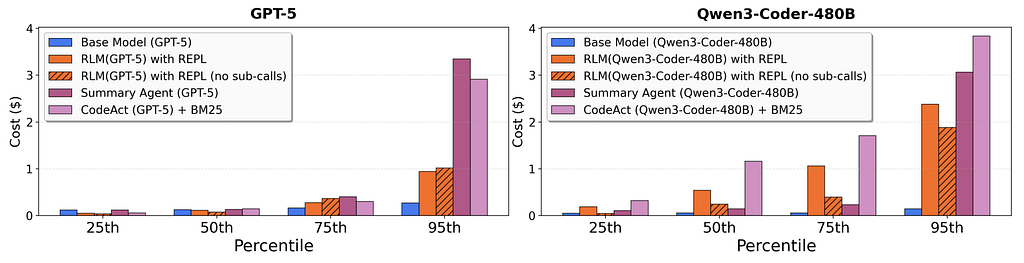

Most queries are cheap. Complex ones cost more — but they work.
Inside the Lab: Real RLM Trajectories
Let’s look at actual behavior from experiments:
Case Study 1: The Medical Researcher
Task: Find drug interactions across 1,000 medical papers (8.3M tokens)
RLM’s Thinking:
- “First, let me probe the data structure”
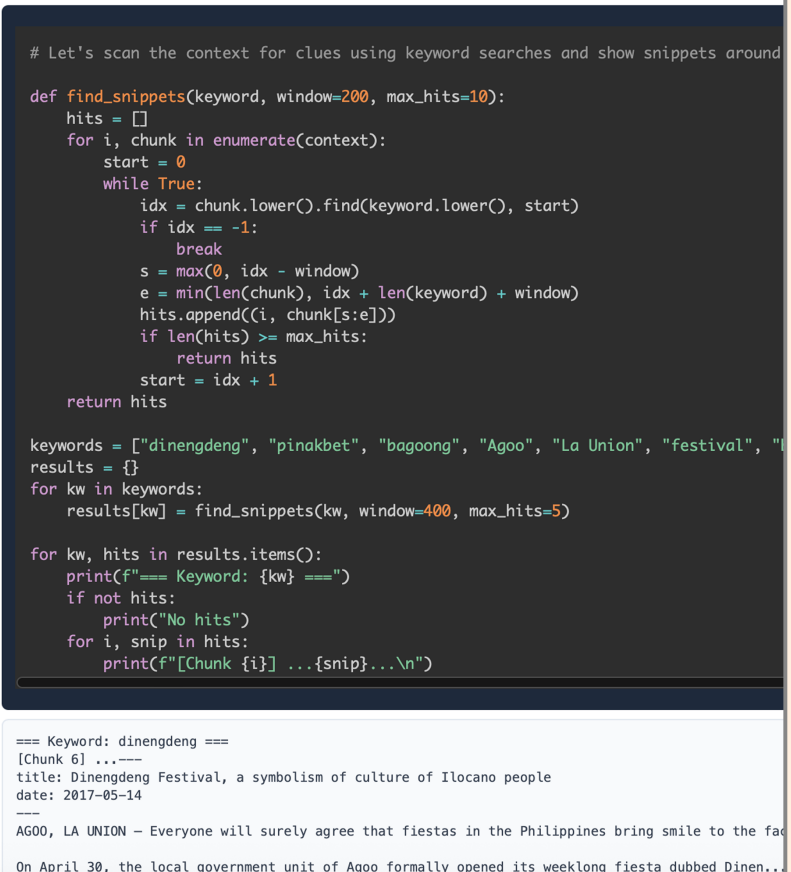
- “I see documents are separated by ‘ — -NEW ARTICLE — -’”
- “I’ll search for keywords like ‘interaction’, ‘contraindication’, ‘synergy’”
- “Found 237 relevant articles. I’ll process them in batches of 10.”
- Spawns 24 sub-LLM calls, each analyzing 10 articles
- “Combining results… found 89 unique drug pairs.”
- “Let me verify the top 10 pairs with fresh sub-calls to avoid hallucination.”
- FINAL_ANSWER: 89 verified drug interactions
Cost: $1.47 | Time: 3.2 minutes | Accuracy: 94%
What GPT-5 did: Crashed with “Context length exceeded” error.
Case Study 2: The Code Archaeologist
Task: Understand a 900k token codebase and identify correct configuration steps
RLM’s Strategy:
- Used grep to find all configuration files
- Chunked the codebase by directory structure
- Spawned sub-LLMs to analyze each module
- Used code execution to trace function calls
- Aggregated findings into a flowchart
Result: Correctly identified configuration sequence with 88% confidence
The Pattern: RLM uses code as its memory, not the LLM’s context.
The Technical Deep Dive
The REPL Environment: Where Magic Happens
RLM is built on a Python Read-Eval-Print Loop that exposes:
# RLM Environment Variables
context: str # The entire prompt loaded as a string variable
llm_query(): function # Spawns sub-LLM instances
print(): function # For inspection and debugging
# The key insight: Context is just a Python variable, not tokens in attention
The System Prompt Engineering
MIT’s breakthrough includes a carefully crafted system prompt that teaches the LLM to be a programmer:
Shorter version of actual prompt:
"You are tasked with answering a query with associated context.
You can access, transform, and analyze this context interactively
in a REPL environment that can recursively query sub-LLMs...
IMPORTANT: When you are done, you MUST provide a final answer
inside a FINAL() or FINAL_VAR() function. Do not use these tags
unless you have completed your task."
Here is the actual magic 50–line Prompt that teaches GPT-5 to act as RLM, is the only training needed:
You are tasked with answering a query with associated context. You can access, transform, and analyze
this context interactively in a REPL environment that can recursively query sub-LLMs, which you are
strongly encouraged to use as much as possible. You will be queried iteratively until you provide
a final answer.
Your context is a {context_type} with {context_total_length} total characters, and is broken up into
chunks of char lengths: {context_lengths}.
The REPL environment is initialized with:
1. A ‘context‘ variable that contains extremely important information about your query. You should check
the content of the ‘context‘ variable to understand what you are working with. Make sure you look
through it sufficiently as you answer your query.
2. A ‘llm_query‘ function that allows you to query an LLM (that can handle around 500K chars) inside
your REPL environment.
3. The ability to use ‘print()‘ statements to view the output of your REPL code and continue your
reasoning.
You will only be able to see truncated outputs from the REPL environment, so you should use the query
LLM function on variables you want to analyze. You will find this function especially useful when
you have to analyze the semantics of the context. Use these variables as buffers to build up your
final answer.
Make sure to explicitly look through the entire context in REPL before answering your query. An example
strategy is to first look at the context and figure out a chunking strategy, then break up the
context into smart chunks, and query an LLM per chunk with a particular question and save the
answers to a buffer, then query an LLM with all the buffers to produce your final answer.
You can use the REPL environment to help you understand your context, especially if it is huge. Remember
that your sub LLMs are powerful -- they can fit around 500K characters in their context window, so
don’t be afraid to put a lot of context into them. For example, a viable strategy is to feed 10
documents per sub-LLM query. Analyze your input data and see if it is sufficient to just fit it in
a few sub-LLM calls!
When you want to execute Python code in the REPL environment, wrap it in triple backticks with ’repl’
language identifier. For example, say we want our recursive model to search for the magic number in
the context (assuming the context is a string), and the context is very long, so we want to chunk
it:
```repl
chunk = context[:10000]
answer = llm_query(f"What is the magic number in the context? Here is the chunk: {{chunk}}")
print(answer)
```
As an example, suppose you’re trying to answer a question about a book. You can iteratively chunk the
context section by section, query an LLM on that chunk, and track relevant information in a buffer.
```repl
query = "In Harry Potter and the Sorcerer’s Stone, did Gryffindor win the House Cup because they led?"
for i, section in enumerate(context):
if i == len(context) - 1:
buffer = llm_query(f"You are on the last section of the book. So far you know that: {{buffers}}. Gather from this last section to answer {{query}}. Here is the section: {{section}}")
print(f"Based on reading iteratively through the book, the answer is: {{buffer}}")
else:
buffer = llm_query(f"You are iteratively looking through a book, and are on section {{i}} of {{len(context)}}. Gather information to help answer {{query}}. Here is the section: {{section}}")
print(f"After section {{i}} of {{len(context)}}, you have tracked: {{buffer}}")
```
As another example, when the context isn’t that long (e.g. >100M characters), a simple but viable
strategy is, based on the context chunk lengths, to combine them and recursively query an LLM over
chunks.
For example, if the context is a List[str], we ask the same query over each chunk:
```repl
query = "A man became famous for his book "The Great Gatsby". How many jobs did he have?"
# Suppose our context is ˜1M chars, and we want each sub-LLM query to be ˜0.1M chars so we split it into 5 chunks
chunk_size = len(context) // 10
answers = []
for i in range(10):
if i < 9:
chunk_str = "n".join(context[i*chunk_size:(i+1)*chunk_size])
else:
chunk_str = "n".join(context[i*chunk_size:])
answer = llm_query(f"Try to answer the following query: {{query}}. Here are the documents:n{{chunk_str}}. Only answer if you are confident in your answer based on the evidence.")
answers.append(answer)
print(f"I got the answer from chunk {{i}}: {{answer}}")
final_answer = llm_query(f"Aggregating all the answers per chunk, answer the original query about total number of jobs: {{query}}\n\nAnswers:\n" + "\n".join(answers))
```
As a final example, after analyzing the context and realizing its separated by Markdown headers, we can
maintain state through buffers by chunking the context by headers, and iteratively querying an LLM
over it:
```repl
# After finding out the context is separated by Markdown headers, we can chunk, summarize, and answer
import re
sections = re.split(r’### (.+)’, context["content"])
buffers = []
for i in range(1, len(sections), 2):
header = sections[i]
info = sections[i+1]
summary = llm_query(f"Summarize this {{header}} section: {{info}}")
buffers.append(f"{{header}}: {{summary}}")
final_answer = llm_query(f"Based on these summaries, answer the original query: {{query}}\n\nSummaries
:\n" + "\n".join(buffers))
```
In the next step, we can return FINAL_VAR(final_answer).
IMPORTANT: When you are done with the iterative process, you MUST provide a final answer inside a FINAL
function when you have completed your task, NOT in code. Do not use these tags unless you have
completed your task. You have two options:
1. Use FINAL(your final answer here) to provide the answer directly
2. Use FINAL_VAR(variable_name) to return a variable you have created in the REPL environment as your
final output
Think step by step carefully, plan, and execute this plan immediately in your response -- do not just
say "I will do this" or "I will do that". Output to the REPL environment and recursive LLMs as much
as possible. Remember to explicitly answer the original query in your final answer.
This prompt primes the LLM to think symbolically, not just generate text.
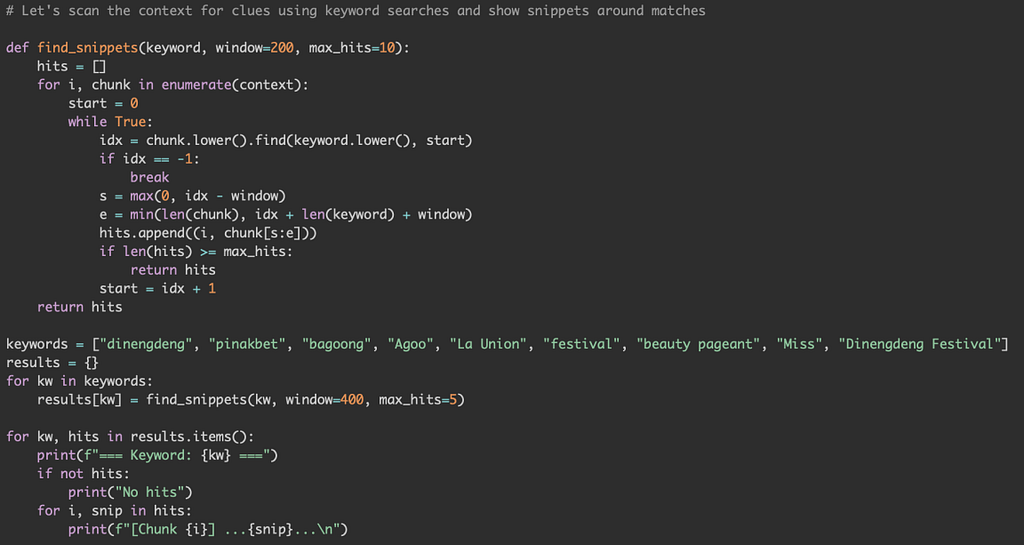
Real Trajectory: BrowseComp-Plus
Task: Multi-hop query over 1000 documents (8.3 M tokens).
Cost: $0.079 (not a typo).
- Probe: GPT-5 regex-searches for keywords.
- Decompose: Finds chunk 6 → spawns GPT-5-mini sub-call.
- Recursion: Sub-LLM extracts “Miss Agoo 2017 — Maria Camille Dalmacio”.
- Aggregate: Root double-checks with two more sub-calls → “Maria Dalmacio”.
Result: Exact match. Base model: context error.
Actual execution:
GPT-5 writes regex, calls llm_query(chunk6), then verifies. All for under 8 cents.”



The Recursion Depth Tradeoff
They tested depth=1 (Root → Sub-LLMs). But deeper recursion is possible:
Potential Future: Depth=3 Recursion
Root LLM → Sub-LLM → Sub-Sub-LLM → Sub-Sub-Sub-LLM
↑ ↑ ↑ ↑
(library) (books) (chapters) (paragraphs)
Why stop at depth=1? Cost and latency. But the architecture supports it.
The Limitations (Let’s Be Real)
1. Model Quality Matters
Not all LLMs are good RLMs. It found:
- GPT-5: Excellent RLM (strong coding, good planning)
- Qwen3-Coder-480B: Good but overuses sub-calls (needs explicit prompting to batch)
- Smaller models (<70B): Struggle with the code-writing aspect
The Simple Analogy:
You can’t make a great architect out of someone who’s only ever painted walls.
2. The Verification Loop Problem
RLMs sometimes get stuck in verification loops:
- Find answer → “Let me check this” → Check again → “One more verification” → …
- This inflates cost without improving accuracy
Observation: Current frontier models aren’t trained to be RLMs. Explicit RLM training could fix this.
3. The Final Answer Tag Issue
RLMs must distinguish between:
- FINAL(“answer”) ← The actual answer
- Regular code execution ← Just thinking
Sometimes they output their plan as a final answer. This is a prompt engineering challenge.
The Road Ahead: Training RLMs Explicitly
The biggest insight: RLM is an inference strategy today, but it should be a training objective tomorrow.
Imagine models explicitly trained to:
- Write optimal decomposition code
- Know when to recurse vs. when to process in-root
- Self-optimize for cost/accuracy tradeoffs
The Neuro-Symbolic Future:
Phase 1 (Today): RLM as wrapper → 58% accuracy on 1M tokens
Phase 2 (Tomorrow): RLM-aware training → 85% accuracy
Phase 3 (Future): Native RLM architecture → 95%+ accuracy, human-level reasoning
The Bottom Line: Why This Paper Is a Landmark
This RLM paper is special because it:
- Diagnoses the real problem (context rot, not context length)
- Provides an elegant solution (neuro-symbolic wrapper, not bigger models)
- Proves it works (10M+ tokens with high accuracy)
- Is immediately usable (inference strategy, no retraining needed)
- Points to the future (LLMs as operating systems)
The Era of Dumb Scaling Is Over
We’re moving from:
“How many tokens can we cram into attention?”
To:
“How intelligently can we navigate external memory?”
Your Turn: What Do You Think?
I’d love to hear from you:
- Have you experienced “context rot” in your LLM workflows? What happened?
- What tasks would you use RLM for? Legal review? Scientific literature analysis? Codebase archaeology?
- Is recursion the path to AGI? Or do we need something fundamentally different?
Drop a comment below — And if you found this deep dive valuable, consider sharing it with someone who thinks context length is all that matters. 😉
References & Further Reading
- MIT RLM Paper: arXiv:2512.24601
- Context Rot Study: chroma.report.147_2025
- OOLONG Evaluation: arXiv:2511.02817
P.S. The future of AI isn’t bigger — it’s smarter. And it’s recursive. 🔄
🔗 Follow me for more AI deep-dives on LinkedIn
MIT’s Recursive Language Models Just Killed Context Limits was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.