
Mamba: From Intuition to Proof — How Delta-Gated State Space Models challenges the Transformer
Mamba: From Intuition to Proof — How Delta-Gated State Space Models Challenge the Transformer

Paper-explained Series 2
The field of Artificial Intelligence has been defined by a single architecture for nearly a decade: the Transformer. While it has powered revolutions like ChatGPT and Claude, it hides a structural flaw that no amount of scaling can simply “fix.”
Transformers suffer from a quadratic bottleneck. As the length of the input sequence (L) grows, the computational cost grows by L². This makes processing massive sequences — like entire human genomes (millions of base pairs) or raw audio waveforms — prohibitively expensive. Furthermore, Transformers use Read-Time Filtering. They store the entire history of the sequence (the Key-Value Cache) and only filter out irrelevant information when they “read” it back via attention. This forces the memory footprint to grow linearly with every new token generated.
Enter Mamba.
Many LLMs are moving towards mix architechture that combines both linear and full attention, take Nemotron-3 for example which also uses Mamba 2’s attention layers.
Mamba is not just an optimization; it is a paradigm shift. It replaces the memory-heavy attention mechanism with a Selective State Space Model (SSM). By introducing a dynamic “gate” (Delta), Mamba learns to selectively remember or forget information token-by-token. The result is a model that matches the Transformer’s accuracy but scales linearly (O(L)), unlocking infinite-context possibilities.
Here is the complete technical story of how Mamba works, from the physics of its memory to the engineering of its parallel algorithms.
The Foundation: State Space Models (SSMs)
Mamba is built on State Space Models (S4), a concept borrowed from control theory (used to describe physical systems like robotic arms or circuits).
An SSM describes a system using a single, compact “hidden state” (h) that evolves over time. Unlike an attention cache, it doesn’t store the history; it stores the current state of the history.
In continuous time, the system is defined by two equations:
h’(t) = Ah(t) + Bx(t)
y(t) = Ch(t)
- The State Equation (h’(t)): This tells us how the memory changes. The new memory is a mixture of the old memory Ah(t) and the new input Bx(t).
- A (The Dynamics Matrix): This is the Retention Filter. It acts on the past. It dictates how long information persists in the state. If A is small, the memory decays quickly. If A is stable, the memory persists.
- B (The Input Matrix): This is the Input Modulator. It acts on the present. It determines how strongly the new input x(t) influences the system.
The Fatal Flaw of the Past (S4):
Previous Deep Learning SSMs, like S4, had a critical weakness: the matrices A and B were static. They were fixed learned parameters shared across the entire sequence.
This meant the model treated every token exactly the same. It used the same retention rate for a crucial proper noun as it did for a filler words like “um.” It was content-agnostic, making it fast but poor at complex language tasks.
The Core Innovation: The Dynamic Delta Gate (∆)
Mamba’s breakthrough is the Selective SSM (S6). It makes the system content-aware by making the parameters input-dependent.
For every input token x_k, Mamba calculates a dynamic parameter called Delta (∆). This ∆ effectively represents the “step size” or “importance” of the current token.
From Continuous to Discrete (The Discretization):
Computers can’t process continuous time (t), so they process discrete steps (k). We must “discretize” the continuous matrices A and B using ∆. Mamba uses the Zero-Order Hold (ZOH) method to create dynamic, discrete gates:
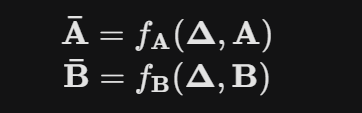
This transformation is where the magic happens. By varying ∆, the model fundamentally changes the physics of its memory.
This dynamic ∆ effectively acts as a time-step parameter. Let’s see how its value translates into the “forget” and “update” decisions — the gates of Mamba.
The discretization process transforms the continuous-time matrices (A and B into discrete-time matrices (Ā and B̅) based on the calculated ∆.
- The transformed matrix Ā serves as the forget gate.
- The transformed matrix B̅ serves as the input (or update) gate.
The Physics of Selection: How Mamba “Skips” and “Resets”
The value of Delta acts as a gatekeeper. We can mathematically prove how it allows Mamba to either preserve memory (skip noise) or overwrite memory (focus on signal).
Scenario A: The “Skip” (Small Delta):
Imagine the model reads a stop word like “the”. It predicts a small ∆ (Close to 0) which makes Ā close to identity matrix.
What do you predict happens to the retention of the old state (Ā) when the time step is very small? Does the memory fade quickly or is it strongly preserved?
The Result: The previous state is multiplied by 1. It is preserved perfectly. The new input is largely ignored. The model effectively skips this token, retaining its context for later.
Scenario B: The “Reset” (Large Delta):
Imagine the model reads a major context shift, like “Chapter 2”. It predicts a large ∆ (Delta to infty) making Ā close to 0.
What do you predict happens to the influence of the current input (Ā) when ∆ is large?
The Result: The old memory is multiplied by 0 (erased). The new input dominates the state. The model overwrites the history to focus entirely on the new, critical information.
This Write-Time Filtering allows Mamba to compress massive amounts of information into a fixed-size state without losing the signal in the noise.
The flow of information in a Mamba block follows this structure:
- Input Projection: The input token vector x_k is projected into a higher-dimensional space.
- Split and Gates: This projected vector is split into two paths
- One path feeds into the Selective SSM layer.
- The second path, called the gating mechanism, is where x_k is used to compute the dynamic parameters: Δₖ, Bₖ, and Cₖ.
- Discretization: The model uses the input-dependent Δₖ to transform the static, learned matrices A and B into the dynamic forget gate (Ā) and input gate (̅B̅).
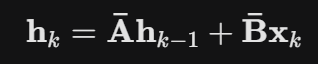
- State Update: The discrete State Equation (shown above) is executed, resulting in the new memory state ̅B.
The Engineering Miracle: The Parallel Scan
We established that Mamba uses a recurrent state (h_k depends on h_{k-1}). In traditional RNNs, this is a disaster for training speed because you cannot calculate step 100 until you have calculated step 99. GPUs hate this; they want to process everything at once (parallelism).
Mamba solves this with the Parallel Scan Algorithm.
The Associative Property:
The researchers observed that the linear update operation of an SSM is associative.
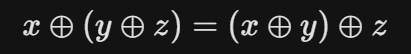
This mathematical property means that even though the process is sequential, we don’t have to calculate it strictly left-to-right. We can group operations together.
The Up-Sweep and Down-Sweep:
Mamba uses a tree-based algorithm (similar to the Blelloch scan):
- Up-Sweep (Parallel Reduction): The model groups adjacent tokens (pairs) and computes their partial updates in parallel. It effectively calculates “what happens from step 1 to 2” and “step 3 to 4” simultaneously 25.
- Down-Sweep: It combines these partial chunks to distribute the correct cumulative state to every position.
The Impact: This reduces the training time complexity from O(L) to O(log L).
This allows Mamba to train just as fast as a Transformer, removing the primary bottleneck that held back previous RNNs.
The Full Anatomy: Inside the Mamba Block
The Selective SSM is the core, but the full “Mamba Block” wraps this engine in a modern neural network architecture designed for performance.
Local Feature Extraction (1D Convolution):
Before the sequence enters the SSM, it passes through a standard 1D Convolution layer.
Why? SSMs are great at global context (the whole book). Convolutions are great at local context (the current sentence). This gives Mamba a “dual focus,” ensuring it doesn’t miss short-range patterns like bigrams.
SiLU Gating (The MLP Replacement):
Mamba replaces the Transformer’s Multi-Layer Perceptron (MLP) with a gating mechanism. It runs a parallel path alongside the SSM and combines them using the SiLU (Sigmoid Linear Unit) activation function.
Why? This provides the necessary non-linearity, allowing the model to learn complex functions that a purely linear SSM cannot.
Conclusion: The Linear Future
Mamba represents a “best of both worlds” breakthrough.
By solving the “Selectivity” problem with dynamic Delta gates and solving the “Training Speed” problem with Parallel Scans, Mamba has proven that we don’t need quadratic attention to model language. We just need a smarter, selective memory.
This architecture opens the door to million-token context windows, allowing AI to read entire genomes, process hours of audio, or memorize whole codebases without running out of memory.
Link to original paper: https://arxiv.org/pdf/2312.00752
Until next time folks…
El Psy Congroo
Mamba: From Intuition to Proof — How Delta-Gated State Space Models challenges the Transformer was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.