
Long Context Compaction for AI Agents — Part 2: Implementation and Evaluation
Long Context Compaction for AI Agents — Part 2: Implementation and Evaluation

The complete implementation is available here
In Part 1, we explored how context grows in agent systems and how Bedrock AgentCore Memory extracts summaries asynchronously.
Your agent has been running for a while. Session memory is full of conversation history. Summarized records are piling up in long-term storage. But the message buffer — what actually gets sent to the model — still loads everything from session memory. Every message, every tool result, growing with each turn.
Our goal: non-blocking compaction. Optimize the message buffer at load time, using these pre-computed summaries — without pausing the conversation
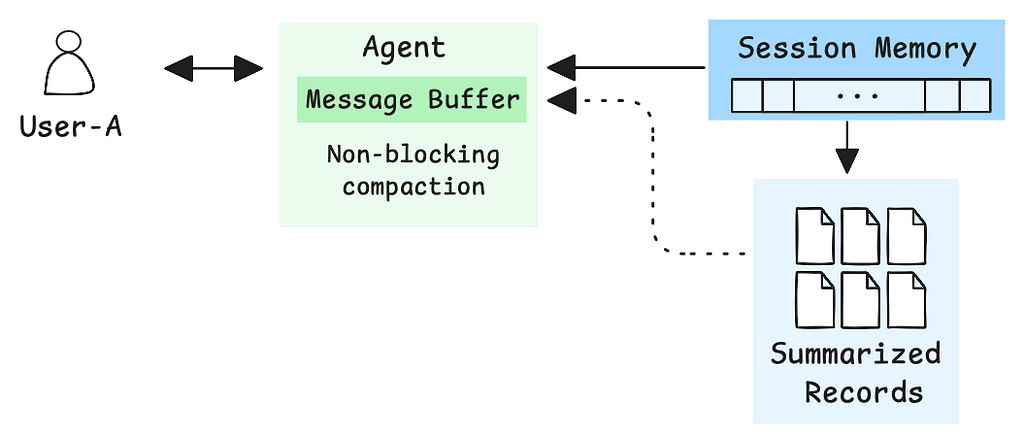
Here’s what those summaries look like after a trip planning conversation:
<topic name="Trip Planning">
The user is planning a trip to Hawaii for next month and has
inquired about weather, beaches, hotels, and attractions.
</topic>
<topic name="Budget-Friendly Activities in Hawaii">
Free beaches: Waikiki Beach, Kailua Beach Park (4.8★)
Free cultural events: Kuhio Beach Torchlighting & Hula Show
Free hiking: Manoa Falls Trail, Pali Notches Ridge
</topic>
The pieces are in place. Now let’s connect them.
How It Works
We apply two levels of optimization:
Truncation is the first line of defense. Tool outputs — API responses, search results, scraped pages — are often verbose, but their useful content has already been distilled into the assistant’s response. We compress these in older messages while keeping recent turns intact. This runs every turn with minimal overhead.
Summarization kicks in when truncation isn’t enough. Even after compressing tool outputs, the conversation itself grows. When token usage still exceeds the threshold, we set a checkpoint — on subsequent turns, we load only recent messages after the checkpoint with pre-computed summaries covering everything before it. The model sees enough context to stay coherent, without the full verbose history.
A few design choices:
- Single source of truth: Session memory (short-term memory in AgentCore Memory) holds the complete conversation history. We don’t modify it — instead, we build optimized context at initialization using compaction state. Any server can resume any session by reading from the same source and applying the same compaction logic.
- Stable context: We optimize at a threshold, then maintain that context until the next. The model sees a consistent conversation history between compactions, making behavior more predictable. It also enables prompt caching — the prefix stays identical across turns, so cached tokens can be reused.
- Token-based threshold: Some implementations compact reactively — only when context overflow actually occurs. Proactive approaches often use message count as a trigger, but a single turn can trigger multiple tool calls, and token usage per tool varies widely. We track actual token count reported by the model after each turn, triggering compaction when it crosses a threshold.
Let’s look at how this translates to code.

The Compacting Manager
The CompactingSessionManager extends the AgentCoreMemorySessionManager and hooks into the agent lifecycle at two points: turn completion and initialization.
class CompactingSessionManager(AgentCoreMemorySessionManager):
def __init__(
self,
agentcore_memory_config: AgentCoreMemoryConfig,
token_threshold: int = 50_000, # Trigger checkpoint when exceeded
protected_turns: int = 2, # Recent turns to protect
max_tool_content_length: int = 500, # Max chars before truncating tool output
...
):
The compaction state is persisted to DynamoDB:
@dataclass
class CompactionState:
lastInputTokens: int = 0 # Context size from previous turn
checkpoint: int = 0 # Message index to load from (0 = load all)
summary: Optional[str] = None # Pre-computed summary for skipped messages
The agent uses CompactingSessionManager like any other session manager:
session_manager = CompactingSessionManager(
agentcore_memory_config=config,
token_threshold=50_000,
...
)
agent = Agent(
model=model,
session_manager=session_manager,
...
)
At each turn, the manager syncs compaction state with DynamoDB, loads conversation history from session memory, applies compaction, and builds the message buffer for the agent’s prompt.
1. Turn Completion: Tracking Context Size
At turn completion, we update the compaction state based on the actual token usage. The input token count comes from the model’s response metadata — this gives us precise measurement of how much context was sent.
# After streaming completes
input_tokens = stream_processor.last_usage.get('inputTokens', 0)
session_manager.update_after_turn(input_tokens, agent.messages)
Inside update_after_turn, we record the token count (=context size) and check if checkpointing is needed:
def update_after_turn(self, input_tokens: int, current_messages: List[Dict]) -> None:
self.compaction_state.lastInputTokens = input_tokens
if input_tokens > self.token_threshold:
# Find checkpoint index (keeps recent protected_turns)
checkpoint = self._find_checkpoint_index(current_messages)
self.compaction_state.checkpoint = checkpoint
# Retrieve pre-computed summaries from AgentCore LTM
self.compaction_state.summary = self._retrieve_summaries()
self.save_compaction_state(self.compaction_state)
When token usage exceeds the threshold, we set a checkpoint —a marker in the conversation history that determines where to cut on the next load. We also retrieve pre-computed summaries from AgentCore Memory’s LTM to cover the conversation before the checkpoint.
The threshold is configurable — it determines how much context window your service provides per session. Larger context means higher latency, higher cost, and potentially degraded reasoning quality. The sensitivity varies by model, so the right threshold depends on your agent’s task complexity and how much conversation history needs to stay fully intact.
The state is saved to DynamoDB after every turn, ready for the next initialization.
2. Turn Initialization: Applying Compaction
When a new turn starts, the initialize() method builds the message buffer using the compaction state. The strategy depends on where we are in the conversation:
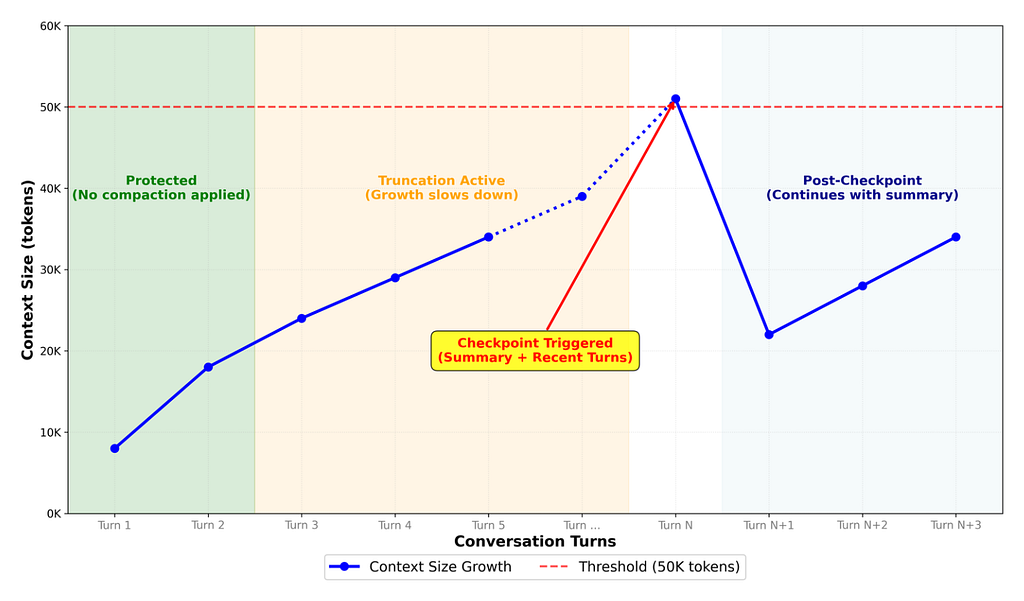
Protected (Turn 1–2): No compaction applied. Recent turns need full context for the model to reason about — truncating or summarizing them would break coherence.
Truncation Active (Turn 3+): We compress verbose tool outputs in older messages — API responses, search results, scraped pages. These are often large but their useful content has already been extracted into the assistant’s response. Recent turns stay intact. This slows context growth without losing conversational flow.
Post-Checkpoint: When token usage exceeds the threshold, we load only messages after the checkpoint, with the pre-computed summary prepended. Old verbose history is replaced by a compact summary. Context drops significantly, then continues growing until the next threshold.
We’ll verify these patterns empirically in the Evaluation section. The message structure evolves through these stages:
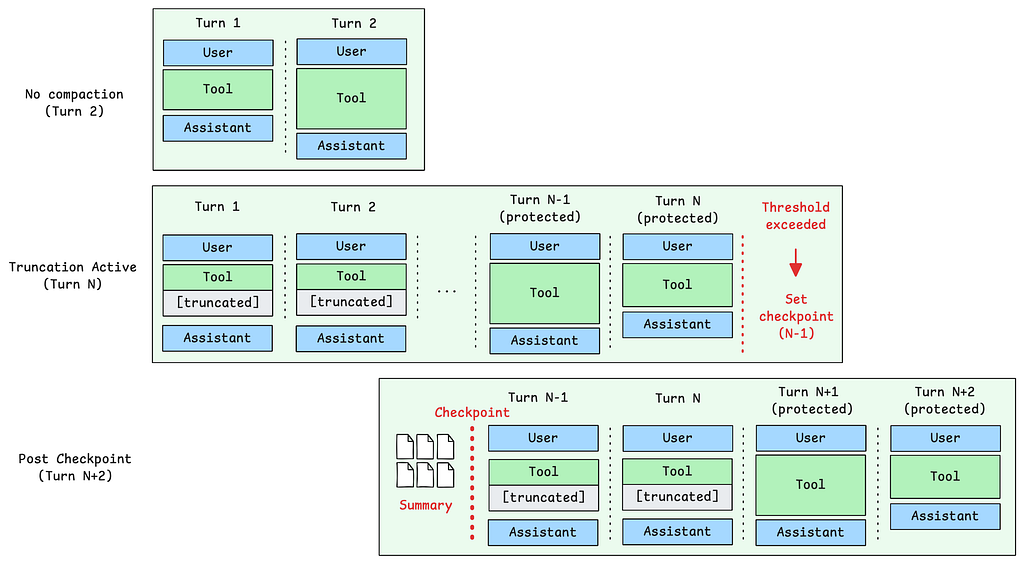
Notice that even after checkpoint, truncation continues to apply — Turn N-1 and Turn N show [truncated] markers while the most recent turns (N+1, N+2) remain protected.
Here’s how initialize() implements this:
def initialize(self, agent: "Agent", **kwargs: Any) -> None:
# Load compaction state from DynamoDB
self.compaction_state = self.load_compaction_state()
checkpoint = self.compaction_state.checkpoint
# Load messages from Session Memory
all_messages = self.session_repository.list_messages(
session_id=self.session_id,
agent_id=agent.agent_id
)
# Apply checkpoint: skip old messages, prepend summary
if checkpoint > 0:
messages = all_messages[checkpoint:]
if self.compaction_state.summary:
messages = self._prepend_summary(messages, self.compaction_state.summary)
else:
messages = all_messages
# Apply truncation (protect recent turns)
protected = self._find_protected_indices(messages, self.protected_turns)
agent.messages = self._truncate_tool_contents(messages, protected)
The flow is straightforward: load compaction state, apply checkpoint offset if set, prepend summary for context, then truncate old tool outputs while keeping recent turns intact.
Evaluation Setup
We tested compaction with two agent types across 30-turn conversations:
- Finance Agent: stock quotes, portfolio analysis, market news, transaction history (ref: Link)
- Travel Agent: web search, flight search, attraction lookup (ref: Link)
Both represent realistic workloads where tool outputs are verbose and context grows quickly. The Finance Agent handles more complex analytical queries, resulting in longer reasoning chains and more tool call iterations per turn.
Metrics
- Context Size: Total tokens in the prompt sent to the model — system prompt, conversation history, and current message combined.
- Cost: Calculated from accumulated input tokens across all model calls within each turn. Agents often make multiple calls per turn (reasoning → tool call → result → more reasoning). Priced at $0.001 per 1K input tokens (Claude 4.5 Haiku — Link).
- Latency: Wall-clock time to complete each turn.
- Overhead: Additional time for compaction during initialization.
- Retention: After 30 turns, we asked each agent to summarize the full conversation and measured coverage of information from all 30 questions.
Results
Context Size: Baseline vs Compaction
We ran 30 turns on the Finance Agent — one with no optimization (baseline), one with compaction enabled (protected_turns=2, threshold=50K).

Without compaction, context grows until it hits the model’s input token limit. Compaction grounds it within a configured threshold — and the savings compound over time: 35% reduction at turn 5, 54% at turn 15, 71% at turn 30. The longer the conversation, the greater the impact.
The right chart shows the three phases in action:
- Protected (Turn 1–2): No optimization applied.
- Truncation Active (Turn 3–21): Old tool outputs compressed, slowing growth. Baseline crossed 50K at turn 13(53.1K), while with truncation it took until turn 20 (53.4K) — buying 7 extra turns before checkpoint was needed.
- Post-Checkpoint (Turn 22+): Context exceeded 50K, triggering checkpoint. Only recent messages loaded with summary prepended. Context drops to 29.7K from 53.4K, then grows again until the next checkpoint around turn 24. Notice the repeated drops in the Post-Checkpoint phase — each time context approaches the threshold, a new checkpoint is set, keeping context bounded.
Cost: Baseline vs Compaction
Context size savings translate directly to cost. Each turn accumulates input tokens across multiple model calls — reasoning, tool calls, results, more reasoning — so bounded context has a multiplier effect.

Over 30 turns, baseline consumed 5.16M input tokens while compaction used 1.69M — 67% savings. The chart shows these converted to cost at Claude 3.5 Haiku pricing ($0.001 per 1K tokens): $5.16 vs $1.69 per session.
Threshold and Agent Type
Different workloads require different thresholds. We tested both agents at 25K and 50K to see how compaction behavior varies.

Finance Agent generates complex analytical queries with extensive tool outputs. At 50K threshold, checkpoint compaction keeps context bounded effectively. But at 25K, context couldn’t stay grounded — summaries accumulated so heavily that even (recent 2 turns + summary) exceeded 25K, triggering repeated checkpoints with diminishing returns.
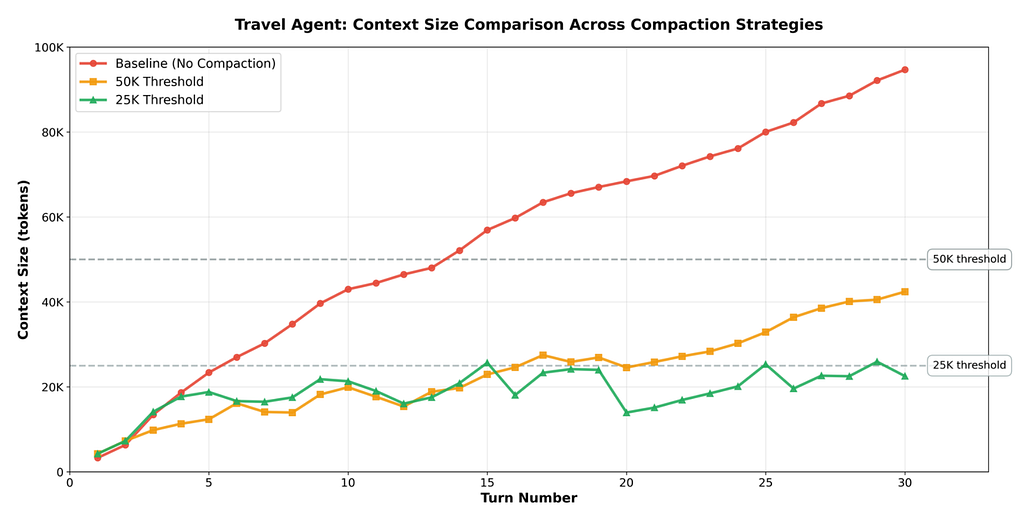
Travel Agent follows simpler query-response patterns. At 50K threshold, truncation alone was sufficient — checkpoint never triggered within 30 turns. At 25K, checkpoint compaction kicked in effectively at turns 15, 19, 25, and 29, keeping context well-bounded around the threshold.
The takeaway: optimal threshold depends on task complexity — how much reasoning the agent performs, how verbose its responses are, and how much tool output accumulates per turn. Tune the threshold to match your workload.
Overhead and Latency
Compaction adds minimal overhead. Initialization — loading compaction state, applying checkpoint offset, truncating tool outputs — averaged under 7ms per turn, negligible compared to model inference time.
Latency varied more by response length than context size. Average turn completion time was 35.9s for baseline and 35.2s for compaction — within margin of error. The model’s variable output length dominated latency, not the input context optimization.
Retention
Does compaction preserve conversational memory? After 30 turns, we asked each agent to summarize the entire conversation and measured how much information was retained.
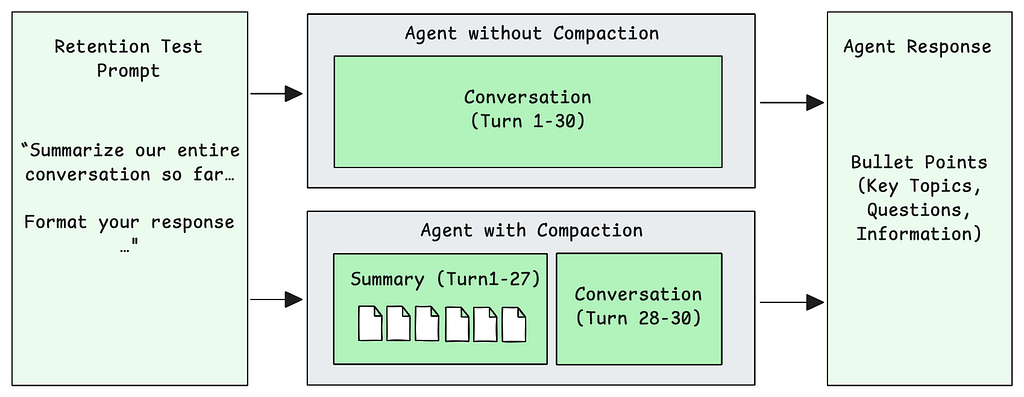
The baseline agent has the full conversation in context — 181K tokens for Finance, 97K for Travel — well beyond optimal attention range. The compacted agent has summaries of earlier turns plus recent messages, bounded around the configured threshold.
We compared each agent’s summary against the original 30 user questions, checking whether key information from each question was captured in the response.
Finance Agent (baseline 181K → compacted ~50K):
- Baseline: 265 bullet points, covered 27/32 questions (84%)
- Compaction: 722 bullet points, covered 32/32 questions (100%)
Travel Agent (baseline 97K → compacted ~25K):
- Baseline: 252 bullet points, covered 26/30 questions (87%)
- Compaction: 366 bullet points, covered 29/30 questions (97%)
Both agents showed better retention with compaction enabled. The baseline missed questions from early and middle portions of the conversation — exactly where “lost in the middle” effects are strongest. For example, Finance baseline missed AAPL 1-month price history (turn 3) and NVDA detailed stock history (turn 11), while Travel baseline omitted Shibuya district details (turn 9) and Paris attractions (turn 14).
This suggests summarization-based compaction does more than save tokens — it has a denoising effect. By distilling earlier conversation into structured summaries, the model maintains clearer access to key points instead of searching through verbose tool outputs and intermediate reasoning.
Conclusion
Context compaction isn’t just about fitting within token limits — it’s about maintaining conversation quality as sessions grow longer.
The approach we’ve covered:
- Truncation compresses verbose tool outputs while protecting recent turns
- Checkpoint-based summarization replaces old history with compact summaries when thresholds are exceeded
- Token-based tracking triggers compaction proactively, before context overflows
In our tests, this reduced token usage by 67% while improving retention from 84% to 100%. The model produced more detailed, more accurate summaries with bounded context than with the full 180K token history.
This completes our two-part series. Part 1 covered the design principles — why context explodes and how AgentCore Memory extracts summaries asynchronously. Part 2 showed how to apply those summaries at load time for non-blocking compaction.
The implementation is available at Github:
- Link1: Implemented CompactingSessionManager
- Link2: Testing and Measurement Script for Finance Agent and Travel Agent
Long Context Compaction for AI Agents — Part 2: Implementation and Evaluation was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.