
LLM Tokenizers, Semantic Search Course, And book update #2
Hi there, Jay here again with updates from LLM land!
I’ve recently put together a bunch of videos and collaborated with some of my ML heros to create a course about semantic search with LLMs on Deeplearning AI. Here’s a run down of them, and and update about our upcoming book.
Video: ChatGPT has Never Seen a SINGLE Word (Despite Reading Most of The Internet). Meet LLM Tokenizers
Despite processing internet-scale text data, large language models never see words as we do. Yes, they consume text, but another piece of software called a tokenizer is what actually takes in the text and translates it into a different format that the language model actually operates on. In this video, Jay goes examines a language model tokenizer to give you a sense of how they work.
Video: What makes LLM tokenizers different from each other? GPT4 vs. FlanT5 Vs. Starcoder Vs. BERT and more
One of the best ways to understand what tokenizers do is to compare the behavior of different tokenizers. In this video, Jay takes a carefully crafted piece of text (that contains English, code, indentation, numbers, emoji, and other languages) and passes it through different trained tokenizers to reveal what they succeed and fail at encoding, and the different design choices for different tokenizers and what they say about their respective models.
Course: New course with Cohere: Large Language Models with Semantic Search
It was incredible to collaborate with my heros, Luis Serrano, Meor Amer, and Andrew Ng on this short course. Enrol here: https://bit.ly/3OLOEzo
Here’s what you can expect:
– Understand LLM Fundamentals: Deepen your understanding of how large language models work, equipping you to become a more proficient AI builder.
– Enhance Keyword Search: Learn to integrate ReRank, a tool that boosts the quality of keyword or vector search systems without overhauling existing frameworks.
– Leverage Dense Retrieval: Discover how to use embeddings and large language models to enhance Q&A capabilities in your search applications.
– Evaluate and Implement: Gain insights into evaluating your search models and efficiently implementing these techniques in your projects.
– Real-World Application: Work with the Wikipedia dataset to understand how to optimize processes like retrieval and nearest neighbors, providing practical experience with large data sets.
By the end of the course, you will gain a deeper understanding of the fundamentals of how Large Language Models (LLMs) work, enhancing your skills as an AI developer.
Book update

We are working hard on writing Hands-On Large Language Models. It is currently on Early Release on the O’Reilly platform with five chapters (150 pages) available now:
1. Categorizing Text
2. Semantic Search
3. Text Clustering And Topic Modeling
4. Multimodal Large Language Models
5. Tokens & Token Embeddings
Access the Early Release version of the book with a 30-day free trial: https://learning.oreilly.com/get-learning/?code=HOLLM23
Coming up next to the book: The Illustrated Transformer Revisited
Maarten (my co-author) and I have a bunch of chapters in review that are not yet in the Early Release but should be coming in the next few weeks. The one I just finished is titled “A Look Inside Transformer LLMs”. It’s basically revisiting The Illustrated Transformer with the major updates to The Transformer Architecture in the last five years. But it’s focused on text generation LLMs (autoregressive models generating one token at a time).
That chapter contains 39 new figures and I believe explains self-attention in the clearest formulation I know of. Here are some teaser visuals:
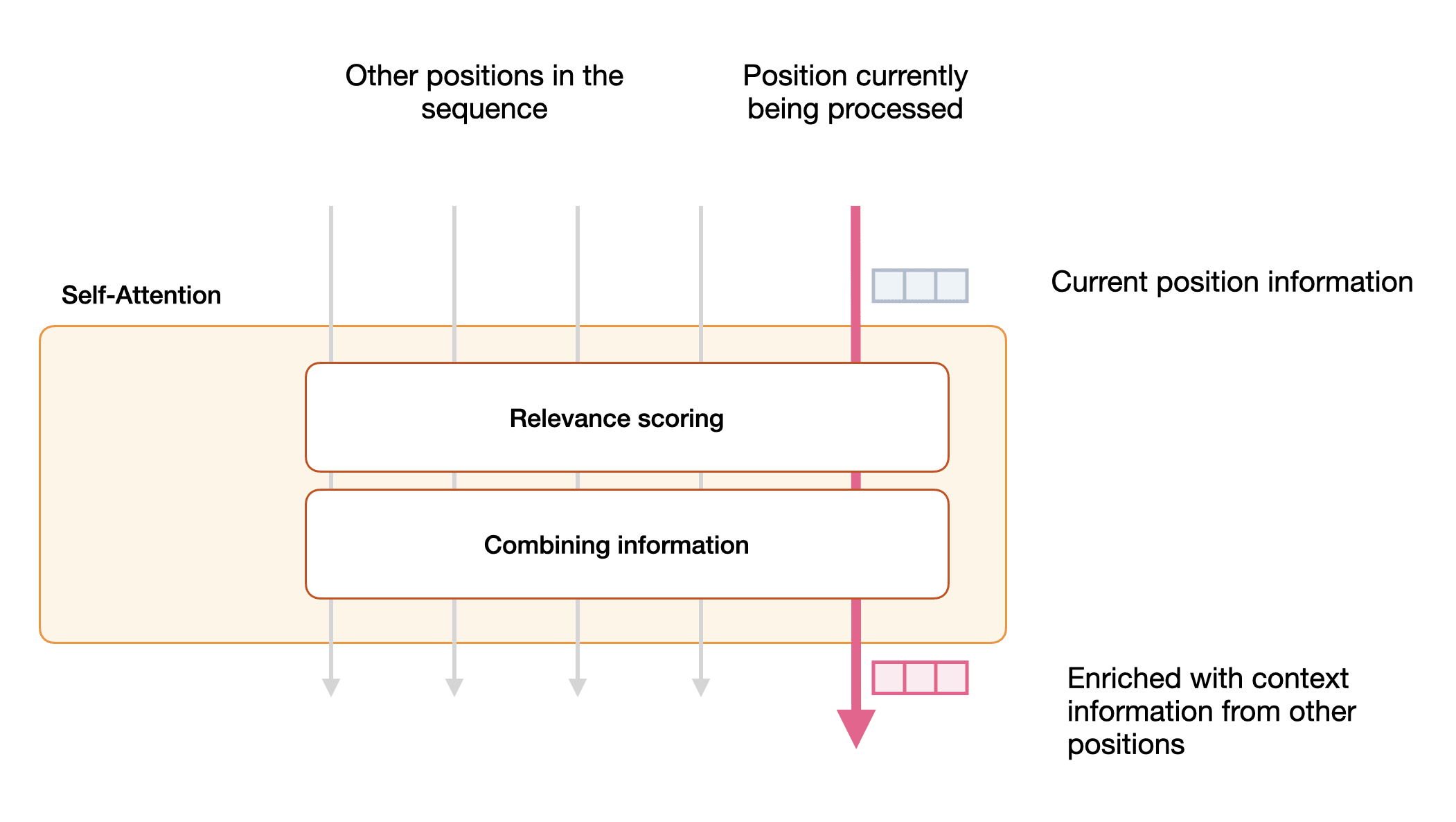
The two major steps for self-attention
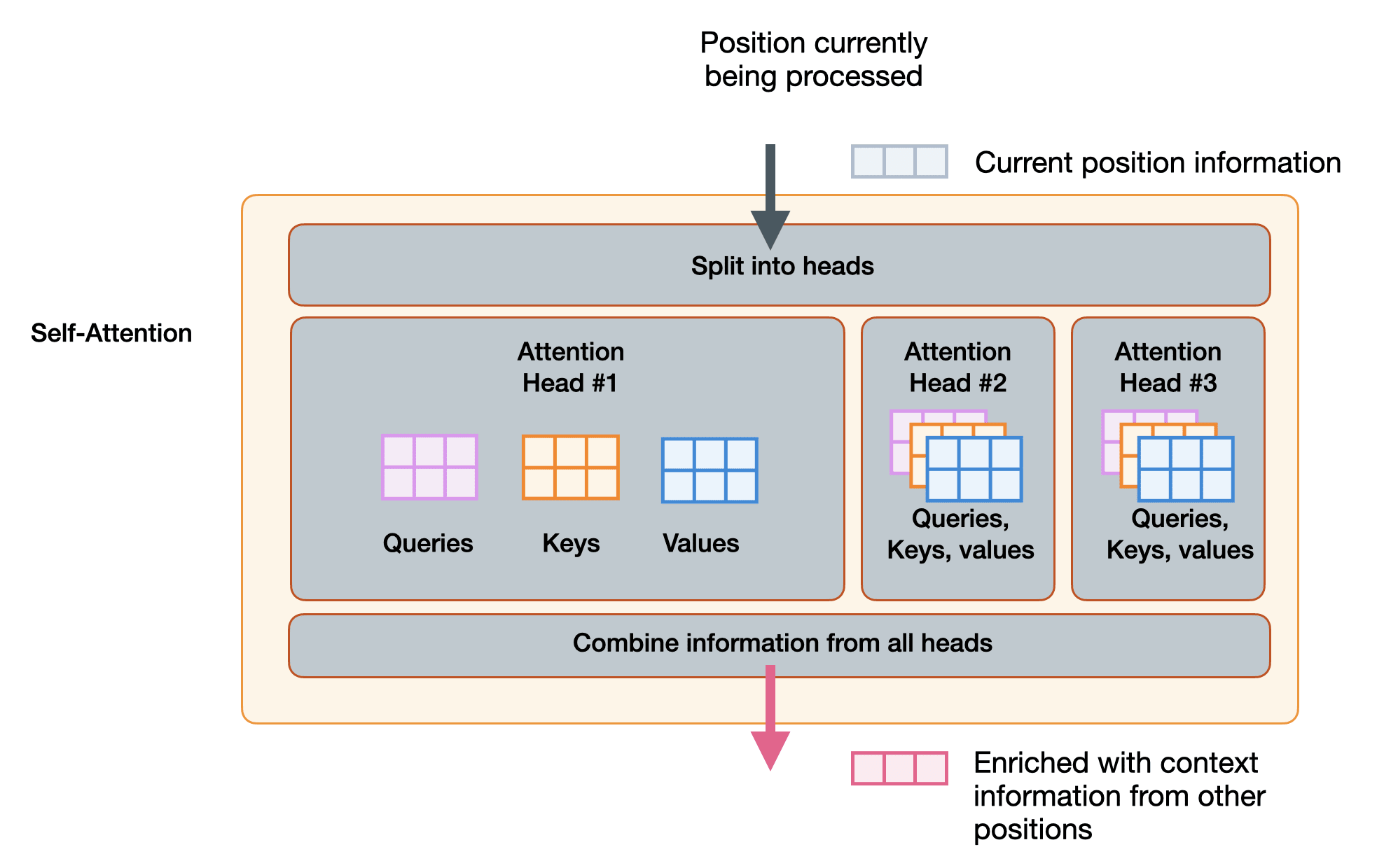
The queries, keys, values of multi-head self-attention
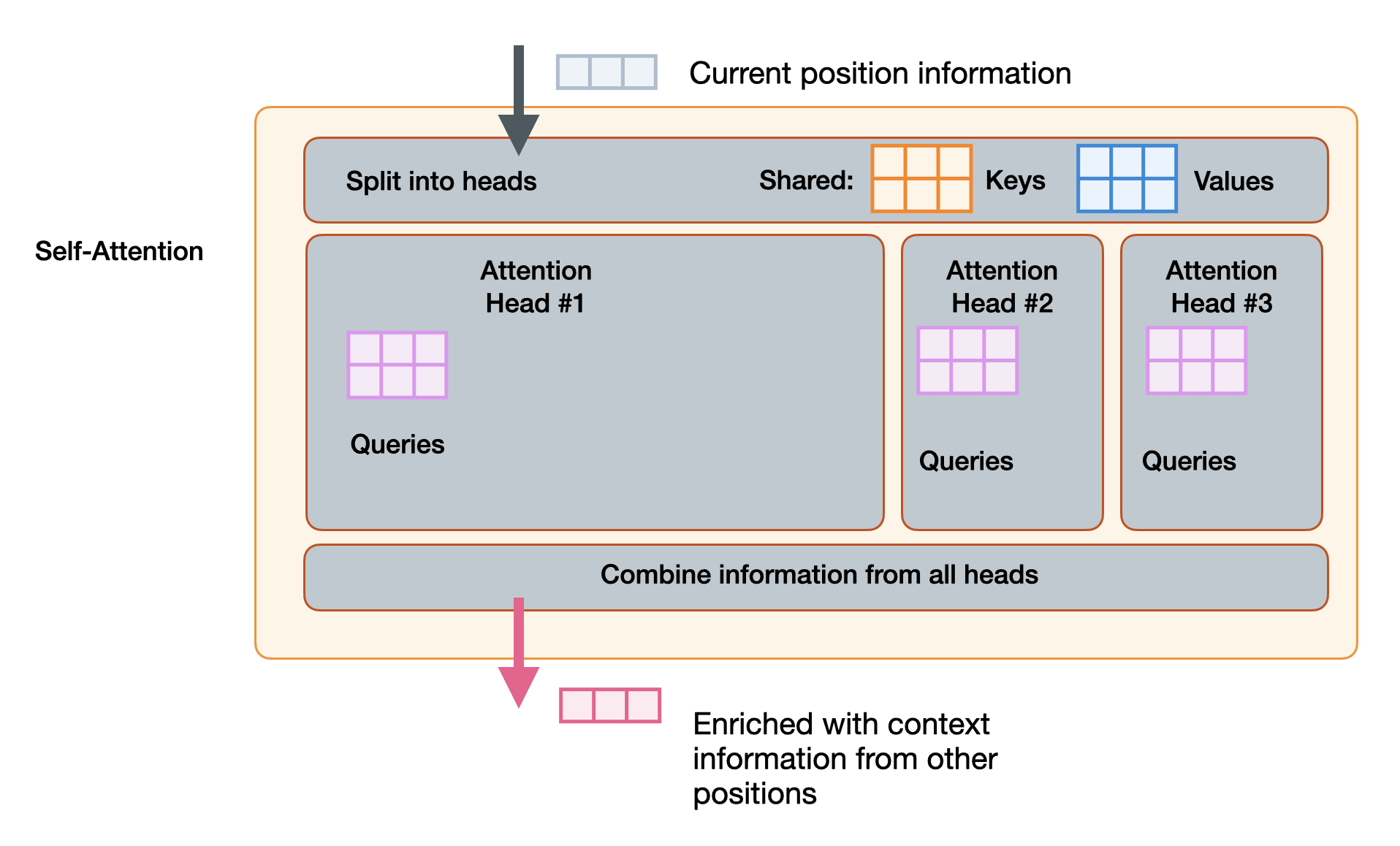
The more efficient multi-query attention — heads have their individual queries but share keys and values. (Paper: Fast Transformer Decoding: One Write-Head is All You Need)
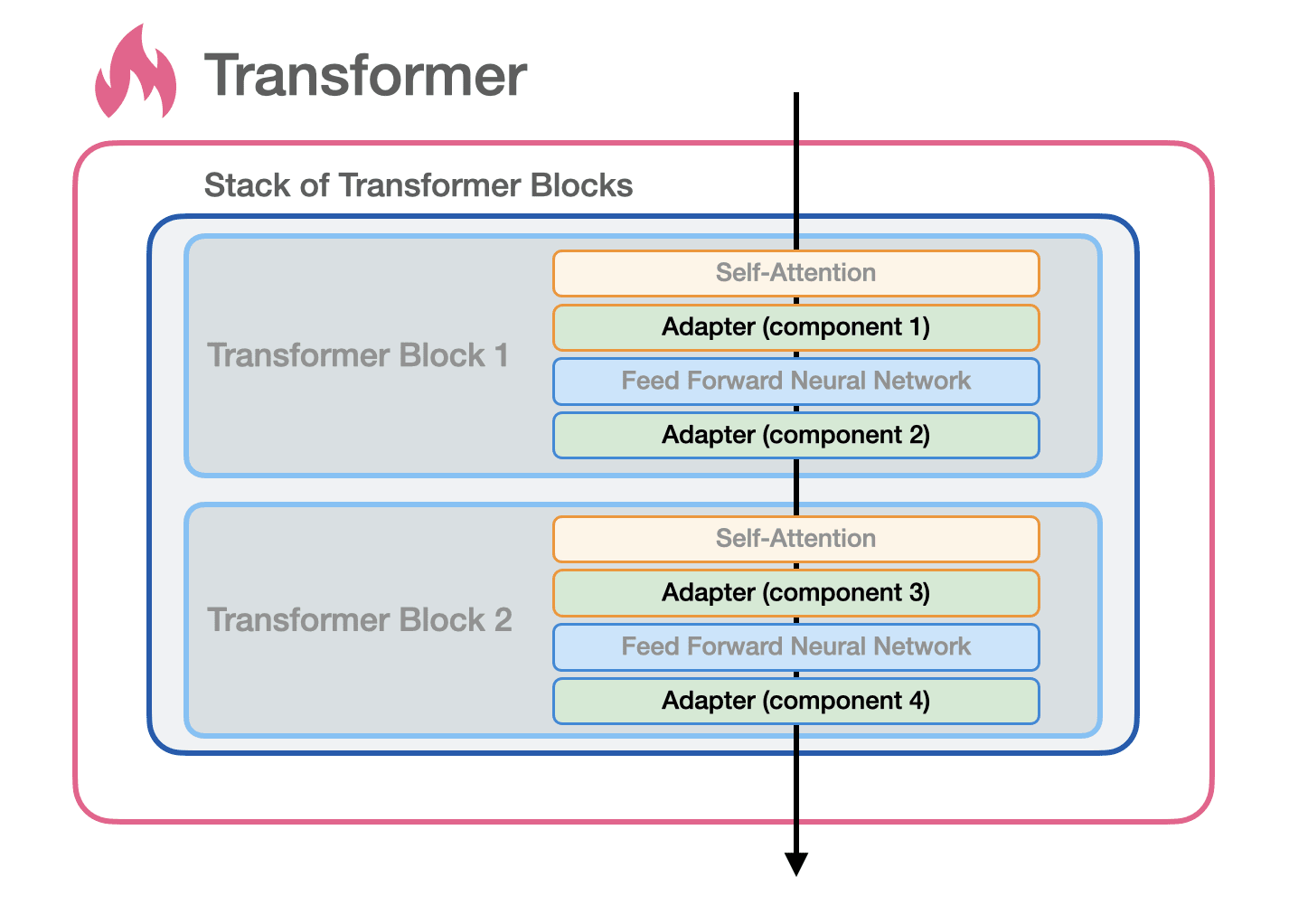
Transformer adapters are one approach to efficient fine-tuning
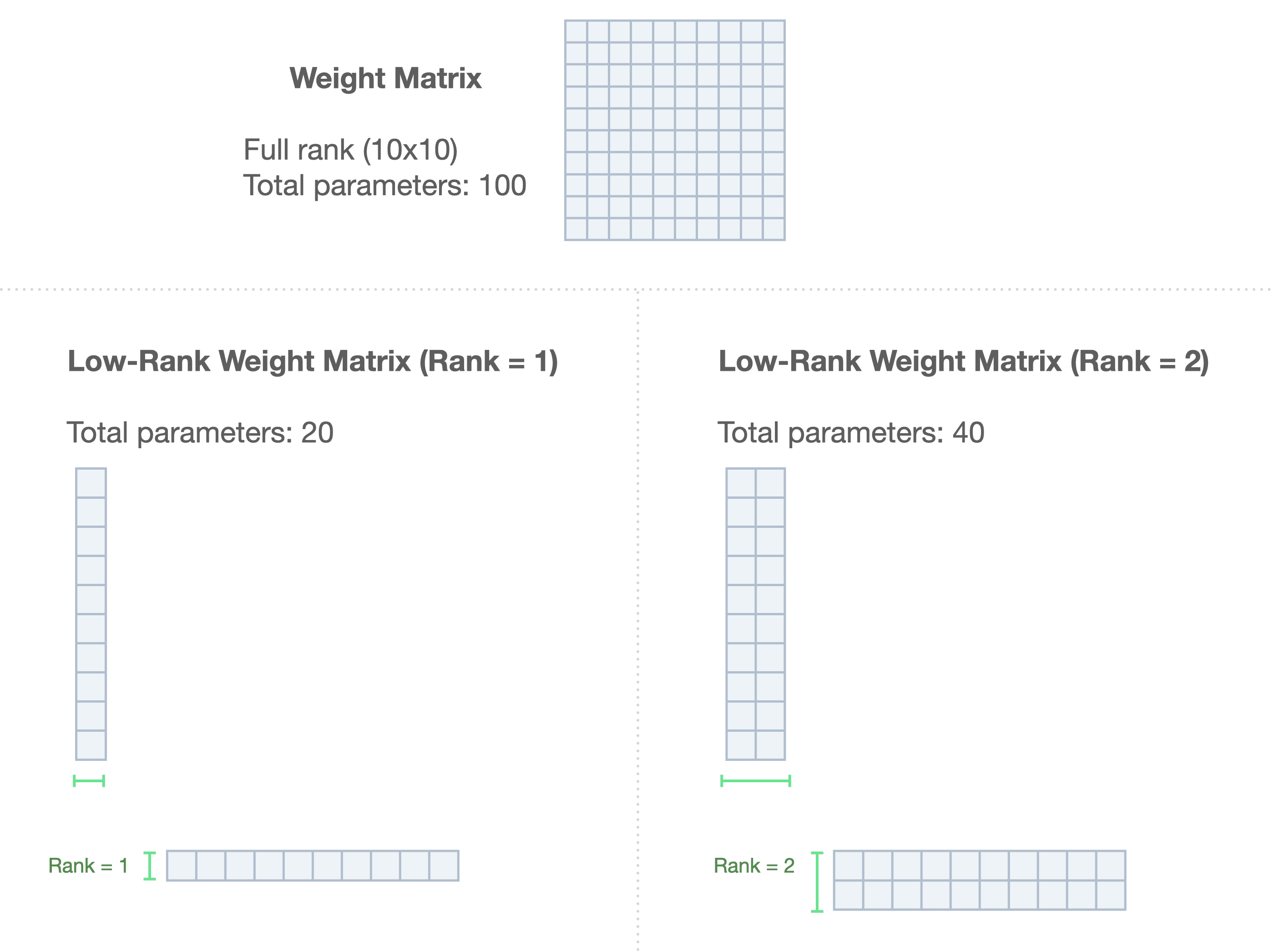
Low-Rank adaptation, or LoRA is another method of efficient fine-tuning that relies on reducing large weight matrices to smaller, lower-rank matrices which are often able to compress the size and required storage/memory/compute while maintaining close performance. It works because language models “have a very low intrinsic dimension”. So an efficient version of a 175B model can do a lot with rank = 8, for example. That vastly reduces the size of the matrix and the time needed to fine-tune those parameters
Video: Introducing KeyLLM – Keyword Extraction with Mistral 7B and KeyBERT
Maarten, my co-author, has been creating some excellent LLM software and videos that explain them.
In this video, I’m proud to introduce KeyLLM, an extension to KeyBERT for extracting keywords with Large Language Models! We will use the incredible Mistral 7B LLM and go through several use cases.
…
That’s it for this update. Still a bunch more exciting things coming up I can’t tell you about just yet, so stay tuned!