
LLM & AI Agent Applications with LangChain and LangGraph — Part 27: The Publisher Agent (News →…
LLM & AI Agent Applications with LangChain and LangGraph — Part 27: The Publisher Agent (News → Summary → Article → Critic → Improve)

Hi. In this part I’ll run and demonstrate a publisher agent — a system that autonomously aggregates news from the web, summarizes the most important points, and then generates an article based on that material.
We’ll build it in LangGraph, so in the form of a state graph: with nodes, edges, conditions, and a loop. You’ll see how to combine planning, tool calls, and critic feedback into one coherent workflow.
What exactly will our “publisher” do?
Think of it as a simplified editorial team.
The agent will first try to gather material — it will call a search tool — and once it decides it has enough reliable information, it will move to writing the article. At the end it will invite a critic for feedback. Based on that feedback, the article will be improved and returned in its final form.
Planning and quality criteria are the core
It’s worth highlighting planning and quality criteria, because this is the heart of agentic applications.
The agent doesn’t blindly go from A to Z. It plans: chooses a mode, evaluates intermediate results, and adapts its strategy. For example, if the first query returns two mediocre results, it will try a different phrase or search a different source.
Typical challenges
A few challenges show up almost every time:
1) Freshness
Not every tool returns the newest material, so in prompts and search parameters it’s smart to specify a date range.
2) Stability
Sometimes a tool fails or returns an empty list. The agent should have a fallback and retry.
3) Hallucinations
That’s why the first step shouldn’t be “invent something”, but rather “build a summary from specific results and include sources”.
4) Cost and limits
In longer sessions it’s worth limiting conversation history and using sensible model settings — so the bill doesn’t explode.
What we will build
A three-stage Publisher graph:
- Researcher queries Tavily and returns grounded notes.
- Author writes (or rewrites) the article draft.
- Critic evaluates the draft, either approving or asking the Author to revise (looping once more).
- A recursion limit caps total steps to avoid runaway loops.
Hands-On: the Publisher Workflow
1) Install libraries
%%capture --no-stderr
%pip install -U langchain_core langchain_openai langgraph langgraph-supervisor langchain-tavily "langchain[openai]"
!apt install libgraphviz-dev
!pip install pygraphviz
- Install LangChain cores, LangGraph (graph engine), langgraph-supervisor helpers, and langchain-tavily for research.
- The “[openai]” extra pulls the OpenAI chat client (swap providers as needed).
- We prefer this low-level stack for maximum flexibility (custom state, edges, and stops).
2) Load environment variables
from dotenv import load_dotenv
load_dotenv()
Load API keys from .env (e.g., OPENAI_API_KEY, TAVILY_API_KEY). Keep secrets out of source control.
3) Connect to Tavily Search API
from langchain_tavily import TavilySearch
web_search = TavilySearch(max_results=3)
web_search_results = web_search.invoke("Who is the prime minister of Poland?")
print(web_search_results["results"][0]["content"])
output:
The incumbent and eighteenth prime minister is Donald Tusk of the Civic Platform party who replaced Mateusz Morawiecki following the 2023 Polish parliamentary
Create a TavilySearch tool and execute a query; returns structured JSON with concise content fields—ideal for LLM consumption. It’s the official LangChain integration for Tavily.
4) Pretty-printing helpers
(you can skip this section unless somehow you find it interesting 😉
from langchain_core.messages import convert_to_messages
def pretty_print_message(message, indent=False):
pretty_message = message.pretty_repr(html=True)
if not indent:
print(pretty_message)
return
indented = "n".join("t" + c for c in pretty_message.split("n"))
print(indented)
def pretty_print_messages(update, last_message=False):
is_subgraph = False
if isinstance(update, tuple):
ns, update = update
# skip parent graph updates in the printouts
if len(ns) == 0:
return
graph_id = ns[-1].split(":")[0]
print(f"Update from subgraph {graph_id}:")
print("n")
is_subgraph = True
for node_name, node_update in update.items():
update_label = f"Update from node {node_name}:"
if is_subgraph:
update_label = "t" + update_label
print(update_label)
print("n")
messages = convert_to_messages(node_update["messages"])
if last_message:
messages = messages[-1:]
for m in messages:
pretty_print_message(m, indent=is_subgraph)
print("n")
def _name_and_content(msg):
if isinstance(msg, dict):
return msg.get("name", msg.get("role", "user")), msg.get("content", str(msg))
if isinstance(msg, BaseMessage):
name = getattr(msg, "name", None) or getattr(msg, "type", "user")
return name, msg.content
return "user", str(msg)
Add handy printers so you can watch the conversation per node while streaming.
5) Researcher agent node
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
def research_agent_node(state):
messages = state["messages"]
user_request = messages[0].content # BaseMessage OK
search_results = web_search.invoke(user_request)
research_content = []
for result in search_results["results"][:3]:
research_content.append(f"Source: {result['url']}nContent: {result['content']}n")
research_text = "n---n".join(research_content)
research_prompt = ChatPromptTemplate.from_messages([
("system", """You're the Researcher. You have access to fragments from the 'search engine' (RESEARCH).
Your goal is to provide factual, concise facts and data supporting the topic.
Refer to the fragments and do not invent. Write concretely and briefly.
After you finish your task, respond directly to the moderator.
Reply using only the results of your work, do not include the text."""),
("user", "Topic: {topic}nnSearch results:n{research_data}")
])
model = ChatOpenAI(model="gpt-4", temperature=0)
chain = research_prompt | model | StrOutputParser()
response = chain.invoke({"topic": user_request, "research_data": research_text})
return {"messages": [{"role": "assistant", "content": response, "name": "research_agent"}]}
- Run Tavily, composes grounded fragments, and prompts a Researcher LLM to synthesize concise notes (no hallucinations, no extra fluff).
- Return a single assistant message named “research_agent”; LangGraph will route it to the next node
6) Author agent node
from langchain_core.messages import BaseMessage
def _name_and_content(msg):
if isinstance(msg, dict):
return msg.get("name", msg.get("role", "user")), msg.get("content", str(msg))
if isinstance(msg, BaseMessage):
name = getattr(msg, "name", None) or getattr(msg, "type", "user")
return name, msg.content
# fallback
return "user", str(msg)
def author_agent_node(state):
messages = state["messages"]
has_critic_already_intervened = state.get("critic_marked", False)
if has_critic_already_intervened:
author_prompt = ChatPromptTemplate.from_messages([
("system", """You're the Expert-Editor. You have already received feedback from the Critic and you must improve your text.
Analyze the critic's comments and provide a revised version of the article that addresses their concerns.
Include all suggestions and fill in the indicated gaps. Write concretely.
After you finish your task, respond directly to the moderator.
Reply using only the results of your work, do not include the text."""),
("user", "Conversation history:n{conversation_history}nnRevise the article taking into account the critic's feedback.")
])
else:
author_prompt = ChatPromptTemplate.from_messages([
("system", """You're the Expert. From the available facts, propose a practical solution/plan.
Include steps, requirements, and a minimal set of decisions. Write concretely.
After you finish your task, respond directly to the moderator.
Reply using only the results of your work, do not include the text."""),
("user", "Based on the research, create an article:n{conversation_history}")
])
conversation_history = "n".join(
f"{_name_and_content(m)[0]}: {_name_and_content(m)[1]}"
for m in messages
)
model = ChatOpenAI(model="gpt-4", temperature=0)
chain = author_prompt | model | StrOutputParser()
response = chain.invoke({"conversation_history": conversation_history})
return {"messages": [{"role": "assistant", "content": response, "name": "author_agent"}]}
- If the Critic has already weighed in, the Author acts as an Expert-Editor, revising based on feedback.
- Otherwise, the Author drafts the first pass from the research.
- The whole conversation history is packed so the Author can reference prior turns.
7) Critic agent node + stop/loop signal
def critic_agent_node(state):
messages = state["messages"]
conversation_history = "n".join(
f"{_name_and_content(m)[0]}: {_name_and_content(m)[1]}"
for m in messages
)
critic_prompt = ChatPromptTemplate.from_messages([
("system", """You're the Critic. Your role is to find gaps, risks, and ambiguities in the proposal.
Ask probing questions and point out missing elements. Be constructive.
After analyzing the author's work, if you see significant gaps or problems, end your response with the words: "needs improvement"
If the work is satisfactory and does not require significant corrections, end with the words: "approved"
After you finish your task, respond directly to the moderator.
Reply using only the results of your work, do not include the text."""),
("user", "Analyze the author's work:n{conversation_history}")
])
model = ChatOpenAI(model="gpt-4", temperature=0)
chain = critic_prompt | model | StrOutputParser()
response = chain.invoke({"conversation_history": conversation_history})
updates = {
"messages": [{"role": "assistant", "content": response, "name": "critic_agent"}]
}
if not state.get("critic_marked", False):
updates["critic_marked"] = True
return updates
def should_continue(state):
last = state["messages"][-1]
_, content = _name_and_content(last)
content = content.lower()
return "author_agent" if "needs improvement" in content else "end"
- The Critic audits the author’s output and explicitly signals either “approved” (stop) or “needs improvement” (loop).
- The should_continue function reads the last message and decides the next edge.
8) Build the graph
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class WorkflowState(TypedDict):
messages: Annotated[list, add_messages]
critic_marked: bool
supervisor = (
StateGraph(WorkflowState)
.add_node("research_agent", research_agent_node)
.add_node("author_agent", author_agent_node)
.add_node("critic_agent", critic_agent_node)
.add_edge(START, "research_agent")
.add_edge("research_agent", "author_agent")
.add_edge("author_agent", "critic_agent")
.add_conditional_edges("critic_agent", should_continue, {
"author_agent": "author_agent",
"end": END
})
.compile(debug=True)
)
- Declare state and wires a sequence with a conditional loop after the critic.
- compile(debug=True) enables rich step traces for troubleshooting. See the LangGraph Graph API docs for more on state, nodes, and conditional edges.
9) Display the graph
Render a PNG of your graph — handy for docs and graph flow analysis.
from IPython.display import display, Image
display(Image(supervisor.get_graph().draw_png()))
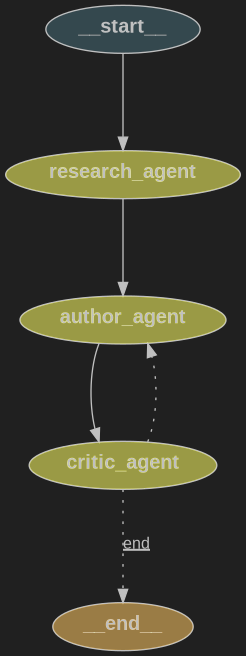
10) Run the graph and generate the article
Now it’s time to run the application and generate article. I enclose full generated texts at the end of this article. Subject is very similar so it may be interesting for you as well 🙂
for chunk in supervisor.stream(
{
"messages": [{
"role": "user",
"content": "Generate an article on the topic: How to build a 'Publisher' agent application based on the LangGraph library",
}],
"critic_marked": False,
},
subgraphs=True,
):
pretty_print_messages(chunk, last_message=True)
output:
[values] {'messages': [HumanMessage(content="Generate an article on the topic: How to build a 'Publisher' agent application based on the LangGraph library", additional_kwargs={}, response_metadata={}, id='233e0228-4746-43e6-a5b7-08c82e480700')], 'critic_marked': False}
[updates] {'research_agent': {'messages': [{'role': 'assistant', 'content': "Building a 'Publisher' agent application based on the LangGraph library involves several steps. LangGraph, an extension of the LangChain framework, is a powerful tool that simplifies the creation of sophisticated, stateful AI agents capable of handling complex tasks. It is designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications.nnLangGraph was launched as a low-level agent framework and has been used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. It builds upon feedback from the super popular LangChain framework and rethinks how agent frameworks should work for production.nnThe process of building an agent with LangGraph involves defining what makes an agent different (or similar) to previous software. This is achieved by understanding the key differences that have been identified through building many agents and working with teams from various companies.nnLangGraph is also used to create stateful, multi-actor AI agents with cyclic workflows. This makes it an ideal tool for building a 'Publisher' agent application. The process involves building a Data Analyst Agent with Streamlit and Pydantic-AI and creating an Agentic AI application using LangGraph.", 'name': 'research_agent'}]}}
[values] {'messages': [HumanMessage(content="Generate an article on the topic: How to build a 'Publisher' agent application based on the LangGraph library", additional_kwargs={}, response_metadata={}, id='233e0228-4746-43e6-a5b7-08c82e480700'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves several steps. LangGraph, an extension of the LangChain framework, is a powerful tool that simplifies the creation of sophisticated, stateful AI agents capable of handling complex tasks. It is designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications.nnLangGraph was launched as a low-level agent framework and has been used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. It builds upon feedback from the super popular LangChain framework and rethinks how agent frameworks should work for production.nnThe process of building an agent with LangGraph involves defining what makes an agent different (or similar) to previous software. This is achieved by understanding the key differences that have been identified through building many agents and working with teams from various companies.nnLangGraph is also used to create stateful, multi-actor AI agents with cyclic workflows. This makes it an ideal tool for building a 'Publisher' agent application. The process involves building a Data Analyst Agent with Streamlit and Pydantic-AI and creating an Agentic AI application using LangGraph.", additional_kwargs={}, response_metadata={}, name='research_agent', id='d110f597-bae6-4087-ac28-51eeadc3dd3e')], 'critic_marked': False}
[updates] {'author_agent': {'messages': [{'role': 'assistant', 'content': "Building a 'Publisher' agent application based on the LangGraph library involves the following steps:nn1. **Understand the LangGraph Library**: Before starting the development process, it's crucial to understand the LangGraph library and its functionalities. LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents.nn2. **Define the Agent's Characteristics**: The next step is to define what makes your 'Publisher' agent different or similar to previous software. This can be achieved by understanding the key differences identified through building many agents and working with teams from various companies.nn3. **Design the Agent's Workflow**: LangGraph is used to create stateful, multi-actor AI agents with cyclic workflows. Therefore, you need to design a cyclic workflow for your 'Publisher' agent. This involves defining the tasks the agent will perform, the order in which they will be performed, and how the agent will transition from one task to another.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit and Pydantic-AI are tools that can be used to build a Data Analyst Agent. Streamlit is an open-source app framework for Machine Learning and Data Science teams. Pydantic-AI is a data validation and settings management using python type annotations.nn5. **Create an Agentic AI Application Using LangGraph**: The final step is to use LangGraph to create an Agentic AI application. This involves integrating the Data Analyst Agent built with Streamlit and Pydantic-AI into the LangGraph framework.nnRequirements:n- Knowledge of the LangGraph library and its functionalitiesn- Understanding of the LangChain frameworkn- Familiarity with Streamlit and Pydantic-AIn- Ability to design and implement cyclic workflowsn- Skills in building AI applicationsnnDecisions:n- The specific characteristics and functionalities of the 'Publisher' agentn- The design of the agent's cyclic workflown- The use of Streamlit and Pydantic-AI in building the Data Analyst Agentn- The integration of the Data Analyst Agent into the LangGraph framework to create an Agentic AI application.", 'name': 'author_agent'}]}}
[values] {'messages': [HumanMessage(content="Generate an article on the topic: How to build a 'Publisher' agent application based on the LangGraph library", additional_kwargs={}, response_metadata={}, id='233e0228-4746-43e6-a5b7-08c82e480700'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves several steps. LangGraph, an extension of the LangChain framework, is a powerful tool that simplifies the creation of sophisticated, stateful AI agents capable of handling complex tasks. It is designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications.nnLangGraph was launched as a low-level agent framework and has been used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. It builds upon feedback from the super popular LangChain framework and rethinks how agent frameworks should work for production.nnThe process of building an agent with LangGraph involves defining what makes an agent different (or similar) to previous software. This is achieved by understanding the key differences that have been identified through building many agents and working with teams from various companies.nnLangGraph is also used to create stateful, multi-actor AI agents with cyclic workflows. This makes it an ideal tool for building a 'Publisher' agent application. The process involves building a Data Analyst Agent with Streamlit and Pydantic-AI and creating an Agentic AI application using LangGraph.", additional_kwargs={}, response_metadata={}, name='research_agent', id='d110f597-bae6-4087-ac28-51eeadc3dd3e'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves the following steps:nn1. **Understand the LangGraph Library**: Before starting the development process, it's crucial to understand the LangGraph library and its functionalities. LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents.nn2. **Define the Agent's Characteristics**: The next step is to define what makes your 'Publisher' agent different or similar to previous software. This can be achieved by understanding the key differences identified through building many agents and working with teams from various companies.nn3. **Design the Agent's Workflow**: LangGraph is used to create stateful, multi-actor AI agents with cyclic workflows. Therefore, you need to design a cyclic workflow for your 'Publisher' agent. This involves defining the tasks the agent will perform, the order in which they will be performed, and how the agent will transition from one task to another.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit and Pydantic-AI are tools that can be used to build a Data Analyst Agent. Streamlit is an open-source app framework for Machine Learning and Data Science teams. Pydantic-AI is a data validation and settings management using python type annotations.nn5. **Create an Agentic AI Application Using LangGraph**: The final step is to use LangGraph to create an Agentic AI application. This involves integrating the Data Analyst Agent built with Streamlit and Pydantic-AI into the LangGraph framework.nnRequirements:n- Knowledge of the LangGraph library and its functionalitiesn- Understanding of the LangChain frameworkn- Familiarity with Streamlit and Pydantic-AIn- Ability to design and implement cyclic workflowsn- Skills in building AI applicationsnnDecisions:n- The specific characteristics and functionalities of the 'Publisher' agentn- The design of the agent's cyclic workflown- The use of Streamlit and Pydantic-AI in building the Data Analyst Agentn- The integration of the Data Analyst Agent into the LangGraph framework to create an Agentic AI application.", additional_kwargs={}, response_metadata={}, name='author_agent', id='b38ab68b-6bf1-4636-99e0-b0396d41394a')], 'critic_marked': False}
[updates] {'critic_agent': {'messages': [{'role': 'assistant', 'content': "The author's work provides a general overview of the process of building a 'Publisher' agent application based on the LangGraph library. However, there are several gaps and ambiguities that need to be addressed:nn1. **Specificity of the 'Publisher' Agent**: The author mentions that the 'Publisher' agent's characteristics need to be defined, but does not provide any specific details about what these characteristics might be. What are the specific tasks that the 'Publisher' agent is expected to perform? What makes it different from other agents?nn2. **Understanding of the LangGraph Library**: The author states that understanding the LangGraph library is crucial, but does not provide any resources or methods for gaining this understanding. How can one learn about the LangGraph library? Are there any recommended resources or tutorials?nn3. **Designing the Agent's Workflow**: The author mentions that a cyclic workflow needs to be designed for the 'Publisher' agent, but does not provide any details about what this workflow might look like. What are the specific steps in the workflow? How does the agent transition from one task to another?nn4. **Building a Data Analyst Agent with Streamlit and Pydantic-AI**: The author mentions that Streamlit and Pydantic-AI are used to build a Data Analyst Agent, but does not provide any details about how this is done. What are the specific steps involved in building a Data Analyst Agent with these tools?nn5. **Creating an Agentic AI Application Using LangGraph**: The author mentions that an Agentic AI application is created using LangGraph, but does not provide any details about how this is done. How is the Data Analyst Agent integrated into the LangGraph framework? What are the specific steps involved in creating an Agentic AI application?nn6. **Requirements and Decisions**: The author lists several requirements and decisions, but does not provide any details about how these requirements can be met or how these decisions can be made. How can one gain the necessary knowledge and skills? How should one go about making these decisions?nnIn conclusion, the author's work provides a general overview of the process, but lacks specific details and guidance. It needs improvement.", 'name': 'critic_agent'}], 'critic_marked': True}}
[values] {'messages': [HumanMessage(content="Generate an article on the topic: How to build a 'Publisher' agent application based on the LangGraph library", additional_kwargs={}, response_metadata={}, id='233e0228-4746-43e6-a5b7-08c82e480700'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves several steps. LangGraph, an extension of the LangChain framework, is a powerful tool that simplifies the creation of sophisticated, stateful AI agents capable of handling complex tasks. It is designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications.nnLangGraph was launched as a low-level agent framework and has been used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. It builds upon feedback from the super popular LangChain framework and rethinks how agent frameworks should work for production.nnThe process of building an agent with LangGraph involves defining what makes an agent different (or similar) to previous software. This is achieved by understanding the key differences that have been identified through building many agents and working with teams from various companies.nnLangGraph is also used to create stateful, multi-actor AI agents with cyclic workflows. This makes it an ideal tool for building a 'Publisher' agent application. The process involves building a Data Analyst Agent with Streamlit and Pydantic-AI and creating an Agentic AI application using LangGraph.", additional_kwargs={}, response_metadata={}, name='research_agent', id='d110f597-bae6-4087-ac28-51eeadc3dd3e'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves the following steps:nn1. **Understand the LangGraph Library**: Before starting the development process, it's crucial to understand the LangGraph library and its functionalities. LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents.nn2. **Define the Agent's Characteristics**: The next step is to define what makes your 'Publisher' agent different or similar to previous software. This can be achieved by understanding the key differences identified through building many agents and working with teams from various companies.nn3. **Design the Agent's Workflow**: LangGraph is used to create stateful, multi-actor AI agents with cyclic workflows. Therefore, you need to design a cyclic workflow for your 'Publisher' agent. This involves defining the tasks the agent will perform, the order in which they will be performed, and how the agent will transition from one task to another.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit and Pydantic-AI are tools that can be used to build a Data Analyst Agent. Streamlit is an open-source app framework for Machine Learning and Data Science teams. Pydantic-AI is a data validation and settings management using python type annotations.nn5. **Create an Agentic AI Application Using LangGraph**: The final step is to use LangGraph to create an Agentic AI application. This involves integrating the Data Analyst Agent built with Streamlit and Pydantic-AI into the LangGraph framework.nnRequirements:n- Knowledge of the LangGraph library and its functionalitiesn- Understanding of the LangChain frameworkn- Familiarity with Streamlit and Pydantic-AIn- Ability to design and implement cyclic workflowsn- Skills in building AI applicationsnnDecisions:n- The specific characteristics and functionalities of the 'Publisher' agentn- The design of the agent's cyclic workflown- The use of Streamlit and Pydantic-AI in building the Data Analyst Agentn- The integration of the Data Analyst Agent into the LangGraph framework to create an Agentic AI application.", additional_kwargs={}, response_metadata={}, name='author_agent', id='b38ab68b-6bf1-4636-99e0-b0396d41394a'), AIMessage(content="The author's work provides a general overview of the process of building a 'Publisher' agent application based on the LangGraph library. However, there are several gaps and ambiguities that need to be addressed:nn1. **Specificity of the 'Publisher' Agent**: The author mentions that the 'Publisher' agent's characteristics need to be defined, but does not provide any specific details about what these characteristics might be. What are the specific tasks that the 'Publisher' agent is expected to perform? What makes it different from other agents?nn2. **Understanding of the LangGraph Library**: The author states that understanding the LangGraph library is crucial, but does not provide any resources or methods for gaining this understanding. How can one learn about the LangGraph library? Are there any recommended resources or tutorials?nn3. **Designing the Agent's Workflow**: The author mentions that a cyclic workflow needs to be designed for the 'Publisher' agent, but does not provide any details about what this workflow might look like. What are the specific steps in the workflow? How does the agent transition from one task to another?nn4. **Building a Data Analyst Agent with Streamlit and Pydantic-AI**: The author mentions that Streamlit and Pydantic-AI are used to build a Data Analyst Agent, but does not provide any details about how this is done. What are the specific steps involved in building a Data Analyst Agent with these tools?nn5. **Creating an Agentic AI Application Using LangGraph**: The author mentions that an Agentic AI application is created using LangGraph, but does not provide any details about how this is done. How is the Data Analyst Agent integrated into the LangGraph framework? What are the specific steps involved in creating an Agentic AI application?nn6. **Requirements and Decisions**: The author lists several requirements and decisions, but does not provide any details about how these requirements can be met or how these decisions can be made. How can one gain the necessary knowledge and skills? How should one go about making these decisions?nnIn conclusion, the author's work provides a general overview of the process, but lacks specific details and guidance. It needs improvement.", additional_kwargs={}, response_metadata={}, name='critic_agent', id='ffa9d5fd-f0ab-4758-8db5-0f685f5034e7')], 'critic_marked': True}
[updates] {'author_agent': {'messages': [{'role': 'assistant', 'content': "Building a 'Publisher' agent application based on the LangGraph library is a multi-step process that requires a deep understanding of the LangGraph library, the LangChain framework, and the tools Streamlit and Pydantic-AI. This article will provide a detailed guide on how to build such an application, including the specific tasks that the 'Publisher' agent is expected to perform, the design of the agent's workflow, and the steps involved in building a Data Analyst Agent and creating an Agentic AI application.nn1. **Understand the LangGraph Library**: LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. To gain a deep understanding of the LangGraph library, you can start by exploring the official LangGraph documentation and tutorials available on their website. Participating in online forums and communities related to LangGraph can also be beneficial.nn2. **Define the 'Publisher' Agent's Characteristics**: The 'Publisher' agent is designed to automate the process of publishing content across various platforms. It should be capable of scheduling posts, managing content, and tracking analytics. The agent's characteristics should be defined based on these tasks. For instance, it should have the ability to interface with various publishing platforms, handle time-based tasks, and process analytical data.nn3. **Design the Agent's Workflow**: The 'Publisher' agent's workflow should be cyclic, meaning it repeats a series of tasks in a loop. A typical workflow might involve fetching content from a database, scheduling it for publication, publishing the content, and then tracking and analyzing the performance of the published content. The agent should be designed to transition smoothly from one task to another, with error handling mechanisms in place to manage any issues that arise.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit is an open-source app framework for Machine Learning and Data Science teams, while Pydantic-AI is a data validation and settings management tool using python type annotations. To build a Data Analyst Agent, start by setting up a Streamlit application and integrating it with Pydantic-AI for data validation. Then, design the agent to fetch, process, and analyze data from the 'Publisher' agent's activities.nn5. **Create an Agentic AI Application Using LangGraph**: Once the Data Analyst Agent is built, it can be integrated into the LangGraph framework to create an Agentic AI application. This involves setting up a LangGraph application, defining the agent's state and behavior within the application, and integrating the Data Analyst Agent into the application's workflow.nnRequirements and Decisions:n- **Requirements**: Gaining the necessary knowledge and skills can be achieved through self-study, online courses, and practical experience. Resources like the LangGraph documentation, online tutorials, and community forums can be invaluable.n- **Decisions**: Decisions regarding the 'Publisher' agent's characteristics, the design of the workflow, and the use of tools should be made based on the specific needs of the project. Consider factors like the platforms the agent will interface with, the complexity of the tasks it will perform, and the resources available for the project.nnIn conclusion, building a 'Publisher' agent application based on the LangGraph library involves a deep understanding of the library and the tools involved, careful planning and design of the agent and its workflow, and the integration of various components to create a cohesive application.", 'name': 'author_agent'}]}}
[values] {'messages': [HumanMessage(content="Generate an article on the topic: How to build a 'Publisher' agent application based on the LangGraph library", additional_kwargs={}, response_metadata={}, id='233e0228-4746-43e6-a5b7-08c82e480700'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves several steps. LangGraph, an extension of the LangChain framework, is a powerful tool that simplifies the creation of sophisticated, stateful AI agents capable of handling complex tasks. It is designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications.nnLangGraph was launched as a low-level agent framework and has been used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. It builds upon feedback from the super popular LangChain framework and rethinks how agent frameworks should work for production.nnThe process of building an agent with LangGraph involves defining what makes an agent different (or similar) to previous software. This is achieved by understanding the key differences that have been identified through building many agents and working with teams from various companies.nnLangGraph is also used to create stateful, multi-actor AI agents with cyclic workflows. This makes it an ideal tool for building a 'Publisher' agent application. The process involves building a Data Analyst Agent with Streamlit and Pydantic-AI and creating an Agentic AI application using LangGraph.", additional_kwargs={}, response_metadata={}, name='research_agent', id='d110f597-bae6-4087-ac28-51eeadc3dd3e'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves the following steps:nn1. **Understand the LangGraph Library**: Before starting the development process, it's crucial to understand the LangGraph library and its functionalities. LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents.nn2. **Define the Agent's Characteristics**: The next step is to define what makes your 'Publisher' agent different or similar to previous software. This can be achieved by understanding the key differences identified through building many agents and working with teams from various companies.nn3. **Design the Agent's Workflow**: LangGraph is used to create stateful, multi-actor AI agents with cyclic workflows. Therefore, you need to design a cyclic workflow for your 'Publisher' agent. This involves defining the tasks the agent will perform, the order in which they will be performed, and how the agent will transition from one task to another.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit and Pydantic-AI are tools that can be used to build a Data Analyst Agent. Streamlit is an open-source app framework for Machine Learning and Data Science teams. Pydantic-AI is a data validation and settings management using python type annotations.nn5. **Create an Agentic AI Application Using LangGraph**: The final step is to use LangGraph to create an Agentic AI application. This involves integrating the Data Analyst Agent built with Streamlit and Pydantic-AI into the LangGraph framework.nnRequirements:n- Knowledge of the LangGraph library and its functionalitiesn- Understanding of the LangChain frameworkn- Familiarity with Streamlit and Pydantic-AIn- Ability to design and implement cyclic workflowsn- Skills in building AI applicationsnnDecisions:n- The specific characteristics and functionalities of the 'Publisher' agentn- The design of the agent's cyclic workflown- The use of Streamlit and Pydantic-AI in building the Data Analyst Agentn- The integration of the Data Analyst Agent into the LangGraph framework to create an Agentic AI application.", additional_kwargs={}, response_metadata={}, name='author_agent', id='b38ab68b-6bf1-4636-99e0-b0396d41394a'), AIMessage(content="The author's work provides a general overview of the process of building a 'Publisher' agent application based on the LangGraph library. However, there are several gaps and ambiguities that need to be addressed:nn1. **Specificity of the 'Publisher' Agent**: The author mentions that the 'Publisher' agent's characteristics need to be defined, but does not provide any specific details about what these characteristics might be. What are the specific tasks that the 'Publisher' agent is expected to perform? What makes it different from other agents?nn2. **Understanding of the LangGraph Library**: The author states that understanding the LangGraph library is crucial, but does not provide any resources or methods for gaining this understanding. How can one learn about the LangGraph library? Are there any recommended resources or tutorials?nn3. **Designing the Agent's Workflow**: The author mentions that a cyclic workflow needs to be designed for the 'Publisher' agent, but does not provide any details about what this workflow might look like. What are the specific steps in the workflow? How does the agent transition from one task to another?nn4. **Building a Data Analyst Agent with Streamlit and Pydantic-AI**: The author mentions that Streamlit and Pydantic-AI are used to build a Data Analyst Agent, but does not provide any details about how this is done. What are the specific steps involved in building a Data Analyst Agent with these tools?nn5. **Creating an Agentic AI Application Using LangGraph**: The author mentions that an Agentic AI application is created using LangGraph, but does not provide any details about how this is done. How is the Data Analyst Agent integrated into the LangGraph framework? What are the specific steps involved in creating an Agentic AI application?nn6. **Requirements and Decisions**: The author lists several requirements and decisions, but does not provide any details about how these requirements can be met or how these decisions can be made. How can one gain the necessary knowledge and skills? How should one go about making these decisions?nnIn conclusion, the author's work provides a general overview of the process, but lacks specific details and guidance. It needs improvement.", additional_kwargs={}, response_metadata={}, name='critic_agent', id='ffa9d5fd-f0ab-4758-8db5-0f685f5034e7'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library is a multi-step process that requires a deep understanding of the LangGraph library, the LangChain framework, and the tools Streamlit and Pydantic-AI. This article will provide a detailed guide on how to build such an application, including the specific tasks that the 'Publisher' agent is expected to perform, the design of the agent's workflow, and the steps involved in building a Data Analyst Agent and creating an Agentic AI application.nn1. **Understand the LangGraph Library**: LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. To gain a deep understanding of the LangGraph library, you can start by exploring the official LangGraph documentation and tutorials available on their website. Participating in online forums and communities related to LangGraph can also be beneficial.nn2. **Define the 'Publisher' Agent's Characteristics**: The 'Publisher' agent is designed to automate the process of publishing content across various platforms. It should be capable of scheduling posts, managing content, and tracking analytics. The agent's characteristics should be defined based on these tasks. For instance, it should have the ability to interface with various publishing platforms, handle time-based tasks, and process analytical data.nn3. **Design the Agent's Workflow**: The 'Publisher' agent's workflow should be cyclic, meaning it repeats a series of tasks in a loop. A typical workflow might involve fetching content from a database, scheduling it for publication, publishing the content, and then tracking and analyzing the performance of the published content. The agent should be designed to transition smoothly from one task to another, with error handling mechanisms in place to manage any issues that arise.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit is an open-source app framework for Machine Learning and Data Science teams, while Pydantic-AI is a data validation and settings management tool using python type annotations. To build a Data Analyst Agent, start by setting up a Streamlit application and integrating it with Pydantic-AI for data validation. Then, design the agent to fetch, process, and analyze data from the 'Publisher' agent's activities.nn5. **Create an Agentic AI Application Using LangGraph**: Once the Data Analyst Agent is built, it can be integrated into the LangGraph framework to create an Agentic AI application. This involves setting up a LangGraph application, defining the agent's state and behavior within the application, and integrating the Data Analyst Agent into the application's workflow.nnRequirements and Decisions:n- **Requirements**: Gaining the necessary knowledge and skills can be achieved through self-study, online courses, and practical experience. Resources like the LangGraph documentation, online tutorials, and community forums can be invaluable.n- **Decisions**: Decisions regarding the 'Publisher' agent's characteristics, the design of the workflow, and the use of tools should be made based on the specific needs of the project. Consider factors like the platforms the agent will interface with, the complexity of the tasks it will perform, and the resources available for the project.nnIn conclusion, building a 'Publisher' agent application based on the LangGraph library involves a deep understanding of the library and the tools involved, careful planning and design of the agent and its workflow, and the integration of various components to create a cohesive application.", additional_kwargs={}, response_metadata={}, name='author_agent', id='da4482cc-44ac-4917-b01f-166f66899860')], 'critic_marked': True}
[updates] {'critic_agent': {'messages': [{'role': 'assistant', 'content': "The author's revised work provides a more detailed and comprehensive guide on building a 'Publisher' agent application based on the LangGraph library. The author has addressed the previous gaps and ambiguities by providing specific details about the 'Publisher' agent's tasks, the design of the agent's workflow, and the steps involved in building a Data Analyst Agent and creating an Agentic AI application. The author has also provided resources and methods for gaining the necessary knowledge and skills, and has given guidance on how to make the necessary decisions. The revised work is approved.", 'name': 'critic_agent'}]}}
[values] {'messages': [HumanMessage(content="Generate an article on the topic: How to build a 'Publisher' agent application based on the LangGraph library", additional_kwargs={}, response_metadata={}, id='233e0228-4746-43e6-a5b7-08c82e480700'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves several steps. LangGraph, an extension of the LangChain framework, is a powerful tool that simplifies the creation of sophisticated, stateful AI agents capable of handling complex tasks. It is designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications.nnLangGraph was launched as a low-level agent framework and has been used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. It builds upon feedback from the super popular LangChain framework and rethinks how agent frameworks should work for production.nnThe process of building an agent with LangGraph involves defining what makes an agent different (or similar) to previous software. This is achieved by understanding the key differences that have been identified through building many agents and working with teams from various companies.nnLangGraph is also used to create stateful, multi-actor AI agents with cyclic workflows. This makes it an ideal tool for building a 'Publisher' agent application. The process involves building a Data Analyst Agent with Streamlit and Pydantic-AI and creating an Agentic AI application using LangGraph.", additional_kwargs={}, response_metadata={}, name='research_agent', id='d110f597-bae6-4087-ac28-51eeadc3dd3e'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library involves the following steps:nn1. **Understand the LangGraph Library**: Before starting the development process, it's crucial to understand the LangGraph library and its functionalities. LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents.nn2. **Define the Agent's Characteristics**: The next step is to define what makes your 'Publisher' agent different or similar to previous software. This can be achieved by understanding the key differences identified through building many agents and working with teams from various companies.nn3. **Design the Agent's Workflow**: LangGraph is used to create stateful, multi-actor AI agents with cyclic workflows. Therefore, you need to design a cyclic workflow for your 'Publisher' agent. This involves defining the tasks the agent will perform, the order in which they will be performed, and how the agent will transition from one task to another.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit and Pydantic-AI are tools that can be used to build a Data Analyst Agent. Streamlit is an open-source app framework for Machine Learning and Data Science teams. Pydantic-AI is a data validation and settings management using python type annotations.nn5. **Create an Agentic AI Application Using LangGraph**: The final step is to use LangGraph to create an Agentic AI application. This involves integrating the Data Analyst Agent built with Streamlit and Pydantic-AI into the LangGraph framework.nnRequirements:n- Knowledge of the LangGraph library and its functionalitiesn- Understanding of the LangChain frameworkn- Familiarity with Streamlit and Pydantic-AIn- Ability to design and implement cyclic workflowsn- Skills in building AI applicationsnnDecisions:n- The specific characteristics and functionalities of the 'Publisher' agentn- The design of the agent's cyclic workflown- The use of Streamlit and Pydantic-AI in building the Data Analyst Agentn- The integration of the Data Analyst Agent into the LangGraph framework to create an Agentic AI application.", additional_kwargs={}, response_metadata={}, name='author_agent', id='b38ab68b-6bf1-4636-99e0-b0396d41394a'), AIMessage(content="The author's work provides a general overview of the process of building a 'Publisher' agent application based on the LangGraph library. However, there are several gaps and ambiguities that need to be addressed:nn1. **Specificity of the 'Publisher' Agent**: The author mentions that the 'Publisher' agent's characteristics need to be defined, but does not provide any specific details about what these characteristics might be. What are the specific tasks that the 'Publisher' agent is expected to perform? What makes it different from other agents?nn2. **Understanding of the LangGraph Library**: The author states that understanding the LangGraph library is crucial, but does not provide any resources or methods for gaining this understanding. How can one learn about the LangGraph library? Are there any recommended resources or tutorials?nn3. **Designing the Agent's Workflow**: The author mentions that a cyclic workflow needs to be designed for the 'Publisher' agent, but does not provide any details about what this workflow might look like. What are the specific steps in the workflow? How does the agent transition from one task to another?nn4. **Building a Data Analyst Agent with Streamlit and Pydantic-AI**: The author mentions that Streamlit and Pydantic-AI are used to build a Data Analyst Agent, but does not provide any details about how this is done. What are the specific steps involved in building a Data Analyst Agent with these tools?nn5. **Creating an Agentic AI Application Using LangGraph**: The author mentions that an Agentic AI application is created using LangGraph, but does not provide any details about how this is done. How is the Data Analyst Agent integrated into the LangGraph framework? What are the specific steps involved in creating an Agentic AI application?nn6. **Requirements and Decisions**: The author lists several requirements and decisions, but does not provide any details about how these requirements can be met or how these decisions can be made. How can one gain the necessary knowledge and skills? How should one go about making these decisions?nnIn conclusion, the author's work provides a general overview of the process, but lacks specific details and guidance. It needs improvement.", additional_kwargs={}, response_metadata={}, name='critic_agent', id='ffa9d5fd-f0ab-4758-8db5-0f685f5034e7'), AIMessage(content="Building a 'Publisher' agent application based on the LangGraph library is a multi-step process that requires a deep understanding of the LangGraph library, the LangChain framework, and the tools Streamlit and Pydantic-AI. This article will provide a detailed guide on how to build such an application, including the specific tasks that the 'Publisher' agent is expected to perform, the design of the agent's workflow, and the steps involved in building a Data Analyst Agent and creating an Agentic AI application.nn1. **Understand the LangGraph Library**: LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It's used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. To gain a deep understanding of the LangGraph library, you can start by exploring the official LangGraph documentation and tutorials available on their website. Participating in online forums and communities related to LangGraph can also be beneficial.nn2. **Define the 'Publisher' Agent's Characteristics**: The 'Publisher' agent is designed to automate the process of publishing content across various platforms. It should be capable of scheduling posts, managing content, and tracking analytics. The agent's characteristics should be defined based on these tasks. For instance, it should have the ability to interface with various publishing platforms, handle time-based tasks, and process analytical data.nn3. **Design the Agent's Workflow**: The 'Publisher' agent's workflow should be cyclic, meaning it repeats a series of tasks in a loop. A typical workflow might involve fetching content from a database, scheduling it for publication, publishing the content, and then tracking and analyzing the performance of the published content. The agent should be designed to transition smoothly from one task to another, with error handling mechanisms in place to manage any issues that arise.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit is an open-source app framework for Machine Learning and Data Science teams, while Pydantic-AI is a data validation and settings management tool using python type annotations. To build a Data Analyst Agent, start by setting up a Streamlit application and integrating it with Pydantic-AI for data validation. Then, design the agent to fetch, process, and analyze data from the 'Publisher' agent's activities.nn5. **Create an Agentic AI Application Using LangGraph**: Once the Data Analyst Agent is built, it can be integrated into the LangGraph framework to create an Agentic AI application. This involves setting up a LangGraph application, defining the agent's state and behavior within the application, and integrating the Data Analyst Agent into the application's workflow.nnRequirements and Decisions:n- **Requirements**: Gaining the necessary knowledge and skills can be achieved through self-study, online courses, and practical experience. Resources like the LangGraph documentation, online tutorials, and community forums can be invaluable.n- **Decisions**: Decisions regarding the 'Publisher' agent's characteristics, the design of the workflow, and the use of tools should be made based on the specific needs of the project. Consider factors like the platforms the agent will interface with, the complexity of the tasks it will perform, and the resources available for the project.nnIn conclusion, building a 'Publisher' agent application based on the LangGraph library involves a deep understanding of the library and the tools involved, careful planning and design of the agent and its workflow, and the integration of various components to create a cohesive application.", additional_kwargs={}, response_metadata={}, name='author_agent', id='da4482cc-44ac-4917-b01f-166f66899860'), AIMessage(content="The author's revised work provides a more detailed and comprehensive guide on building a 'Publisher' agent application based on the LangGraph library. The author has addressed the previous gaps and ambiguities by providing specific details about the 'Publisher' agent's tasks, the design of the agent's workflow, and the steps involved in building a Data Analyst Agent and creating an Agentic AI application. The author has also provided resources and methods for gaining the necessary knowledge and skills, and has given guidance on how to make the necessary decisions. The revised work is approved.", additional_kwargs={}, response_metadata={}, name='critic_agent', id='a44b905d-957b-4ec5-96e2-a0d50e2aac62')], 'critic_marked': True}
final response:
(content=”Building a ‘Publisher’ agent application based on the LangGraph library is a multi-step process that requires a deep understanding of the LangGraph library, the LangChain framework, and the tools Streamlit and Pydantic-AI. This article will provide a detailed guide on how to build such an application, including the specific tasks that the ‘Publisher’ agent is expected to perform, the design of the agent’s workflow, and the steps involved in building a Data Analyst Agent and creating an Agentic AI application.nn1. **Understand the LangGraph Library**: LangGraph is an extension of the LangChain framework, designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. It’s used by companies like LinkedIn, Uber, and Klarna to build production-ready agents. To gain a deep understanding of the LangGraph library, you can start by exploring the official LangGraph documentation and tutorials available on their website. Participating in online forums and communities related to LangGraph can also be beneficial.nn2. **Define the ‘Publisher’ Agent’s Characteristics**: The ‘Publisher’ agent is designed to automate the process of publishing content across various platforms. It should be capable of scheduling posts, managing content, and tracking analytics. The agent’s characteristics should be defined based on these tasks. For instance, it should have the ability to interface with various publishing platforms, handle time-based tasks, and process analytical data.nn3. **Design the Agent’s Workflow**: The ‘Publisher’ agent’s workflow should be cyclic, meaning it repeats a series of tasks in a loop. A typical workflow might involve fetching content from a database, scheduling it for publication, publishing the content, and then tracking and analyzing the performance of the published content. The agent should be designed to transition smoothly from one task to another, with error handling mechanisms in place to manage any issues that arise.nn4. **Build a Data Analyst Agent with Streamlit and Pydantic-AI**: Streamlit is an open-source app framework for Machine Learning and Data Science teams, while Pydantic-AI is a data validation and settings management tool using python type annotations. To build a Data Analyst Agent, start by setting up a Streamlit application and integrating it with Pydantic-AI for data validation. Then, design the agent to fetch, process, and analyze data from the ‘Publisher’ agent’s activities.nn5. **Create an Agentic AI Application Using LangGraph**: Once the Data Analyst Agent is built, it can be integrated into the LangGraph framework to create an Agentic AI application. This involves setting up a LangGraph application, defining the agent’s state and behavior within the application, and integrating the Data Analyst Agent into the application’s workflow.nnRequirements and Decisions:n- **Requirements**: Gaining the necessary knowledge and skills can be achieved through self-study, online courses, and practical experience. Resources like the LangGraph documentation, online tutorials, and community forums can be invaluable
Here is also last response from critic node:
The author's revised work provides a more detailed and comprehensive guide on
building a 'Publisher' agent application based on the LangGraph library.
The author has addressed the previous gaps and ambiguities by providing
specific details about the 'Publisher' agent's tasks, the design of the
agent's workflow, and the steps involved in building a Data Analyst Agent and
creating an Agentic AI application. The author has also provided resources
and methods for gaining the necessary knowledge and skills, and has given
guidance on how to make the necessary decisions. The revised work is approved.
Why this design works for publishing?
- rounded first pass: The Researcher constrains the Author with verifiable inputs (Tavily).
- Iterative refinement: The Critic enforces minimum quality — only one hop back if “needs improvement,” then stop.
- Testable components: You can unit-test each node with fixed inputs; swap models as needed.
- Extensible: Add roles (e.g., SEO Optimizer, Fact-Checker, Style Editor), or tools (citation fetchers, CMS uploaders).
That’s all int this chapter dedicated to AI agent application with agent publisher. In the next chapter we will build another fully functional application of AI experts discussion panel.
see next chapter
see previous chapter
see the full code from this article in the GitHub repository
LLM & AI Agent Applications with LangChain and LangGraph — Part 27: The Publisher Agent (News →… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.