Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents
Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at on device and edge deployments. The model family includes LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, vision language, and audio language variants. It is released as open weights on Hugging Face and exposed through the LEAP platform.
Architecture and training recipe
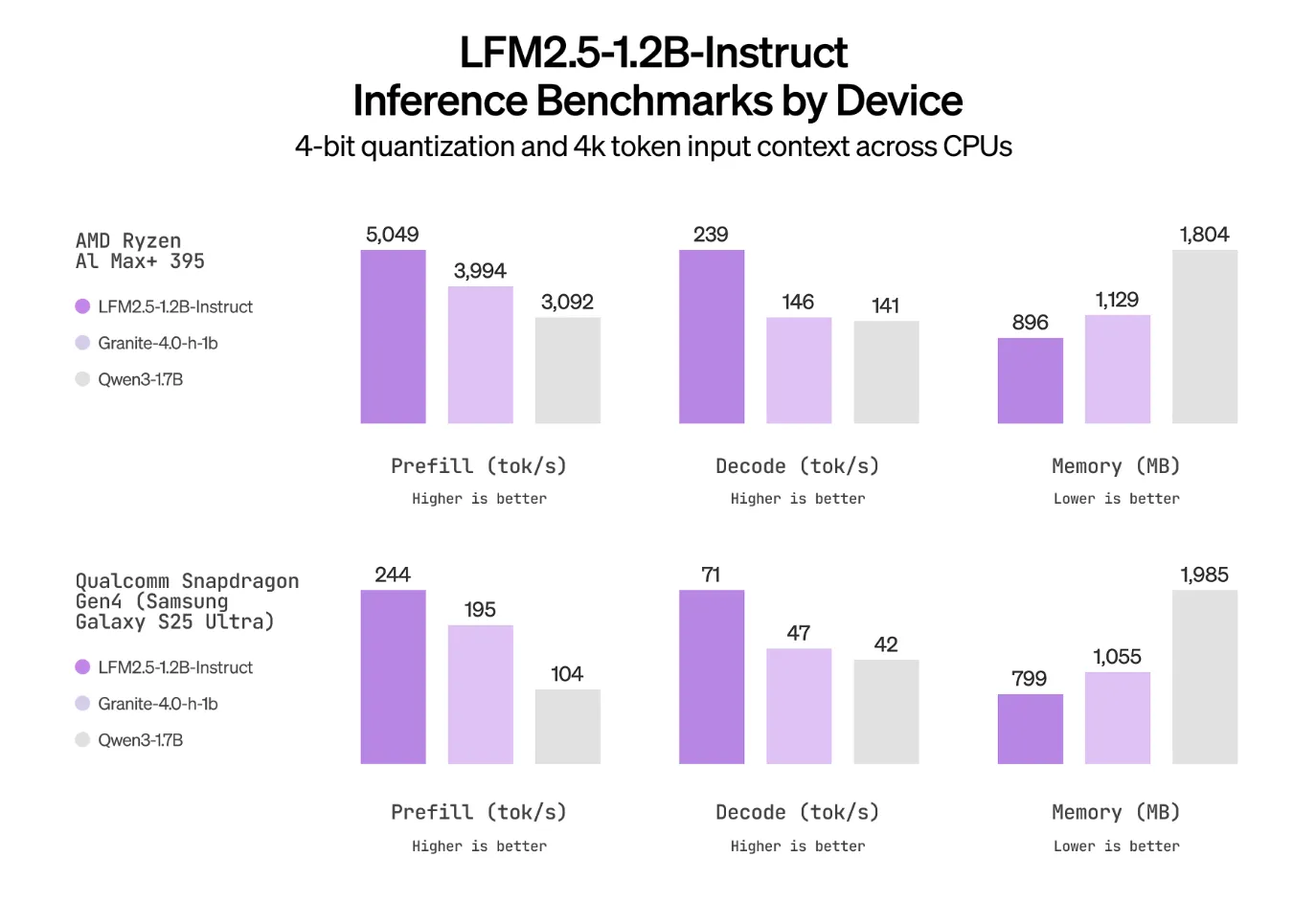
LFM2.5 keeps the hybrid LFM2 architecture that was designed for fast and memory efficient inference on CPUs and NPUs and scales the data and post training pipeline. Pretraining for the 1.2 billion parameter backbone is extended from 10T to 28T tokens. The instruct variant then receives supervised fine tuning, preference alignment, and large scale multi stage reinforcement learning focused on instruction following, tool use, math, and knowledge reasoning.
Text model performance at one billion scale
LFM2.5-1.2B-Instruct is the main general purpose text model. Liquid AI team reports benchmark results on GPQA, MMLU Pro, IFEval, IFBench, and several function calling and coding suites. The model reaches 38.89 on GPQA and 44.35 on MMLU Pro. Competing 1B class open models such as Llama-3.2-1B Instruct and Gemma-3-1B IT score significantly lower on these metrics.
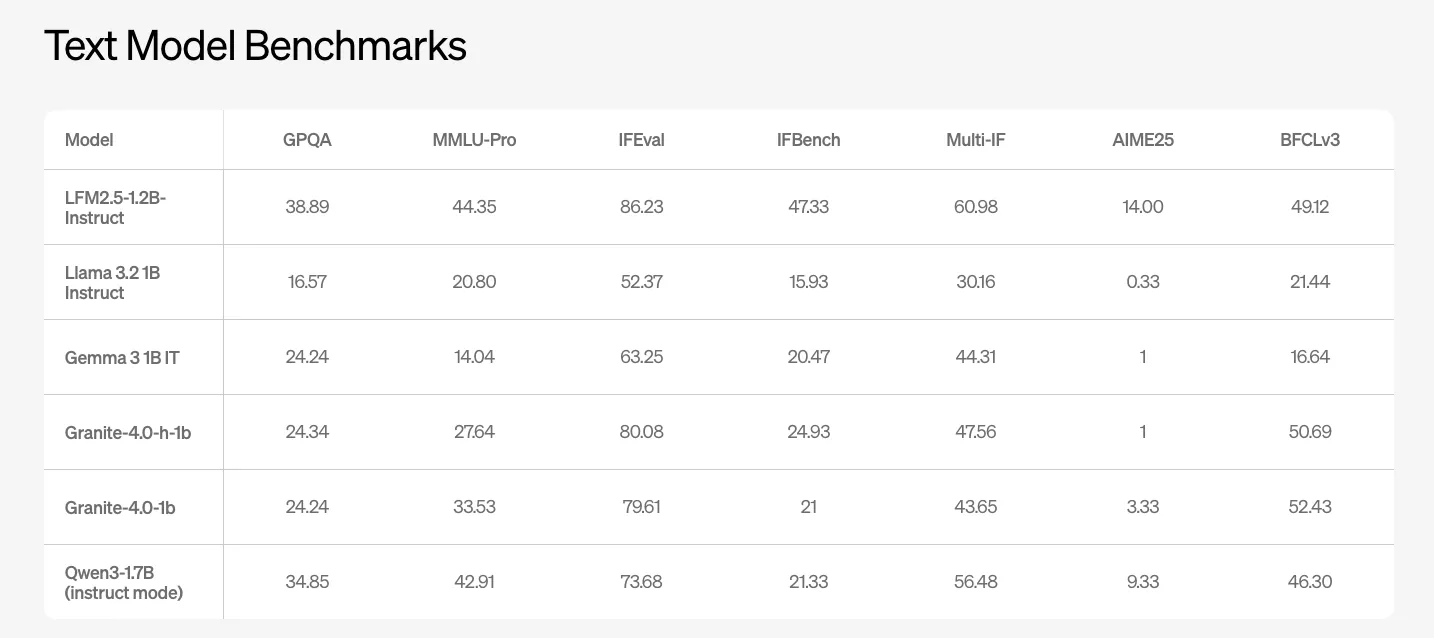
On IFEval and IFBench, which target multi step instruction following and function calling quality, LFM2.5-1.2B-Instruct reports 86.23 and 47.33. These values are ahead of the other 1B class baselines in the above Liquid AI table.
Japanese optimized variant
LFM2.5-1.2B-JP is a Japanese optimized text model derived from the same backbone. It targets tasks such as JMMLU, M-IFEval in Japanese, and GSM8K in Japanese. This checkpoint improves over the general instruct model on Japanese tasks and competes with or surpasses other small multilingual models like Qwen3-1.7B, Llama 3.2-1B Instruct, and Gemma 3-1B IT on these localized benchmarks.
Vision language model for multimodal edge workloads
LFM2.5-VL-1.6B is the updated vision language model in the series. It uses LFM2.5-1.2B-Base as the language backbone and adds a vision tower for image understanding. The model is tuned on a range of visual reasoning and OCR benchmarks, including MMStar, MM IFEval, BLINK, InfoVQA, OCRBench v2, RealWorldQA, MMMU, and multilingual MMBench. LFM2.5-VL-1.6B improves over the previous LFM2-VL-1.6B on most metrics and is intended for real world tasks such as document understanding, user interface reading, and multi image reasoning under edge constraints.
Audio language model with native speech generation
LFM2.5-Audio-1.5B is a native audio language model that supports both text and audio inputs and outputs. It is presented as an Audio to Audio model and uses an audio detokenizer that is described as eight times faster than the previous Mimi based detokenizer at the same precision on constrained hardware.
The model supports two main generation modes. Interleaved generation is designed for real time speech to speech conversational agents where latency dominates. Sequential generation is aimed at tasks such as automatic speech recognition and text to speech and allows switching the generated modality without reinitializing the model. The audio stack is trained with quantization aware training at low precision, which keeps metrics such as STOI and UTMOS close to the full precision baseline while enabling deployment on devices with limited compute.
Key Takeaways
- LFM2.5 is a 1.2B scale hybrid model family built on the LFM2 device optimized architecture, with Base, Instruct, Japanese, Vision Language, and Audio Language variants, all released as open weights on Hugging Face and LEAP.
- Pretraining for LFM2.5 extends from 10T to 28T tokens and the Instruct model adds supervised fine tuning, preference alignment, and large scale multi stage reinforcement learning, which pushes instruction following and tool use quality beyond other 1B class baselines.
- LFM2.5-1.2B-Instruct delivers strong text benchmark performance at the 1B scale, reaching 38.89 on GPQA and 44.35 on MMLU Pro and leading peer models such as Llama 3.2 1B Instruct, Gemma 3 1B IT, and Granite 4.0 1B on IFEval and IFBench.
- The family includes specialized multimodal and regional variants, with LFM2.5-1.2B-JP achieving state of the art results for Japanese benchmarks at its scale and LFM2.5-VL-1.6B and LFM2.5-Audio-1.5B covering vision language and native audio language workloads for edge agents.
Check out the Technical details and Model weights. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Check out our latest release of ai2025.dev, a 2025-focused analytics platform that turns model launches, benchmarks, and ecosystem activity into a structured dataset you can filter, compare, and export
The post Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents appeared first on MarkTechPost.