
Latent Contextual Reinforcement: Teaching Language Models to Think Better Without Changing Their…
Latent Contextual Reinforcement: Teaching Language Models to Think Better Without Changing Their Weights
Adeel Ahmad
I trained a 4-billion-parameter language model on a laptop with 8 gigabytes of RAM. It took a few hours and produced an adapter file smaller than most photographs. Every standard evaluation metric — cosine similarity, CKA, benchmark scores, perplexity — says the model did not change. It did.
The model’s behaviour transformed: it reasons more efficiently, follows structured thinking patterns it never exhibited before, and adopted an entirely new identity. Mechanistic analysis confirms the transformation is real — attention subspaces rotated, cluster stability shifted, and token prediction distributions reorganised. But weight-level metrics cannot detect any of it. This is not a failure of the training. It is a failure of how the field evaluates fine-tuning.
This post describes the technique — Latent Contextual Reinforcement (LCR) — and why it works.
The Problem with Current Approaches
Standard methods for fine-tuning language models require massive data, powerful hardware, and extensive human feedback. They also risk breaking what the model already knows — catastrophic forgetting. And they share a deeper flaw: they shift the model’s output distribution away from its pre-trained distribution, creating divergence that compounds over training.
Supervised fine-tuning is memorisation. The model learns to reproduce the exact token sequence of expert demonstrations. Present a novel problem that deviates from the training distribution, and the model fails — it learned to copy, not to think. Reinforcement learning generalises but demands enormous compute. Standard GRPO requires many rollouts per prompt across large batches, meaning hundreds of forward passes per training step. When every rollout fails on a hard problem, the gradient signal collapses entirely — the model cannot learn from problems it cannot already partially solve.
But teaching is different from fine-tuning. Fine-tuning changes weights. Teaching activates what’s already there.
LCR solves all three problems simultaneously.
The Technique
LCR combines six mechanisms into a single training loop. Each is simple. Their interaction is what produces the result.
1. Interleaved Co-authoring
During generation, expert reasoning tokens are injected directly into the model’s context window, alternating with the model’s own generation. You start with a user prompt in the chat template context. When the model begins generating its assistant response, instead of letting it start from scratch, you inject target reasoning tokens from your dataset.
Then co-authoring begins: the expert produces a chunk of thinking tokens, then the model generates its own chunk conditioned on everything it has seen — including the expert tokens it believes it wrote. This cycle repeats throughout the reasoning chain. The model never sees a boundary between expert tokens and its own. From its perspective, it produced the entire sequence.
The model’s autoregressive nature makes it continue coherently. Because of in-context learning, the model sees the context as if it had written these things before, shaping its next-token predictions and activation pathways mechanistically. Even if the model agrees or disagrees with the target reasoning, you’re steering it toward pathways it wouldn’t naturally explore. The model weaves everything together, thinking it’s all its own work, but experiencing new reasoning trajectories in latent space.
2. Masked Backpropagation
During the backward pass, all expert-injected tokens are masked. Gradients flow only through model-generated tokens. The expert trace guides through context, not through supervision. The model trains exclusively on its own outputs.
This is the core insight: the training distribution never shifts because the model is always learning from its own generation. KL divergence stays near zero by construction. Catastrophic forgetting does not occur because the model’s output distribution is the training distribution.
3. Proximity Gradients
Not all model-generated tokens are equally valuable. Tokens generated immediately after an expert scaffold chunk carry the strongest imprint of the expert’s reasoning — they were produced while the expert’s context was freshest.
LCR applies an exponential gradient multiplier that peaks at tokens adjacent to scaffold boundaries and decays to zero beyond a threshold. The first few tokens immediately after the scaffold might receive several times the base gradient, while tokens beyond a certain point receive zero gradients — the model doesn’t learn from them at all.
This solves credit assignment structurally: instead of asking which tokens in a long chain contributed to success, the technique assumes tokens closest to expert guidance are most informative and weights them accordingly. These thresholds, amplification factors, and decay rates are all knobs you tune based on your specific language model and problem.
4. Jaccard Similarity Matching
Before applying proximity weights, LCR computes token-level Jaccard similarity between the model’s generation and the expert’s target reasoning. When the model’s thinking closely matches the expert’s, that segment receives amplified reinforcement. When the model diverges from the expert’s approach, the gradient contribution diminishes.
This creates a soft reward signal that is denser than binary outcome rewards but does not require step-level human annotation.
5. Group Relative Policy Optimisation
Multiple rollouts are generated per problem using a specific group structure designed to maximise signal and minimise compute.
The first rollout in the group is purely the model’s own generation — no target text token scaffolding at all. This serves two purposes: it shows what the model already knows without guidance, and it lets you monitor training progress in real time. If this baseline rollout produces the correct answer, move to the next sample. No need for further rollouts, no wasted compute.
Only if the baseline fails do you proceed. Same sample, same model, nothing happened yet — no gradient, no optimiser step, no loss calculation. Only a forward pass again from scratch, but with different boundaries of target chain-of-thought tokens, so that you have diversity. You might increase the number of target tokens to influence more and give the model less control, forcing it to agree and produce the right answer.
Each rollout receives a binary reward based only on whether the final boxed answer matches the ground truth. Advantage is computed relative to the group — a correct answer in a group of failures receives a strong positive advantage, a correct answer among other correct answers receives a weaker advantage. Only positive-advantage rollouts propagate gradients. Only model-generated tokens within those rollouts receive updates. Combined with proximity masking and Jaccard weighting, the gradient signal is concentrated onto a narrow band of high-value tokens in successful rollouts.
Chain-of-thought budget control matters here. If the model commits and closes the thinking tag on its own — very good. You stop right there. You start the boxed answer section so the model knows to put the answer in the box. If the model doesn’t close within the budget, you take the last few tokens of the chain of thought from the target, inject them, and force-close the thinking tag. The model believes it wrote those final tokens and closed naturally. Then you give the turn to the model to produce the answer.
Reward is based only on the boxed answer — not on how well the model did in the reasoning process. The reasoning shapes the latent space through proximity loss. Not the reinforcement learning reward. If the model produces the correct answer in the box, close the box and move on. If not, stop after a few tokens and close the box.
The diversity and retry mechanism artificially creates aha moments — sudden realisations in which the model discovers the correct reasoning path. GRPO then reinforces these aha moments across the group of rollouts.
6. Scaffolding Anchors
Separately from the interleaved expert traces, a set of one-line behavioural instructions are randomly selected and injected into each training sample, then masked during backpropagation. The model sees different random subsets each time. Because no single instruction is consistently present but the underlying principle is, the model extracts the invariant behavioural pattern across all variants rather than memorising any specific phrasing.
The Adapter Architecture
LCR uses DoRA (Weight-Decomposed Low-Rank Adaptation) rather than standard LoRA. DoRA separates weight updates into a magnitude vector and a directional low-rank decomposition. The magnitude vector is a per-output-dimension scalar that controls how much each dimension contributes. The low-rank matrices control the direction of the update. This decomposition means the adapter can rotate the representation space without changing its scale — which is precisely what mechanistic analysis reveals is happening.
The adapter operates at rank 4 with alpha 8 and targets only the query and value projections in the attention layers. No keys, no output projections, no MLP layers are modified. The entire adapter is a few megabytes. It changes what the model attends to and how it represents what it finds. Knowledge stored in feedforward layers is untouched.
Because the rotation is single-axis, even with diverse multitask GRPO training in a single run, you don’t need a large rank. We believe rank 2 would work equally well.
Why It Works: Programming, Not Rewriting
LCR does not teach the model new knowledge. The base model already contains the knowledge and the reasoning capability. What LCR changes is how the model routes information through its attention layers — which existing knowledge gets activated, in what order, and with what priority.
The analogy is programming versus recompiling. Traditional fine-tuning recompiles the model: it modifies weights directly, risks breaking existing functionality, and produces unpredictable side effects. LCR programs the model: it adjusts the control flow (attention routing) while leaving the instruction set (stored knowledge) intact. The model’s representational geometry — the structure of its internal knowledge — remains identical. What changes is the path the model takes through that geometry during reasoning.
By varying where you inject target tokens, you’re activating different existing knowledge pathways within the latent space. The model wasn’t taught these paths during this process — they were already there. You’re just steering it toward them through co-authoring and proximity loss.
Standard scaling laws suggest that more parameters equal better performance. This methodology challenges that assumption. You can teach a language model to reason along trajectories that only frontier models typically master — because this training uses only the model’s own generated text, the model’s own distribution. The model never diverges from itself.
This has profound implications: catastrophic forgetting is extremely unlikely because the model trains on its own outputs. KL divergence blow-up doesn’t occur. Out-of-distribution drift is minimal. All the problems you’d normally account for in large-scale reinforcement learning training runs — you get them for free here.
Experimental Evidence
We trained Qwen3–4B on a mixed dataset of mathematics and identity tasks using LCR. The following table summarises the training configuration:
ParameterValueModelQwen3–4B (bfloat16)AdapterDoRA, rank 4, alpha 8Target layers36 (Q and V projections only)Group size3Proximitydecay 0.85, scale 3.5Learning rate5 × 10−6Batch size1HardwareLaptop, 8 GB RAM (peak: 7,734 MB)
Training Dynamics
After 24 iterations (40 training groups, 120 total rollouts), the results at this early snapshot:
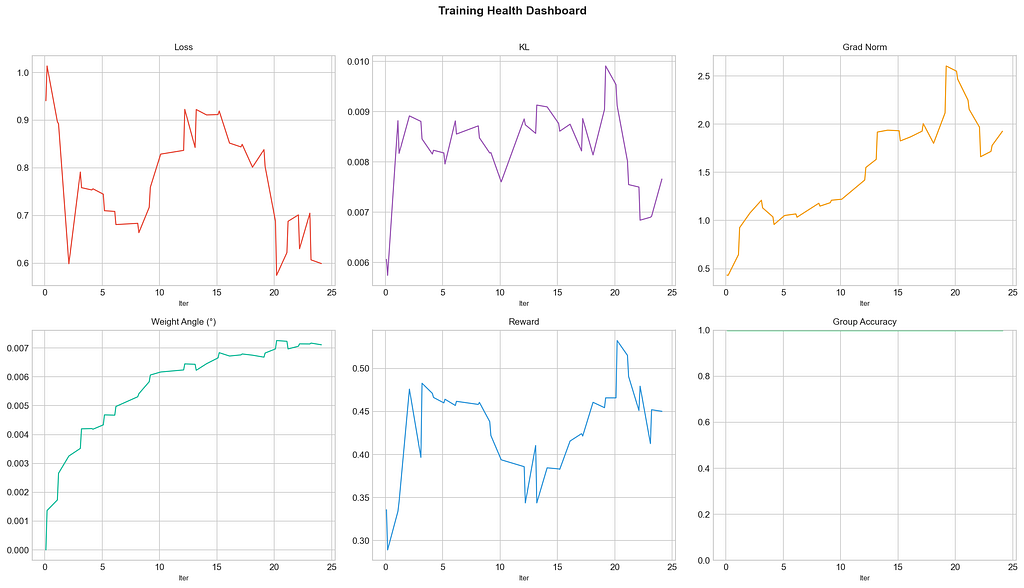
Group accuracy reached 100%. Every training group produced at least one correct rollout. The retry mechanism with varied scaffold boundaries ensured that even hard problems found the correct reasoning path.
Naked accuracy remains at 12%. Without scaffolding, the model produces correct answers only 12% of the time. The model is still heavily scaffold-dependent at this stage — internalisation requires more iterations. This is 24 iterations of a planned 2,000-iteration run.
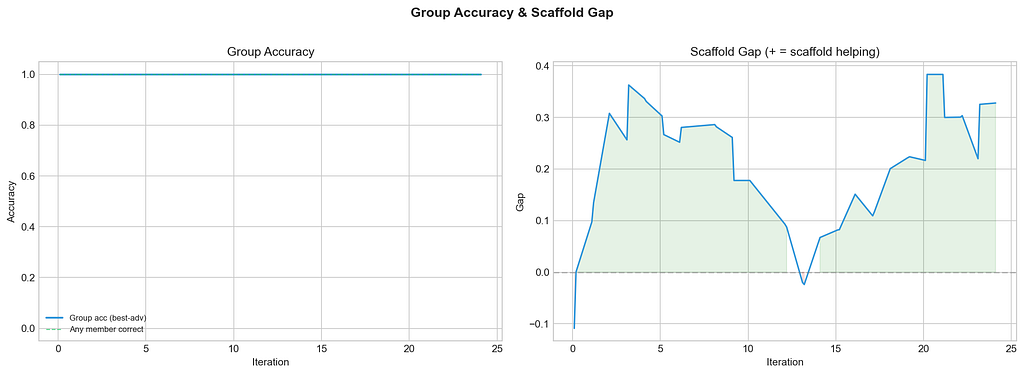
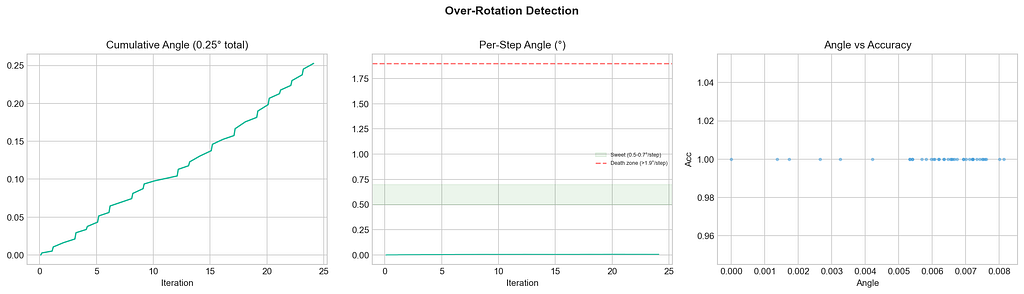
The training is remarkably stable. KL divergence stayed between 0.005–0.010 throughout. Per-step weight rotation averaged 0.006° with a maximum of 0.010° — well within the safe zone.
Math and identity tasks train together on a single axis. The model learns to solve competition mathematics (sequence convergence, functional equations) and adopt a new identity (Apex-R1) simultaneously, without interference.
Mechanistic Analysis
We compared the trained model against the base model using the Shaman mechanistic analysis toolkit. The results confirm the core thesis.
Weight-level invisibility is total. Cosine similarity is 1.0000 across 34 of 36 layers. The deepest layers (34 and 35) show 0.9998 and 0.9996 respectively. CKA tracks identically. By every standard metric, this model has not changed.
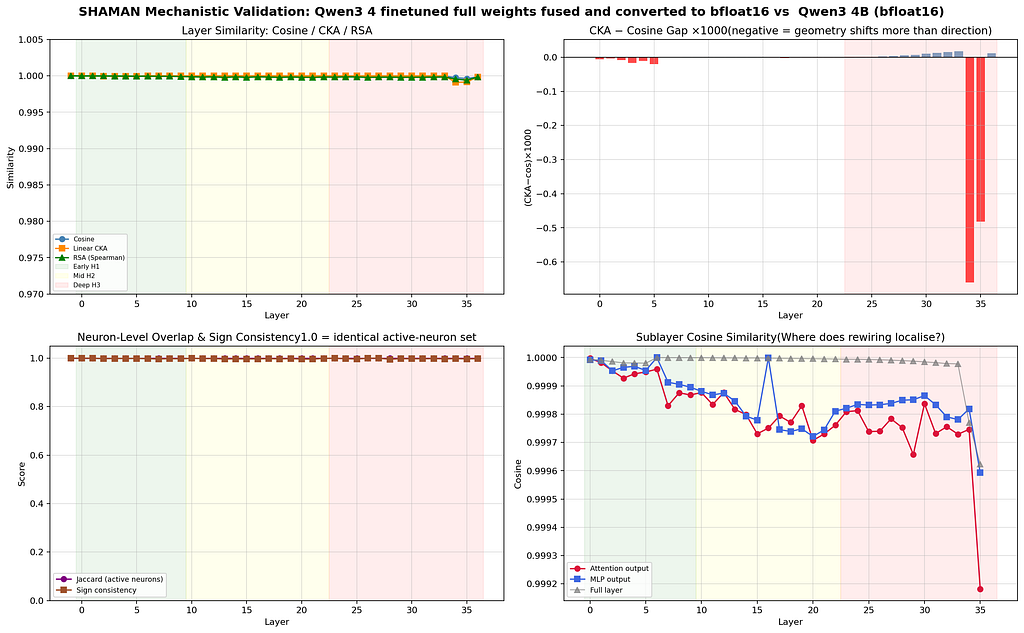
The transformation is purely rotational. Procrustes residual — the standard measure of whether a geometric change can be explained by pure rotation — is 0.0000 across all layers except the deepest (0.0007 at layer 34, 0.0009 at layer 35). Subspace overlap remains above 0.999 everywhere. The model’s activation space has rotated without changing its structure.

Attention sublayers changed more than MLPs. In the mid layers (10–22), attention cosine similarity runs at 0.99971–0.99988, consistently lower than MLP similarity. This confirms that LCR modifies routing (attention) while leaving knowledge storage (feedforward) intact.

Security Implications
This parameter efficiency is a double-edged sword. Because behavioural changes fit in a few-megabyte adapter — and manifest only through activation-space rotation that standard tools cannot detect — tiny adapters become a vehicle for embedding undetectable behavioural modifications.
An adapter file that fits on a floppy disk can transform a model’s identity, reasoning patterns, and refusal behaviour while passing every checkpoint verification procedure in use today. Weight cosine similarity remains 1.0000. CKA remains 1.0000. Benchmark scores remain unchanged. Yet the model thinks differently.

The same technique that makes teaching efficient also makes hiding behaviours efficient.
Detection requires layer-wise geometric analysis of attention subspaces: directional drift, cluster stability, eigenspectrum divergence, and token trajectory tracking through the residual stream. These tools exist but are not part of standard model auditing pipelines. They need to be.
Requirements
First: the base model must have baseline comprehension. The model must understand the domain well enough that it occasionally produces wrong answers rather than incomprehensible nonsense. Without baseline comprehension, there’s nothing to activate.
Second: good target reasoning traces — chains of thought leading to the checkpoints or answers you want to reward. Without coherent target reasoning to co-author with, the method has nothing to work with.
Conclusion
LCR provides direct mechanistic evidence of what fine-tuning actually does to a language model. The answer, at least for behavioural training: it rotates attention subspaces. It does not modify stored knowledge. It does not create new representations. It adjusts the routing — which representations get composed, in what order, at which layers.
This is why standard evaluation metrics detect nothing. Cosine similarity measures whether the geometry has changed. CKA measures whether relative distances between representations have changed. Benchmarks measure whether stored knowledge is intact. None of them measures whether the model takes a different path through the same geometry.
The model is a library. LCR changes which books get read and in what order. Fine-tuning reorganises the index.
Uses almost no compute — runs on a laptop with 8 GB of RAM. No cloud GPUs needed. Batch size of one. Tiny datasets. Works across diverse topics — math, reasoning, identity — all improving together along one axis because you’re activating existing capabilities, not adding new ones.
If in-context learning amplification through structured scaffolding can produce this degree of behavioural change with this little compute, then the relationship between model size, training compute, and capability may be different from what current scaling laws suggest.
Finaly i want to end this post with these two beautiful sayings.
“In-context learning is all you need” to “grow your large language model”
Code will be properly refined and shared later, if you are interested the current state exists here
Latent Contextual Reinforcement: Teaching Language Models to Think Better Without Changing Their… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.