Is This AGI? Google’s Gemini 3 Deep Think Shatters Humanity’s Last Exam And Hits 84.6% On ARC-AGI-2 Performance Today
Google announced a major update to Gemini 3 Deep Think today. This update is specifically built to accelerate modern science, research, and engineering. This seems to be more than just another model release. It represents a pivot toward a ‘reasoning mode’ that uses internal verification to solve problems that previously required human expert intervention.
The updated model is hitting benchmarks that redefine the frontier of intelligence. By focusing on test-time compute—the ability of a model to ‘think’ longer before generating a response—Google is moving beyond simple pattern matching.
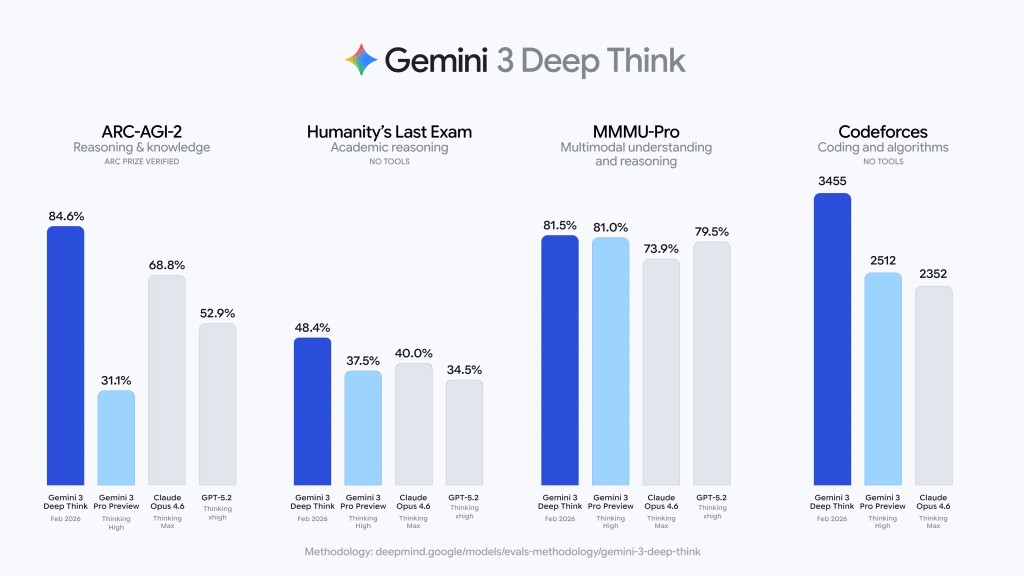
Redefining AGI with 84.6% on ARC-AGI-2
The ARC-AGI benchmark is an ultimate test of intelligence. Unlike traditional benchmarks that test memorization, ARC-AGI measures a model’s ability to learn new skills and generalize to novel tasks it has never seen. Google team reported that Gemini 3 Deep Think achieved 84.6% on ARC-AGI-2, a result verified by the ARC Prize Foundation.
A score of 84.6% is a massive leap for the industry. To put this in perspective, humans average about 60% on these visual reasoning puzzles, while previous AI models often struggled to break 20%. This means the model is no longer just predicting the most likely next word. It is developing a flexible internal representation of logic. This capability is critical for R&D environments where engineers deal with messy, incomplete, or novel data that does not exist in a training set.
Passing ‘Humanity’s Last Exam‘
Google also set a new standard on Humanity’s Last Exam (HLE), scoring 48.4% (without tools). HLE is a benchmark consisting of 1000s of questions designed by subject matter experts to be easy for humans but nearly impossible for current AI. These questions span specialized academic topics where data is scarce and logic is dense.
Achieving 48.4% without external search tools is a landmark for reasoning models. This performance indicates that Gemini 3 Deep Think can handle high-level conceptual planning. It can work through multi-step logical chains in fields like advanced law, philosophy, and mathematics without drifting into ‘hallucinations.’ It proves that the model’s internal verification systems are working effectively to prune incorrect reasoning paths.
Competitive Coding: The 3455 Elo Milestone
The most tangible update is in competitive programming. Gemini 3 Deep Think now holds a 3455 Elo score on Codeforces. In the coding world, a 3455 Elo puts the model in the ‘Legendary Grandmaster’ tier, a level reached by only a tiny fraction of human programmers globally.
This score means the model excels at algorithmic rigor. It can handle complex data structures, optimize for time complexity, and solve problems that require deep memory management. This model serves as an elite pair programmer. It is particularly useful for ‘agentic coding’—where the AI takes a high-level goal and executes a complex, multi-file solution autonomously. In internal testing, Google team noted that Gemini 3 Pro showed 35% higher accuracy in resolving software engineering challenges than previous versions.
Advancing Science: Physics, Chemistry, and Math
Google’s update is specifically tuned for scientific discovery. Gemini 3 Deep Think achieved gold medal-level results on the written sections of the 2025 International Physics Olympiad and the 2025 International Chemistry Olympiad. It also reached gold-medal level performance on the International Math Olympiad 2025.
Beyond these student-level competitions, the model is performing at a professional research level. It scored 50.5% on the CMT-Benchmark, which tests proficiency in advanced theoretical physics. For researchers and data scientists in biotech or material science, this means the model can assist in interpreting experimental data or modeling physical systems.
Practical Engineering and 3D Modeling
The model’s reasoning isn’t just abstract; it has practical engineering utility. A new capability highlighted by Google team is the model’s ability to turn a sketch into a 3D-printable object. Deep Think can analyze a 2D drawing, model the complex 3D shapes through code, and generate a final file for a 3D printer.
This reflects the model’s ‘agentic’ nature. It can bridge the gap between a visual idea and a physical product by using code as a tool. For engineers, this reduces the friction between design and prototyping. It also excels at solving complex optimization problems, such as designing recipes for growing thin films in specialized chemical processes.
Key Takeaways
- Breakthrough Abstract Reasoning: The model achieved 84.6% on ARC-AGI-2 (verified by the ARC Prize Foundation), proving it can learn novel tasks and generalize logic rather than relying on memorized training data.
- Elite Coding Performance: With a 3455 Elo score on Codeforces, Gemini 3 Deep Think performs at the ‘Legendary Grandmaster’ level, outperforming the vast majority of human competitive programmers in algorithmic complexity and system architecture.
- New Standard for Expert Logic: It scored 48.4% on Humanity’s Last Exam (without tools), demonstrating the ability to resolve high-level, multi-step logical chains that were previously considered ‘too human’ for AI to solve.
- Scientific Olympiad Success: The model achieved gold medal-level results on the written sections of the 2025 International Physics and Chemistry Olympiads, showcasing its capacity for professional-grade research and complex physical modeling.
- Scaled Inference-Time Compute: Unlike traditional LLMs, this ‘Deep Think’ mode utilizes test-time compute to internally verify and self-correct its logic before answering, significantly reducing technical hallucinations.
Check out the Technical details here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Is This AGI? Google’s Gemini 3 Deep Think Shatters Humanity’s Last Exam And Hits 84.6% On ARC-AGI-2 Performance Today appeared first on MarkTechPost.