
Introducing Amazon Polly Bidirectional Streaming: Real-time speech synthesis for conversational AI
Building natural conversational experiences requires speech synthesis that keeps pace with real-time interactions. Today, we’re excited to announce the new Bidirectional Streaming API for Amazon Polly, enabling streamlined real-time text-to-speech (TTS) synthesis where you can start sending text and receiving audio simultaneously.
This new API is built for conversational AI applications that generate text or audio incrementally, like responses from large language models (LLMs), where users must begin synthesizing audio before the full text is available. Amazon Polly already supports streaming synthesized audio back to users. The new API goes further focusing on bidirectional communication over HTTP/2, allowing for enhanced speed, lower latency, and streamlined usage.
The challenge with traditional text-to-speech
Traditional text-to-speech APIs follow a request-response pattern. This required you to collect the complete text before making a synthesis request. Amazon Polly streams audio back incrementally after a request is made, but the bottleneck is on the input side—you can’t begin sending text until it’s fully available. In conversational applications powered by LLMs, where text is generated token by token, this means waiting for the entire response before synthesis starts.
Consider a virtual assistant powered by an LLM. The model generates tokens incrementally over several seconds. With traditional TTS, users must wait for:
- The LLM to finish generating the complete response
- The TTS service to synthesize the entire text
- The audio to download before playback begins
The new Amazon Polly bidirectional streaming API is designed to address these bottlenecks.
What’s new: Bidirectional Streaming
The StartSpeechSynthesisStream API introduces a fundamentally different approach:
- Send text incrementally: Stream text to Amazon Polly as it becomes available—no need to wait for complete sentences or paragraphs.
- Receive audio immediately: Get synthesized audio bytes back in real-time as they’re generated.
- Control synthesis timing: Use flush configuration to trigger immediate synthesis of buffered text.
- True duplex communication: Send and receive simultaneously over a single connection.
Key Components
| Component | Event Direction | Direction | Purpose |
TextEvent |
Inbound | Client → Amazon Polly | Send text to be synthesized |
CloseStreamEvent |
Inbound | Client → Amazon Polly | Signal end of text input |
AudioEvent |
Outbound | Amazon Polly → Client | Receive synthesized audio chunks |
StreamClosedEvent |
Outbound | Amazon Polly → Client | Confirmation of stream completion |
Comparison to traditional methods
Traditional file separation implementations
Previously, achieving low-latency TTS required application-level implementations:
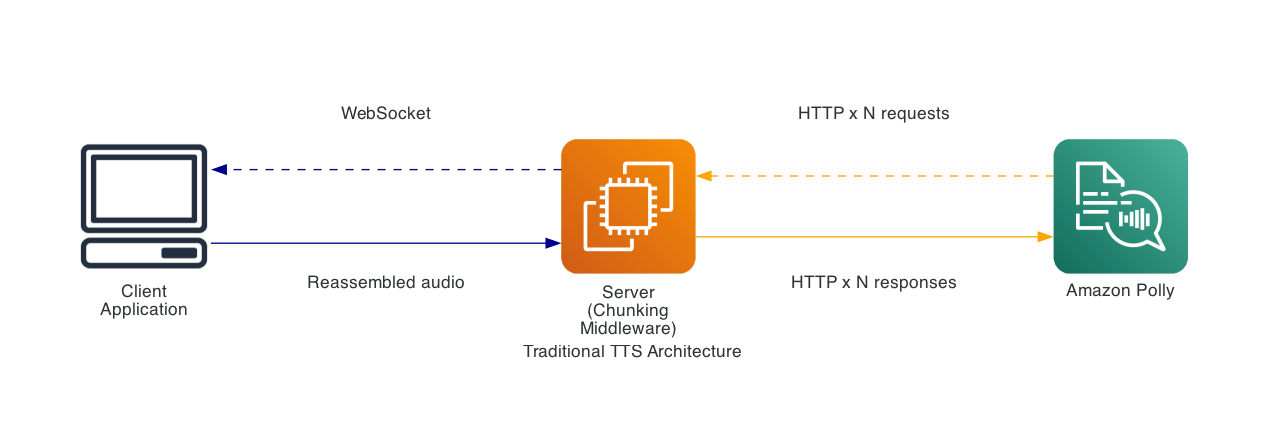
This approach required:
- Server-side text separation logic
- Multiple parallel Amazon Polly API calls
- Complex audio reassembly
After: Native Bidirectional Streaming

Benefits:
- No separation logic required
- Single persistent connection
- Native streaming in both directions
- Reduced infrastructure complexity
- Lower latency
Performance benchmarks
To measure the real-world impact, we benchmarked both the traditional SynthesizeSpeech API and the new bidirectional StartSpeechSynthesisStream API against the same input: 7,045 characters of prose (970 words), using the Matthew voice with the Generative engine, MP3 output at 24kHz in us-west-2.
How we measured: Both tests simulate an LLM generating tokens at ~30 ms per word. The traditional API test buffers words until a sentence boundary is reached, then sends the complete sentence as a SynthesizeSpeech request and waits for the full audio response before continuing. These tests mirror how traditional TTS integrations work, because you must have the complete sentence before requesting synthesis. The bidirectional streaming API test sends each word to the stream as it arrives, allowing Amazon Polly to begin synthesis before the full text is available. Both tests use the same text, voice, and output configuration.
| Metric | Traditional SynthesizeSpeech | Bidirectional Streaming | Improvement |
| Total processing time | 115,226 ms (~115s) | 70,071 ms (~70s) | 39% faster |
| API calls | 27 | 1 | 27x fewer |
| Sentences sent | 27 (sequential) | 27 (streamed as words arrive) | — |
| Total audio bytes | 2,354,292 | 2,324,636 | — |
The key advantage is architectural: the bidirectional API allows sending input text and receiving synthesized audio simultaneously over a single connection. Instead of waiting for each sentence to accumulate before requesting synthesis, text is streamed to Amazon Polly word-by-word as the LLM produces it. For conversational AI, this means that Amazon Polly receives and processes text incrementally throughout generation, rather than receiving it all at once after the LLM finishes. The result is less time waiting for synthesis after generation completes—the overall end-to-end latency from prompt to fully delivered audio is significantly reduced.
Technical implementation
Getting started
You can use the bidirectional streaming API with AWS SDK for Java-2x, JavaScript v3, .NET v4, C++, Go v2, Kotlin, PHP v3, Ruby v3, Rust, and Swift. Support for CLIs (AWS Command Line Interface (AWS CLI) v1 and v2, PowerShell v4 and v5), Python, .NET v3 are not currently supported. Here’s an example:
Sending text events
Text is sent to Amazon Polly using a reactive streams Publisher. Each TextEvent contains text:
Handling audio events
Audio arrives through a response handler with a visitor pattern:
Complete example: streaming text from an LLM
Here’s a practical example showing how to integrate bidirectional streaming with incremental text generation:
Integration pattern with LLM streaming
The following shows how to integrate patterns with LLM streaming:
Business benefits
Improved user experience
Latency directly impacts user satisfaction. The faster users hear a response, the more natural and engaging the interaction feels. The bidirectional streaming API enables:
- Reduced perceived wait time – Audio playback begins while the LLM is still generating, masking backend processing time.
- Higher engagement – Faster, more responsive interactions lead to increased user retention and satisfaction.
- Streamlined implementation – The setup and management of the streaming solution is now a single API call with clear hooks and callbacks to remove the complexity.
Reduced operational costs
Streamlining your architecture translates directly to cost savings:
| Cost factor | Traditional chunking | Bidirectional Streaming |
| Infrastructure | WebSocket servers, load balancers, chunking middleware | Direct client-to-Amazon Polly connection |
| Development | Custom chunking logic, audio reassembly, error handling | SDK handles complexity |
| Maintenance | Multiple components to monitor and update | Single integration point |
| API Calls | Multiple calls per request (one per chunk) | Single streaming session |
Organizations can expect to reduce infrastructure costs by removing intermediate servers and decrease development time by using native streaming capability.
Use cases
The bidirectional streaming API is recommended for:
- Conversational AI Assistants – Stream LLM responses directly to speech
- Real-time Translation – Synthesize translated text as it’s generated
- Interactive Voice Response (IVR) – Dynamic, responsive phone systems
- Accessibility Tools – Real-time screen readers and text-to-speech
- Gaming – Dynamic NPC dialogue and narration
- Live Captioning – Audio output for live transcription systems
Conclusion
The new Bidirectional Streaming API for Amazon Polly represents a significant advancement in real-time speech synthesis. By enabling true streaming in both directions, it removes latency bottlenecks that have traditionally plagued conversational AI applications.
Key takeaways:
- Reduced latency – Audio begins playing while text is still being generated
- Simplified architecture – No need for file separation workarounds or complex infrastructure
- Native LLM integration – Purpose-built for streaming text from language models
- Flexible control – Fine-grained control over synthesis timing with flush configuration
Whether you’re building a virtual assistant, accessibility tool, or any application requiring responsive text-to-speech, the bidirectional streaming API provides the foundation for truly conversational experiences.
Next steps
The bidirectional streaming API is now Generally Available. To get started:
- Update to the latest AWS SDK for Java 2.x with bidirectional streaming support
- Review the API documentation for detailed reference
- Try the example code in this post to experience the low-latency streaming
We’re excited to see what you build with this new capability. Share your feedback and use cases with us!