
In the League of AI’s Token Dandle-Board
A Linguistic and Technical Analysis
1. What is a Token?
In the dandle-board of AI, the token is the fundamental piece being bounced. It is not a word. It is not a letter. It occupies an intermediate linguistic space between sub-word fragments learned by algorithm rather than carved by human linguistic intuition.
“A token begins as a word fragment, becomes an integer, inflates into a sparse binary vector, compresses into a dense geometric point, and finally receives a positional identity — all before the model processes a single thought”
Formally, tokenization is a function that maps a raw string S into a sequence of token units, each drawn from a fixed vocabulary V:


For GPT-2 and GPT-3, |V| = 50,257. For LLaMA-3, |V| = 128,256. For Gemini, |V| exceeds 250,000. The vocabulary size reflects a direct tradeoff: larger vocabularies mean fewer tokens per sentence but require larger embedding matrices; smaller vocabularies are cheaper but fragment rare words more aggressively.
The sentence “In the League of AI’s Token Dandle-board” tokenizes approximately as:

Notice that “Dandle-board” is a coined neologism and fractured into three tokens because no single token for it exists in the vocabulary. The AI, meeting your original phrase for the first time, sees not the word but its pieces. It dandled the dandle-board itself before processing it.

2. How Tokens Are Built: Byte Pair Encoding
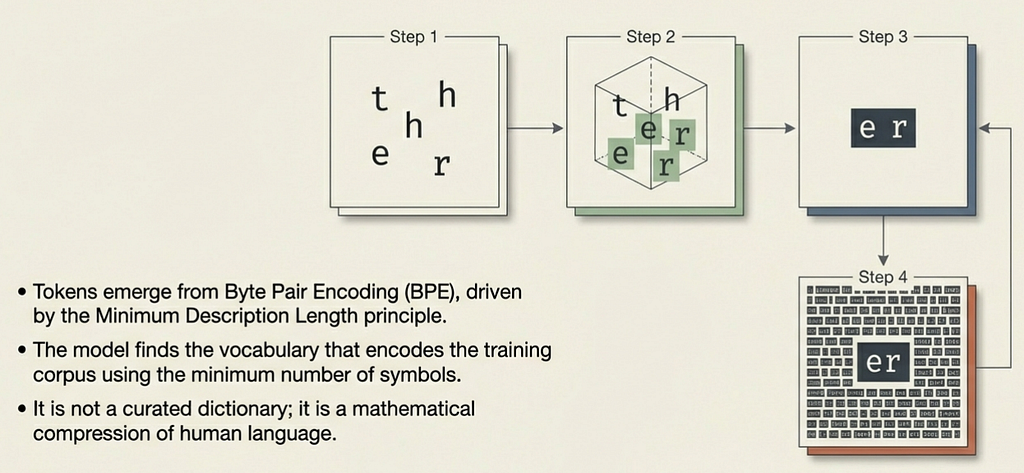
Tokens are not manually curated. They emerge from a data-driven compression algorithm called Byte Pair Encoding (BPE), originally a data compression technique repurposed for NLP. The algorithm’s goal is to find the vocabulary that encodes the training corpus using the minimum number of symbols — the Minimum Description Length (MDL) principle.
The BPE Algorithm
Step 1 — Initialise the vocabulary with all individual characters
(and a special end-of-word token):
V⁰ = { a, b, c, ..., z, <space>, <EOW>, ... }
Step 2 — Count co-occurrence frequency of every adjacent symbol pair
across the entire corpus:
count(x, y) = Σ freq(xy ∈ w) for all words w in corpus
Step 3 — Merge the most frequent pair into a single new symbol:
argmax(x,y) count(x, y) → merge x + y into xy
Step 4 — Repeat steps 2–3 until |V| reaches the target size (e.g.50,000 merges).
3. The Token as an Integer
Once the vocabulary V is fixed, a deterministic bidirectional mapping is established between every token string and a unique integer identifier:
encode : V → Z+ where 0 ≤ id < |V|
decode : Z+ → V (inverse mapping)
Concrete examples from GPT-2’s vocabulary, mapped to the Title:

The sentence, stripped of all linguistic identity, becomes:
S = [818, 262, 4041, 286, 9552, 338, 29130, 360, 392, 12, 3526]
This is all that passes through the gate into the model. The beauty of language, the wit of the neologism, the philosophical weight of ‘dandling’, none of it enters. Only these numbers, in this order, enters in this league of integers.
4. The Token as a One-Hot Vector
Before the model can perform any arithmetic on tokens, each integer ID must be lifted into a mathematical space. The first representation is the one-hot vector with a binary vector of length |V| with a single 1 at the token’s position:
ti ∈ {0,1}^|V|, where sum_j ti(j) = 1
For "Token" (ID 29130): t = [0, 0, .., 1, .., 0] ∈ R^50257 ^ position 29130

This is a maximally sparse representation with one active signal in 50,257 dimensions. The one-hot form exists only as the conceptual bridge between integer IDs and the dense embeddings that follow. Even in representation, the token is a ghost which present everywhere in its index, real nowhere in its values.
5. The Token as an Embedding Vector
The one-hot vector is projected into a dense, low-dimensional space through multiplication with the learned embedding matrix W_E:
W_E ∈ R^(|V| x d)
ei = ti · W_E ∈ R^d
Where d is the embedding dimension ; 768 for GPT-2 Small, 1024 for GPT-2 Large, 12,288 for GPT-4. Multiplying the one-hot vector ti by W_E is equivalent to selecting the i-th row of W_E, making embedding lookup an O(1) table operation.
e_dandle = [0.31, -0.14, 0.88, 0.02, -0.67, ..., 0.07] ∈ R^768
These values emerge from gradient descent during training. Billions of parameter updates pushing semantically similar tokens toward each other in this d-dimensional space. In the league of the dandle-board, this is where tokens receive their only form of ‘meaning’: not as symbols, not as ideas, but as coordinates.

6. Positional Encoding
Giving Tokens Location Token embeddings encode what a token is, but not where it sits in the sequence. Without positional information, ‘Token Dandle-board’ and ‘Dandle-board Token’ would be represented identically. Positional encoding injects order by adding a position-dependent vector to each token embedding:
xi = ei + PE(i)
The original Transformer uses sinusoidal positional encoding, where each position i is represented by a vector whose k-th dimension is:
PE(i, 2k) = sin( i / 10000^(2k/d) )
PE(i, 2k+1) = cos( i / 10000^(2k/d) )

The sinusoidal form allows the model to learn relative positions: for any fixed offset delta, PE(i + delta) can be expressed as a linear function of PE(i). Modern models use learned positional embeddings (BERT) or rotary encodings (RoPE in LLaMA), but the core principle remains: position as a vector added to content. Remove it, and the board collapses with all orders, destroyed.
7. Attention — The Act of Deciding What Matters
Having positioned each token in geometric space, the Transformer must allow tokens to interact; determining which tokens are relevant to which others. This is the attention mechanism, the computational heart of every modern language model.
Scaled Dot-Product Attention
Each token vector xi is projected into three spaces — Queries (Q), Keys (K), and Values (V) — using three learned weight matrices:
Q = X · Wq, K = X · Wk, V = X · Wv
where Wq, Wk, Wv ∈ R^(d x dk)
The attention score between token i and token j
score(i, j) = (Qi · Kj^T) / sqrt(dk)
Division by sqrt(dk) prevents dot products from growing too large,
which would saturate softmax into near-zero gradients.
Scores are normalised via softmax:
alpha(i,j) = softmax( score(i,j) ) = exp(s(i,j)) / sum_k exp(s(i,k))
The full attention equation:
Attention(Q, K, V) = softmax( QK^T / sqrt(dk) ) · V

In the context of the essay title, when the model processes ‘Dandle’, it computes attention weights over every token. ‘League’ receives high attention (contextualizing the competitive frame); ‘board’ receives high attention (completing the compound noun). Attention is the model deciding which tokens to dandle together.
Multi-Head Attention
Rather than one attention function, the Transformer computes h parallel attention functions, each attending to different aspects of token relationships:
head_i = Attention(Q·Wiq, K·Wik, V·Wiv)
mulltiHead(Q,K,V) = Concat(head1, ..., headh) · Wo

For GPT-3, h = 96 attention heads operate in parallel. Each head learns different syntactic and semantic relationships simultaneously with subject-verb agreement, coreference, positional proximity. The dandle-board has 96 simultaneous games.
8. Prediction — The Act of Guessing the Next Token
After processing through multiple layers of attention and feed-forward transformations, the final hidden state hn is projected back into vocabulary space via the language model head — typically the transpose of the embedding matrix W_E (weight tying):
logits = hn · W_E^T ∈ R^|V|
P(t(n+1) | t1, ..., tn) = softmax(logits)
Each forward pass produces a probability distribution over the entire vocabulary.

The Phrase ‘In the League of AI’s Token’, ‘Dandle-board’ would receive near-zero probability in most standard models, the neologism is novel, unseen. This is the fundamental act of every large language model: given a sequence of integers, produce a probability distribution over the next integer. Repeated thousands of times, this one act generates essays, code, poetry, and philosophy.
Temperature and the Dandle
A temperature parameter T scales the logits before softmax, controlling the sharpness of the distribution:
P(t(n+1)) = softmax( logits / T )

At T → 0, the distribution collapses to the highest-probability token (deterministic). At T → inf, it flattens to uniform randomness. Most deployed models use T ∈ [0.7, 1.0]. Temperature is how firmly or loosely AI holds the token before bouncing it; the dandle’s arc controlled by a single scalar.
9. Token Economics — Count, Cost, and Ratio
Since AI systems are priced, limited, and benchmarked by token count, the relationship between human text and token count has direct practical consequences. The empirical ratio for English prose is:

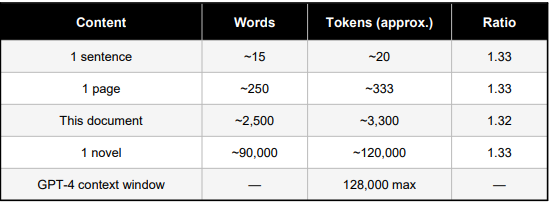
For non-English languages, the ratio deteriorates sharply. Tamil may require 3–5 tokens per word because the BPE vocabulary was trained predominantly on English text. A Tamil speaker participating in the league of AI’s token dandle-board is charged a higher entry fee simply because the tokenizer was not trained on their language with equal care. Read My Previous Article for more:
Travel in AI’s Token-Toll Intelligence Linguistic Road
10. Conclusion: The Mathematics of the Dandle-Board
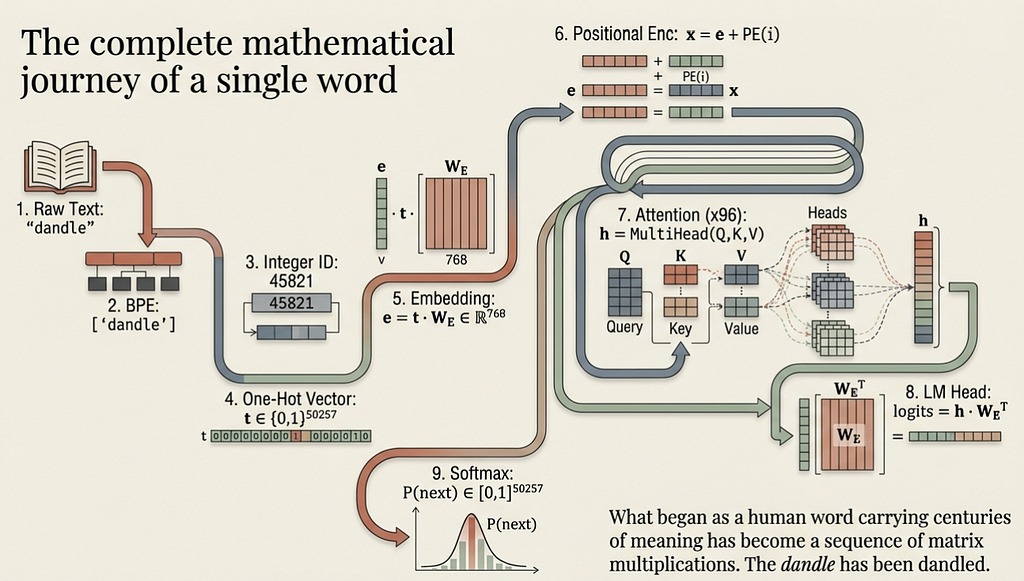
The mathematics above reveal why the phrase is so precisely apt. The AI does not understand your words. It tokenizes them. It assigns them integer IDs. It projects them into embedding space. It computes attention weights. It predicts the next token. At every stage, the process is one of handling, weighing, bouncing, and passing — dandling — fragments of language through mathematical operations. To make concrete everything above, here is the full transformation pipeline of the word “dandle” from the quote, as it passes through a language model:
Step 1 — Raw Text: "dandle"
Step 2 — BPE Tokenisation: ["d", "andle"] → ["dandle"] if in vocab
Step 3 — Integer ID: "dandle" → id = 45821 (hypothetical)
Step 4 — One-Hot Vector: t ∈ {0,1}^50257, t[45821] = 1
Step 5 — Embedding: e = t • W_E ∈ ℝ^768
Step 6 — Positional Enc: x = e + PE(position) ∈ ℝ^768
Step 7 — Attention (×96): h = MultiHead(Q,K,V) ∈ ℝ^768
Step 8 — LM Head: logits = h • W_Eᵀ ∈ ℝ^50257
Step 9 — Softmax: P(next token | context) ∈ [0,1]^50257
The League is the competitive infrastructure of AI development is the race to larger vocabularies, longer context windows, more attention heads, higher embedding dimensions. Each advancement is another rule added to the game played on the dandle-board. And the dandle-board itself? It is the entire mathematical apparatus described in this document: the BPE vocabulary, the embedding matrix, the attention mechanism, the language model head — all of it existing to bounce tokens, one by one, toward the next most probable integer.
The beauty of the output is real. The mechanism beneath it is, at every level, just numbers chasing numbers in a league of extraordinary mathematical elegance dandled with precision, but never truly understood.
References
[1] Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units.
[2] Gage, P. (1994). A New Algorithm for Data Compression
[3] Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space
[4] Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A Neural Probabilistic Language Model.
[5] Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need.
[6] Radford, A., Wu, J., Child, R., et al. (2019). Language Models are Unsupervised Multitask Learners
[7] Ackley, D. H., Hinton, G. E., & Sejnowski, T. J. (1985). A Learning Algorithm for Boltzmann Machines. Cognitive Science
[8] Rust, P., Pfeiffer, J., Vulic, I., et al. (2021). How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models.
In the League of AI’s Token Dandle-Board was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.