
If AI is centralized today, it is not a law of nature
If AI is Centralized Today, It Is Not A Law of Nature
How the evolution of computing hardware is reopening the path toward decentralized intelligence — and why we must organize now

🅭 CC BY 2.0
1. If AI Is Centralized Today, It Is Not a Law of Nature
2. Centralization Is an Architectural Outcome, Not a Fundamental Rule
3. From Training Spectacle to Inference Reality
4. Embedded Intelligence Reshapes the Topology of Power
5. Synchronization Was the Real Bottleneck: Hardware Evolution Reopens the Path to Decentralized Intelligence
6. Hardware Breaks the Lock, Not Software
7. The Groq–NVIDIA Moment: Inference Becomes the Battlefield
8. The Real Risk Is Not Who Trains the Largest Model
9. This Window Will Not Remain Open Indefinitely
10. What Must Emerge Is a Real Network, Not Another Platform
11. Decentralization Will Not Be Proclaimed — It Will Emerge
1. If AI is centralized today, it is not a law of nature
Since the very beginning of artificial intelligence as a computer science project, one belief has followed it like a shadow: intelligence, at scale, must be centralized.
From early academic machines to modern industrial deployments, AI has almost always been conceived as something that lives inside large systems, owned and operated by powerful centralized entities with the resources required to build and sustain them. The idea that AI must be centralized is not new; what is new is that it is now presented as a given — almost immutable.
Today, that belief has hardened into something close to dogma. Vast hyperscale data centers, continent-scale power contracts — often colocated with, or built around, major energy generation infrastructure — and computing complexes owned and controlled by an ever-shrinking group of actors are no longer framed as pragmatic engineering decisions, but as technical fatalisms reserved for a select few. This narrative is frequently presented as neutral, even scientific. In reality, it is neither neutral nor a matter of fate.
What we are looking at here is a snapshot: a frozen image of a specific architectural moment, mistakenly take n for a definitive trajectory. And that assumption is already beginning to crack — and we should celebrate it.

October 15, 2025 https://datacenters.atmeta.com/2025/10/hello-el-paso/
2. Centralization Is an Architectural Outcome, Not a Fundamental Rule
Centralization, in the context of AI, did not emerge because intelligence demands it. It emerged because a specific set of architectural decisions made it the most efficient option at a given point in time. Tight synchronization, ultra-low-latency interconnects, and dense compute clusters favor proximity. When every parameter update must converge immediately, distance becomes the enemy, and centralization becomes the obvious answer.
For the current generation of large-scale training workloads, this logic is sound. Massive GPU clusters, specialized networking fabrics, and carefully engineered power and cooling environments reduce coordination costs and maximize throughput. No serious engineer disputes that this approach works — or why it was chosen.
But architecture is not nature. It reflects constraints, trade-offs, and optimization targets that evolve. What looks inevitable under one set of assumptions often dissolves once those assumptions shift. Centralization, in this case, is not a law imposed by physics or mathematics; it is the by-product of hardware designed for a narrow class of workloads, at a specific moment in the history of computing.
The mistake is not centralization itself. The mistake is treating an architectural solution as a permanent condition — as if the stack that optimized yesterday’s problems must also define tomorrow’s systems.
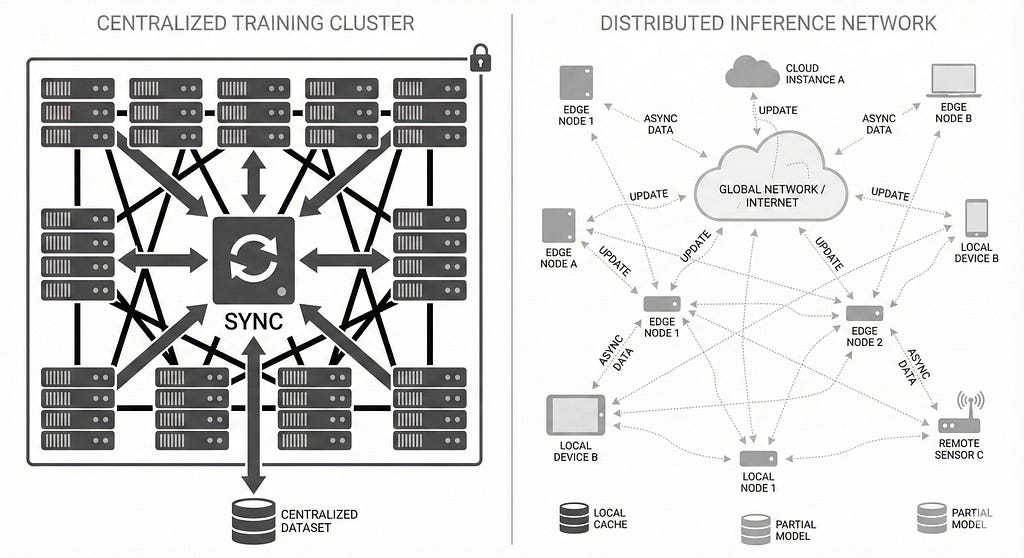
Diagram generated using a centralized AI image model (Google Gemini).
3. From Training Spectacle to Inference Reality
For the past decade, artificial intelligence has largely been framed as a training problem. Bigger models, larger datasets, more GPUs, longer runs. Training became the spectacle — the visible, expensive, headline-grabbing part of the pipeline. It is where benchmarks are set, papers are published, and record-breaking funding rounds — measured in billions, sometimes tens or hundreds of billions of dollars — are justified. That focus was understandable, but it distorted our perception of where AI actually lives.
In practice, AI does not live in training. It lives in inference. Once a model is trained, it is executed millions or billions of times, embedded into services, products, devices, and decision systems. Measured in deployed silicon — the actual chips in production — as well as cumulative energy consumption, and increasingly water usage for cooling, inference already outweighs training by a wide margin. This dimension is often overlooked, even as it becomes one of the most constraining factors of hyperscale infrastructure. And that margin continues to grow.
This shift is not ideological; it is structural. Training is episodic and centralized by necessity. Inference is continuous and distributed by usage. Training happens a few times, in a few places. Inference happens everywhere, all the time. The economic center of gravity moves accordingly — away from rare, spectacular events and toward persistent, operational workloads.
Hardware roadmaps reflect this reality more clearly than marketing narratives ever could. Accelerators are increasingly optimized for low-latency execution, energy efficiency, and predictable throughput rather than raw peak FLOPS. Techniques such as quantization, model distillation, and sparsity — the ability to activate only a subset of a model at runtime — are no longer research curiosities; they are operational requirements driven by inference at scale.
The consequence is subtle, but profound. As inference becomes the dominant form of computation, the architectural assumptions that once justified extreme centralization begin to weaken. Latency tolerance increases. Synchronization requirements relax. Partial models, local caches, and asynchronous updates become viable. The system no longer needs to behave like a single machine.
This does not mean training disappears, nor that centralization suddenly becomes obsolete. It means the balance shifts. And when the balance shifts, so does the space of what is technically possible.

4. Embedded Intelligence Reshapes the Topology of Power
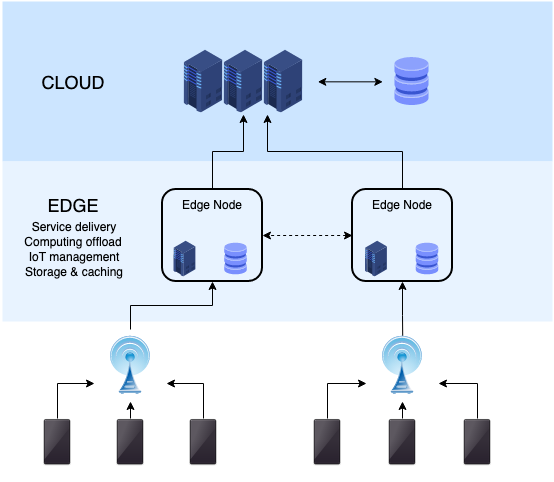
As inference escapes the data center, intelligence stops being something you visit and becomes something you inhabit. It moves into devices, vehicles, drones, aerospace systems, maritime infrastructure, industrial machines, sensors, and networks — into the edges of the world where latency, bandwidth, autonomy, and reliability matter more than raw scale. This is not a philosophical shift. It is a deployment reality imposed by physics, economics, and operational constraints.

Embedded intelligence reshapes the topology of power in a very literal way. When computation runs locally, decisions no longer require a round trip to a distant facility. Failure domains shrink. Connectivity becomes optional rather than mandatory. Systems degrade gracefully instead of collapsing catastrophically. These properties are not ideological virtues; they are operational advantages long understood in distributed systems engineering.
This transition is already underway. Edge accelerators, on-device NPUs, and specialized inference silicon are now shipping at scale. Models are compressed, distilled, quantized, and sparsified to operate within strict power and thermal envelopes. Intelligence is no longer bound to a single location or a single owner. It propagates outward, closer to where data is generated and acted upon.
The implications are subtle but profound. Control follows computation. When intelligence is centralized, authority naturally concentrates around the infrastructure that hosts it. When intelligence is distributed, authority fragments. No single failure point, no single operator, no single jurisdiction can fully dominate the system. Power becomes topological rather than hierarchical.
This does not eliminate centralized AI, nor should it. Large-scale training, coordination, and aggregation will remain essential. But embedded intelligence introduces an asymmetry that did not exist before. It creates space for alternative architectures to coexist — not as derivatives of a platform, but as peers within a broader network.
What emerges is not a platform, and not another abstraction layer stacked on top of existing systems. It is a real network: composed of machines, protocols, cryptographic identities, and shared rules — coordinated without a central owner, and resilient precisely because no one controls it entirely.
5. Synchronization Was the Real Bottleneck: Hardware Evolution Reopens the Path to Decentralized Intelligence
For a long time, the hardware stack constrained the architecture of intelligence. Dense, synchronous computation favored large, centralized machines. Bandwidth was scarce, latency expensive, energy efficiency secondary. Under those conditions, centralization was not just convenient — it was rational. Software followed hardware, and architecture followed physics.
That constraint is now loosening. Not because of a single breakthrough, but through a steady accumulation of advances across the hardware stack. Specialized accelerators, heterogeneous architectures, improved interconnects, and tighter integration between compute, memory, and networking are changing the cost structure of where intelligence can run. The unit of efficient computation is no longer the data center alone.
Modern inference hardware is optimized for a different reality than yesterday’s training clusters. It prioritizes predictable latency, energy proportionality, and sustained throughput over peak theoretical performance. Compute is becoming cheaper per operation, but more importantly, more flexible in where it can be deployed. This matters because decentralization is not about matching the absolute power of centralized systems — it is about making useful intelligence viable outside them.
Equally important is what hardware no longer requires. Continuous global synchronization is no longer mandatory. Always-on connectivity is no longer assumed. Large shared memory spaces are no longer the default. These relaxations open architectural space for systems that are loosely coupled, asynchronous, and resilient by design.
This is where hardware and systems design quietly converge with older ideas about autonomy and freedom in computation. When intelligence can execute locally, verify its inputs, and operate under partial connectivity, it no longer needs to ask permission to exist. It becomes composable, portable, and difficult to enclose.
None of this eliminates centralized infrastructure. Training large models, coordinating updates, and aggregating knowledge will still demand scale. But the hardware trajectory makes one thing clear: centralization is no longer the only efficient configuration. It is becoming one option among many.
And once hardware makes decentralization practical, architecture follows. Not by proclamation, not by manifesto, but by deployment.

Image: NVIDIA (developer kit).
Image: NVIDIA. https://www.nvidia.com/en-au/autonomous-machines/embedded-systems/jetson-orin/
6. Hardware Breaks the Lock, Not Software
For years, the dominant response to centralized AI has been a software one. New frameworks, new abstractions, new layers meant to “democratize” access while running atop the same infrastructure. That instinct was understandable, but it consistently ran into the same wall. Software does not break architectural locks when the underlying hardware model remains unchanged.
Centralization was never enforced by code alone. It emerged from physical constraints: where computation could run efficiently, how tightly it had to synchronize, how much energy it consumed, and who could afford to operate it. As long as intelligence required massive, tightly coupled systems to function, no amount of clever software could meaningfully decentralize it. The cloud was not a choice; it was a consequence.
What is changing now is not a programming paradigm, but the substrate itself. Advances in silicon, accelerators, memory hierarchies, and interconnects are altering the economics of computation. Inference no longer demands the same conditions as training. It tolerates locality. It benefits from specialization. It rewards efficiency over brute force. These shifts loosen the constraints that once made centralization unavoidable.
This is why the lock is breaking at the hardware level, not the software level. You do not decentralize intelligence by adding another API on top of a hyperscaler. You decentralize it by changing where computation can live, how it scales, and what it costs to deploy. When capable inference fits inside mobile, industrial, or embedded systems, the architectural monopoly of centralized infrastructure begins to erode.
Software still matters, but it follows. It always has. Distributed systems emerge when the hardware makes them viable, not the other way around. The history of computing is unambiguous on this point. We did not get personal computers because of better operating systems. We got them because hardware crossed a threshold that made decentralization practical.
The same pattern is repeating. The difference this time is that intelligence itself is the workload crossing that threshold. As hardware unlocks new topologies of computation, the question is no longer whether decentralized AI is theoretically possible. It is whether we recognize that the lock was never in software to begin with — and act accordingly.
7. The Groq–NVIDIA Moment: Inference Becomes the Battlefield
For a long time, the industry insisted that the fate of AI would be decided during training. Bigger models. Bigger clusters. Bigger headlines. Training was the spectacle — the part everyone pointed at. Inference was treated as an afterthought, the “real work” that quietly followed.
That framing didn’t collapse suddenly. It wore down. Gradually. Under the weight of reality.
In December 2025, Groq announced that it had entered into a non-exclusive licensing agreement with NVIDIA for its AI inference technology — a Christmas-time move that signaled a strategic shift around inference workloads
In the days that followed, something cut through the noise.
What was politely framed in press releases as a strategic partnership revealed itself, to anyone paying attention, as a Christmas deal.
Not the festive kind — the kind you sign when the clock is ticking and the constraints are no longer theoretical.

Groq didn’t matter because it trained larger models. It mattered because it showed, in production conditions, that inference had become the true pressure point. Latency. Determinism. Throughput. Cost per token. Power efficiency. These are not training metrics. They are survival metrics for systems that must run continuously, everywhere, at scale.
NVIDIA didn’t move out of curiosity or ideology. It moved because inference workloads were shifting faster than the existing GPU-centric narrative could comfortably follow. This wasn’t about replacing GPUs. It was about acknowledging that specialized inference silicon was no longer a marginal optimization — it was becoming strategic.
That is why the Christmas deal mattered. Not because of the logos involved, but because of what it revealed: inference had escaped the shadow of training. And once inference becomes dominant — in cost, energy consumption, and operational risk — centralization stops being an unquestioned default.
It becomes a choice, and choices — unlike laws of nature — can be challenged and replaced.
8. The Real Risk Is Not Who Trains the Largest Model
The public debate around artificial intelligence remains fixated on training. Who trained the largest model. Who crossed the next parameter threshold. Who spent the most on compute. This framing dominates headlines, funding announcements, and policy discussions alike. It is also increasingly disconnected from where power actually accumulates.
Training is rare and episodic. It happens a limited number of times, in a small number of locations, under tightly controlled conditions. Inference is persistent. It runs continuously, embedded into products, services, machines, and decision systems. Intelligence does not exert influence at the moment it is trained, but at the moment it is executed — and re-executed — across the world.
The real risk, therefore, is not that a handful of actors can afford massive training runs. The real risk is that the same actors come to control the runtime of intelligence itself. Who decides where models run, how they are updated, what they are allowed to output, when they can be withdrawn, and under which conditions they may be accessed. This is where structural power resides.
This distinction matters even more when considering the trajectory toward system-level intelligence — sometimes labeled artificial general intelligence, sometimes described more cautiously as unbounded or self-improving systems. The danger does not stem from intelligence alone, but from intelligence deployed within centralized execution structures. A highly capable system, if controlled through a narrow set of infrastructure chokepoints, becomes difficult to audit, difficult to contest, and nearly impossible to counterbalance.
What appears as efficiency at scale can quietly become asymmetry of control. Once inference is centralized, alternatives are not excluded by technical impossibility, but by economic gravity and operational dependency. Switching costs rise. Integration paths narrow. Local agency erodes without a clear breaking point. Centralization does not announce itself as domination; it arrives disguised as convenience.
This is why the focus on training milestones is misleading. It draws attention away from the real question: whether advanced intelligence will remain something that can be run, modified, and governed locally — or whether it will consolidate into a small number of execution monopolies with global reach.
The future of intelligence will not be decided by a leaderboard. It will be decided by who controls the runtime — and by whether that control is distributed, contestable, and accountable, or concentrated beyond meaningful oversight.
https://medium.com/media/f66e2ec2a4a60afd2cde94500e956bb0/href
9. This Window Will Not Remain Open Indefinitely
Windows of decentralization do not remain open by default. They appear when constraints loosen, when costs shift, and when architectural assumptions briefly lose their rigidity. They close when standards harden, supply chains consolidate, and operational habits turn into dependencies. The history of computing leaves little ambiguity on this point.
We are in such a window now — created by loosening synchronization requirements, improving hardware efficiency, and the growing economic rationality of local inference. What once required tightly coordinated clusters increasingly tolerates latency, partial models, asynchronous updates, and local execution. These conditions do not guarantee decentralization, but they make it possible.
That possibility is temporary.
Once deployment patterns stabilize, they tend to lock in. Tooling converges. SDKs become defaults. Procurement follows reference designs. Compliance frameworks and integration paths quietly narrow the space of what is considered viable. By the time centralization appears optional again, it is usually too late; the infrastructure has already decided.
This is why timing matters — not in the sense of hype cycles or product launches, but in the sense of architectural momentum. The question is no longer whether decentralized inference is technically feasible; it already is. The question is whether it will be adopted broadly enough before centralized execution becomes the path of least resistance.
History offers a consistent warning. When compute centralized into time-sharing systems, it took a hardware revolution to reverse it. When storage consolidated into proprietary arrays, openness followed only when commodity hardware forced the issue. When networking gravitated toward closed platforms, autonomy returned only through protocol discipline. None of these reversals happened automatically.
They happened because people recognized the window — and acted.
If decentralized intelligence is deferred as a “later concern,” it will reappear as an integration problem rather than an architectural option. If it is treated as optional, it will be outcompeted by convenience. And once inference pipelines are fully centralized, the cost of exiting them will be measured not in engineering effort, but in lost agency.

The window is open, but it will not remain so indefinitely.
10. What Must Emerge Is a Real Network, Not Another Platform
If decentralization is to mean anything in the context of artificial intelligence, it cannot take the form of yet another platform. Platforms centralize by design. They aggregate users, workloads, identity, and governance into a single operational surface. Even when layered on top of decentralized primitives, platforms reintroduce control points where power accumulates.
What must emerge instead is a real network.
A network is not owned. It is not operated as a single product. It does not impose a unified interface or business model. It is composed of independent nodes that can join, leave, fork, and evolve without asking permission. Its coherence comes from protocols and shared constraints, not from centralized orchestration.
For a long time, artificial intelligence seemed incompatible with this model. Models were opaque, training was expensive, and execution was tightly coupled to hyperscale infrastructure. That assumption no longer holds. When intelligence becomes software that can be inspected, modified, and executed locally, the architectural question reopens.
This is where recent open-source releases matter — not as geopolitical signals, but as structural ones. In December 2025, Zhipu AI published GLM-4.7 with open code and weights, making a state-of-the-art language model available for direct execution outside proprietary platforms. At that moment, intelligence ceased to be inseparable from the data center that trained it.
from openai import OpenAI
client = OpenAI(
api_key="your-Z.AI-api-key",
base_url="https://api.z.ai/api/paas/v4/",
)
completion = client.chat.completions.create(
model="glm-4.7",
messages=[
{"role": "system", "content": "You are a smart and creative novelist"},
{
"role": "user",
"content": "Please write a short fairy tale story as a fairy tale master",
},
],
)
print(completion.choices[0].message.content)
This fragment is not remarkable because of what it says, but because of what it implies. Nothing here requires a hyperscale data center. Nothing mandates centralized execution. The same model can run on a workstation, an edge node, or a distributed cluster coordinated through open protocols.
Once intelligence becomes executable in this way, new architectures become viable. Inference can be partitioned. Models can be cached, specialized, or partially replicated. Execution can move closer to where decisions are made. Failure becomes local rather than systemic. Control becomes plural rather than absolute.
This is not a call to replace centralized AI overnight, nor to deny the continued role of large-scale training. It is a call to recognize that execution no longer needs to collapse into a single locus of power. A real network allows multiple forms of intelligence to coexist, compete, and interoperate without requiring universal agreement or centralized governance.
What matters now is not building the next platform on top of AI, but allowing intelligence itself to circulate as part of the network fabric. The difference is subtle, but decisive.
11. Decentralization Will Not Be Proclaimed — It Will Emerge
Decentralization will not arrive through announcements, white papers, or press releases. It will not be granted by institutions, nor delivered as a product. It will emerge — or it will not — through what gets built, deployed, and maintained in practice.
For the next generation of developers, this is not an abstract debate. It is a question of agency. The systems you choose to work on, the architectures you normalize, and the defaults you accept will shape the boundaries of what is possible for decades to come. Code is never neutral. Infrastructure is never accidental.
Centralized intelligence will continue to exist. It is efficient, convenient, and often necessary. The goal is not to eliminate it. The goal is to ensure it is not the only future available. A world where intelligence can only run inside a small number of tightly controlled execution environments is not a technical inevitability — it is a choice, made incrementally, often without reflection.
What makes this moment different is that the tools now exist. Open models, efficient hardware, local inference, and distributed execution are no longer theoretical. They work. They scale. They can be composed into real networks — networks that no single entity owns, controls, or can unilaterally shut down.
But tools alone do nothing.
They require people willing to think beyond platforms. People willing to treat protocols as first-class citizens. People willing to accept friction in exchange for autonomy. People who understand that convenience is often the most effective vector of centralization.
This is not a call for ideological purity. It is a call for responsibility. If you are building intelligent systems today, you are already participating in the definition of future power structures. Whether those structures remain plural, contestable, and resilient depends on decisions that are being made now, quietly, in codebases and deployment pipelines.
Decentralization will not be proclaimed. It will emerge — through thousands of technical decisions, taken by developers who understand that architecture is destiny.
The question is no longer whether another future is possible.
The question is whether enough of you will decide to build it.

If AI is centralized today, it is not a law of nature was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.