How TikTok-Style Feeds Learn What You Want in Minutes
Every day, billions of users scroll through personalized feeds on TikTok, Instagram, and YouTube, each experiencing a uniquely tailored stream of content. Behind this seemingly effortless personalization lies one of the most challenging problems in modern machine learning: how do you build recommendation systems that adapt to user interests in real-time, learning from every interaction within the same scrolling session? The engineering required to make this work, processing billions of events per second, updating models every few hours, and serving recommendations in milliseconds, represents a remarkable achievement that most users never think about. This article pulls back the curtain on how companies like TikTok and Kuaishou, have solved this problem, based on their publicly released research papers.
You’ve probably experienced this: you watch a couple of stand-up comedy clips on TikTok, and suddenly your entire feed is filled with comedians doing crowd work and improv sketches. Within minutes, the app has completely adapted to your newfound interest. This isn’t magic – it’s the result of sophisticated real-time recommendation systems that continuously learn from every swipe, like, and second you spend watching content. In the world of social media and content platforms, responsiveness isn’t just a nice-to-have feature; it’s the difference between an addictive user experience and an app that gets deleted.
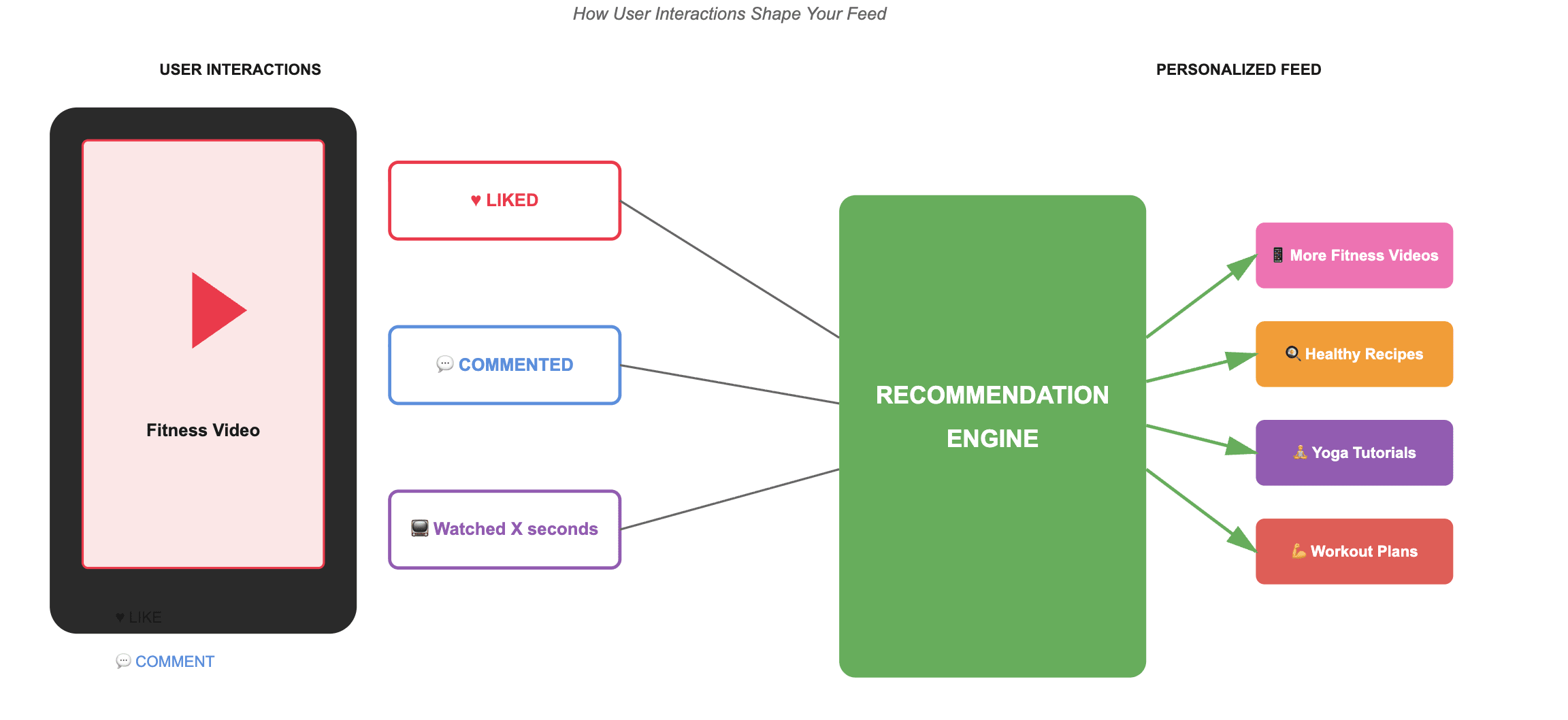
Figure 1: Real Time Recommendation Flow (Credit: Claude AI)
What Does “Responsive” Really Mean?
Before we go further, let’s clarify what we mean by responsiveness in recommendation systems. It’s not about showing you the newest content (though freshness matters too). Responsiveness is about how quickly the ranking system can detect and respond to shifts in your interests based on your engagement patterns.
Think of it this way: Sarah watches two hiking trail videos back-to-back, liking both and watching them all the way through. A responsive system doesn’t wait until tomorrow or even an hour from now – it starts surfacing similar outdoor adventure content in the very next batch of recommendations. Every like, comment, and watch duration feeds immediately back into the system, ensuring the model adapts within her current session rather than learning about her preferences days later.
This matters because user interests exist on multiple timescales. You have long-term interests (your passion for fitness content, your interest in biking routes) and short-term interests (that spontaneous exploration of chocolate cake recipes you’re doing this afternoon). A truly responsive system needs to balance both.
The Challenge: Concept Drift
Here’s a critical problem in machine learning: concept drift. This is the phenomenon where a model’s accuracy degrades over time because user behavior changes, but the model doesn’t. Your interests evolve, trends shift, new content formats emerge, and if your recommendation model is still operating on patterns it learned weeks ago, it’s essentially making predictions based on stale data.
Research from TikTok has shown that updating their models every few hours leads to measurable improvements in relevance – Hours, not days or weeks. This creates an enormous engineering challenge: how do you continuously train and deploy models that are processing billions of user interactions, all while keeping latency low enough that users don’t see loading spinners?
The Architecture of Real-Time Learning
Building a real-time recommendation system requires rethinking the traditional batch-oriented machine learning pipeline. Let’s break down the key components:
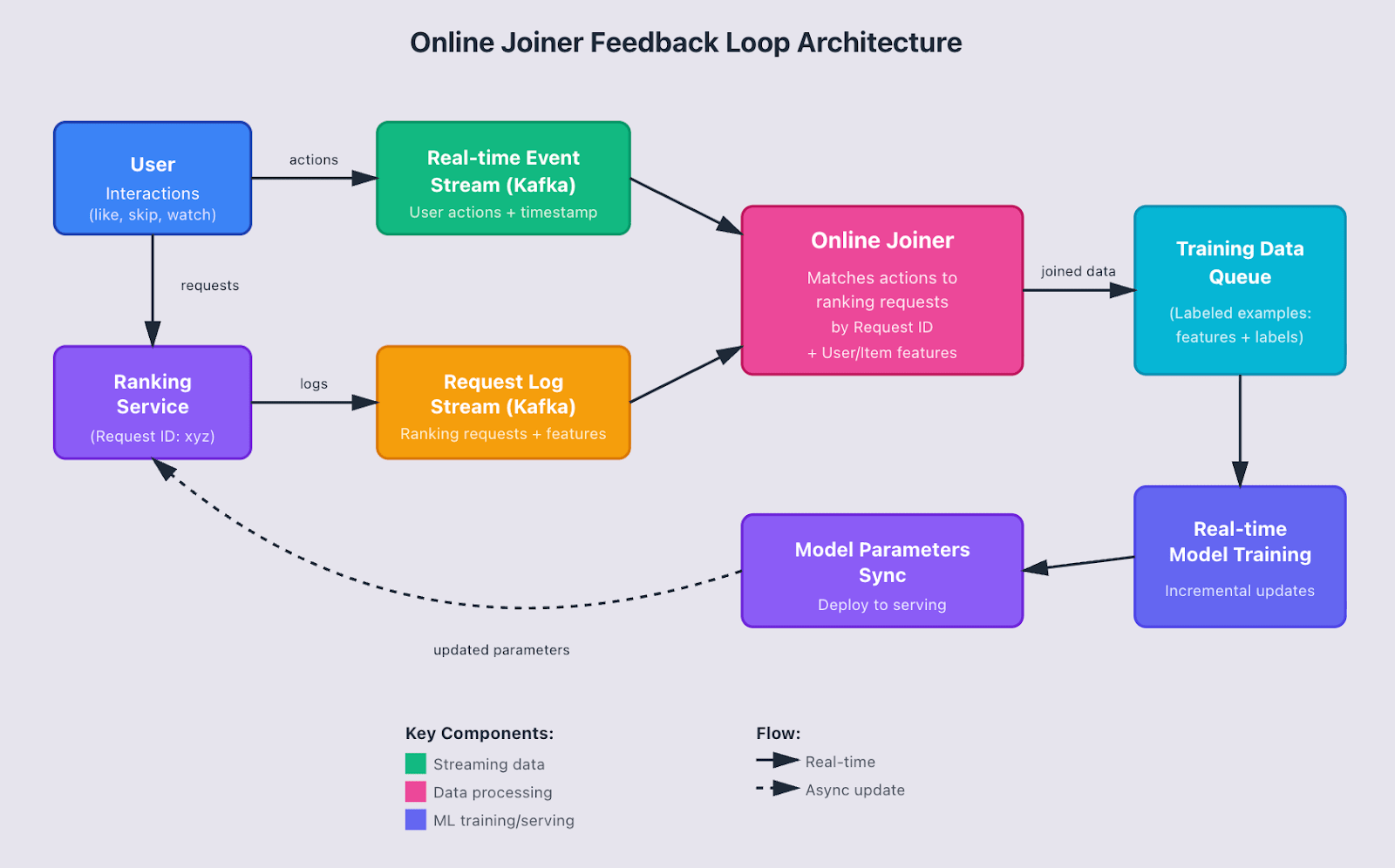
Figure 2: Online Joiner Architecture (Credit: Claude AI)
1. Real-Time Data Collection
The foundation of any responsive system is getting user interaction data flowing in real-time. Every like, comment, watch event needs to be captured and made available through streaming services like Kafka within seconds. This creates a feedback loop where today’s engagement becomes tomorrow’s (or more accurately, the next few minutes’) training data.
But capturing the events is just the first step. You need to join these engagement signals with the original ranking request that generated the recommendations. This is where the “online joiner” comes in – a system that matches user actions to the specific recommendation query that surfaced the content, along with all the relevant user and item features at that moment in time.
2. Training Frequency That Actually Matters
Traditional ML workflows involve training a model, evaluating it offline, and then deploying it. Updates might happen weekly or when you add new features. For real-time recommendations, this is woefully inadequate.
Modern systems use a tiered approach to model training:
Ad-hoc batch training happens when there are major architectural changes or new feature additions. These are cold-start training runs that rebuild the model from scratch using offline data warehouses.
Daily or weekly recurring training uses incremental learning techniques, starting from previous model checkpoints and training on new data that’s accumulated. This is better than ad-hoc updates, but still too slow for true responsiveness.
Real-time training is where models are continuously trained on streaming logs, with each training instance building incrementally from the last checkpoint. This enables the system to learn from user behavior that happened minutes or hours ago, not days.
3. The Embedding Challenge
Here’s where things get technically intricate. Modern recommendation models rely heavily on embeddings – numerical representations of users and items that capture latent patterns in behavior.
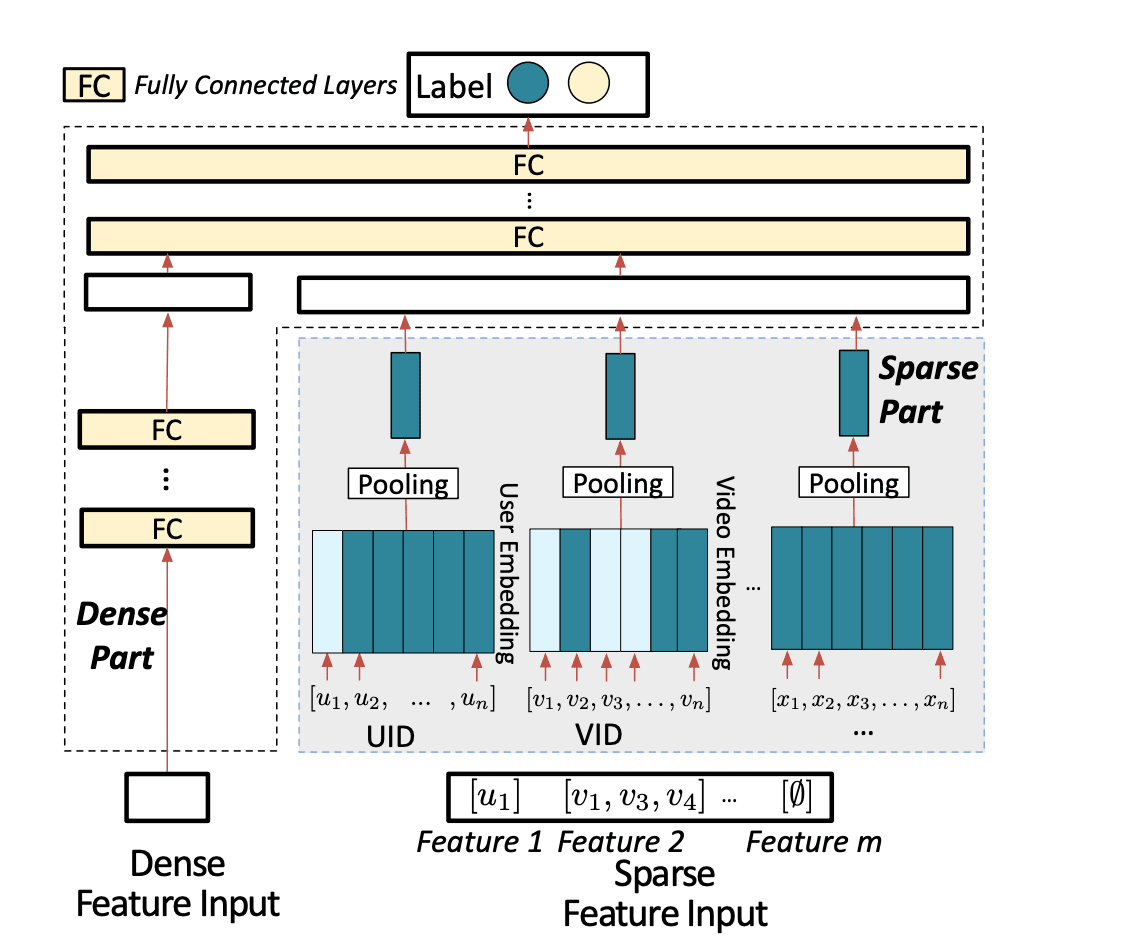
Figure 3: Standard deep neural network architecture for recommendation systems (Credit: Kraken research paper)
Sparse features like “videoIDs a user watched in the last week” get converted into embeddings through hash functions. You might have an embedding table that’s 64 dimensions wide with N rows, where each row represents a unique ID. For features that are lists of IDs, each ID maps to its own 64-dimensional vector, and then an aggregation function (sum, average, or max) combines them into a single representation.
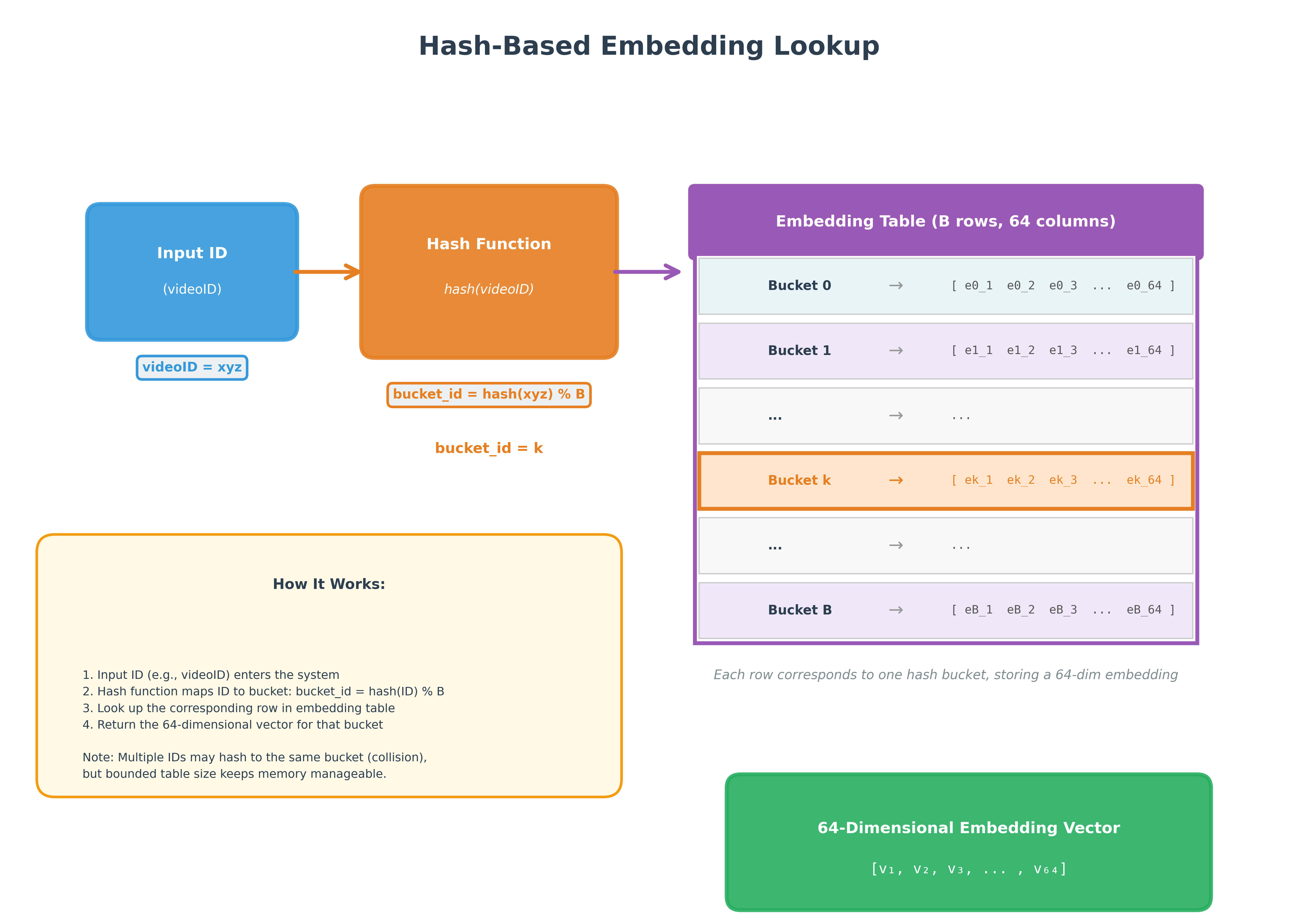
Figure 4: Hash Based Embedding Lookup (Credit: Claude AI)
The challenge? These embedding tables can grow massive. To keep them bounded, hash functions map multiple IDs to the same location, but this creates collisions. The more collisions you have, the worse your model quality becomes because you’re losing the distinct representation of different items.
For real-time systems, there’s an additional wrinkle: you typically cache precomputed embeddings to reduce latency during ranking. But for true responsiveness, you need to reduce the cache time-to-live (TTL) and more frequently compute fresh embeddings based on the user’s most recent actions.
The Deployment Puzzle
A critical question emerges: how do you continuously deploy new model versions while keeping your production system running with minimal latency?
TikTok’s monolithic architecture addresses this through careful parameter synchronization. The challenge is that your current production model needs to coexist with the new version being trained on the latest data, all while serving recommendations in milliseconds.
There are several clever techniques that can be used:
Selective embedding updates: Between parameter syncs, only a small fraction of users and videos actually have new engagement. This keeps table sizes manageable and reduces hash collisions. An important consideration here is the difference in how dense and sparse parameters learn: dense parameters receive gradient updates at every training step, and when processing billions of data points, momentum-based optimizers accumulate significant velocity terms that dampen parameter updates and slow convergence. Sparse embedding parameters, however, only update when their specific IDs appear in a training batch, meaning they accumulate momentum far less frequently and receive larger effective learning rates per update. Managing this asymmetry is crucial for efficient training. To address this, systems use less frequent synchronization schedules for dense parameters while updating only the sparse embeddings that have changed between syncs and evicting unused sparse embeddings to keep memory footprint manageable.
Model parallelism: Following approaches from Kuaishou’s research, sparse embeddings can be sharded across multiple servers while dense embeddings are replicated. This distributes the memory and compute burden.
Quantization: Making models smaller through reduced-precision representations helps minimize memory footprint without sacrificing too much accuracy.
The Latency Arms Race
Even the smartest model in the world is useless if it takes 10 seconds to load recommendations. Users will simply scroll away to a competitor. This creates a fascinating set of engineering tradeoffs:
Pagination allows servers to rank and send a batch of results, then issue the next ranking request only when users approach the end of their current feed. The page size becomes a tuning parameter balancing latency against responsiveness.
On-device models are an emerging approach where lightweight ranking models run directly on mobile devices, re-ranking results based on immediate client-side interactions. Kuaishou’s research has shown this can eliminate client-server communication delays and enable real-time responsiveness to user feedback.”
Caching to achieve sub-100ms inference latency at scale. Inference servers cache frequently accessed model parameters in memory while relegating less-accessed data to disk storage, enabling systems to handle large QPS while maintaining low tail latency even during peak traffic periods in production deployments.
The Bottom Line
Building responsive recommendation systems is one of the most complex engineering challenges in modern tech. It requires rethinking traditional ML pipelines to operate in real-time, managing massive embedding tables that continuously grow and evolve, synchronizing model parameters across distributed systems, and doing all of this while maintaining the sub-second latency that users expect.
“The apps that get this right create experiences that feel almost eerily personalized, while users naturally gravitate toward platforms that better understand their evolving interests.”
As these systems continue to evolve, we’re seeing the emergence of techniques that would have seemed impossible just a few years ago: models that update every few hours, on-device ranking that eliminates server latency, and sophisticated embedding management that keeps memory footprint reasonable even as user bases grow into the billions.
Thanks for reading! Feel free to reach out on LinkedIn with any feedback or questions.
Disclaimer: The views expressed in this article are solely my own and are not affiliated with my employer in any way. In writing this, I have not utilized any proprietary or confidential information.