
How Palo Alto Networks enhanced device security infra log analysis with Amazon Bedrock
This post is co-written by Fan Zhang, Sr Principal Engineer / Architect from Palo Alto Networks.
Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. The primary challenge they faced was that reactively processing over 200 million daily service and application log entries resulted in delayed response times to these critical issues, leaving them at risk for potential service degradation.
To address this challenge, they partnered with the AWS Generative AI Innovation Center (GenAIIC) to develop an automated log classification pipeline powered by Amazon Bedrock. The solution achieved 95% precision in detecting production issues while reducing incident response times by 83%.
In this post, we explore how to build a scalable and cost-effective log analysis system using Amazon Bedrock to transform reactive log monitoring into proactive issue detection. We discuss how Amazon Bedrock, through Anthropic’ s Claude Haiku model, and Amazon Titan Text Embeddings work together to automatically classify and analyze log data. We explore how this automated pipeline detects critical issues, examine the solution architecture, and share implementation insights that have delivered measurable operational improvements.
Palo Alto Networks offers Cloud-Delivered Security Services (CDSS) to tackle device security risks. Their solution uses machine learning and automated discovery to provide visibility into connected devices, enforcing Zero Trust principles. Teams facing similar log analysis challenges can find practical insights in this implementation.
Solution overview
Palo Alto Networks’ automated log classification system helps their Device Security team detect and respond to potential service failures ahead of time. The solution processes over 200 million service and application logs daily, automatically identifying critical issues before they escalate into service outages that impact customers.
The system uses Amazon Bedrock with Anthropic’s Claude Haiku model to understand log patterns and classify severity levels, and Amazon Titan Text Embeddings enables intelligent similarity matching. Amazon Aurora provides a caching layer that makes processing massive log volumes feasible in real time. The solution integrates seamlessly with Palo Alto Networks’ existing infrastructure, helping the Device Security team focus on preventing outages instead of managing complex log analysis processes.
Palo Alto Networks and the AWS GenAIIC collaborated to build a solution with the following capabilities:
- Intelligent deduplication and caching – The system scales by intelligently identifying duplicate log entries for the same code event. Rather than using a large language model (LLM) to classify every log individually, the system first identifies duplicates through exact matching, then uses overlap similarity, and finally employs semantic similarity only if no earlier match is found. This approach cost-effectively reduces the 200 million daily logs by over 99%, to logs only representing unique events. The caching layer enables real-time processing by reducing the need for redundant LLM invocations.
- Context retrieval for unique logs – For unique logs, Anthropic’s Claude Haiku model using Amazon Bedrock classifies each log’s severity. The model processes the incoming log along with relevant labeled historical examples. The examples are dynamically retrieved at inference time through vector similarity search. Over time, labeled examples are added to provide rich context to the LLM for classification. This context-aware approach improves accuracy for Palo Alto Networks’ internal logs and systems and evolving log patterns that traditional rule-based systems struggle to handle.
- Classification with Amazon Bedrock – The solution provides structured predictions, including severity classification (Priority 1 (P1), Priority 2 (P2), Priority 3 (P3)) and detailed reasoning for each decision. This comprehensive output helps Palo Alto Networks’ SMEs quickly prioritize responses and take preventive action before potential outages occur.
- Integration with existing pipelines for action – Results integrate with their existing FluentD and Kafka pipeline, with data flowing to Amazon Simple Storage Service (Amazon S3) and Amazon Redshift for further analysis and reporting.
The following diagram (Figure 1) illustrates how the three-stage pipeline processes Palo Alto Networks’ 200 million daily log volume while balancing scale, accuracy, and cost-efficiency. The architecture consists of the following key components:
- Data ingestion layer – FluentD and Kafka pipeline and incoming logs
- Processing pipeline – Consisting of the following stages:
- Stage 1: Smart caching and deduplication – Aurora for exact matching and Amazon Titan Text Embeddings for semantic matching
- Stage 2: Context retrieval – Amazon Titan Text Embeddings to enable historical labeled examples, and vector similarity search
- Stage 3: Classification – Anthropic’s Claude Haiku model for severity classification (P1/P2/P3)
- Output layer – Aurora, Amazon S3, Amazon Redshift, and SME review interface
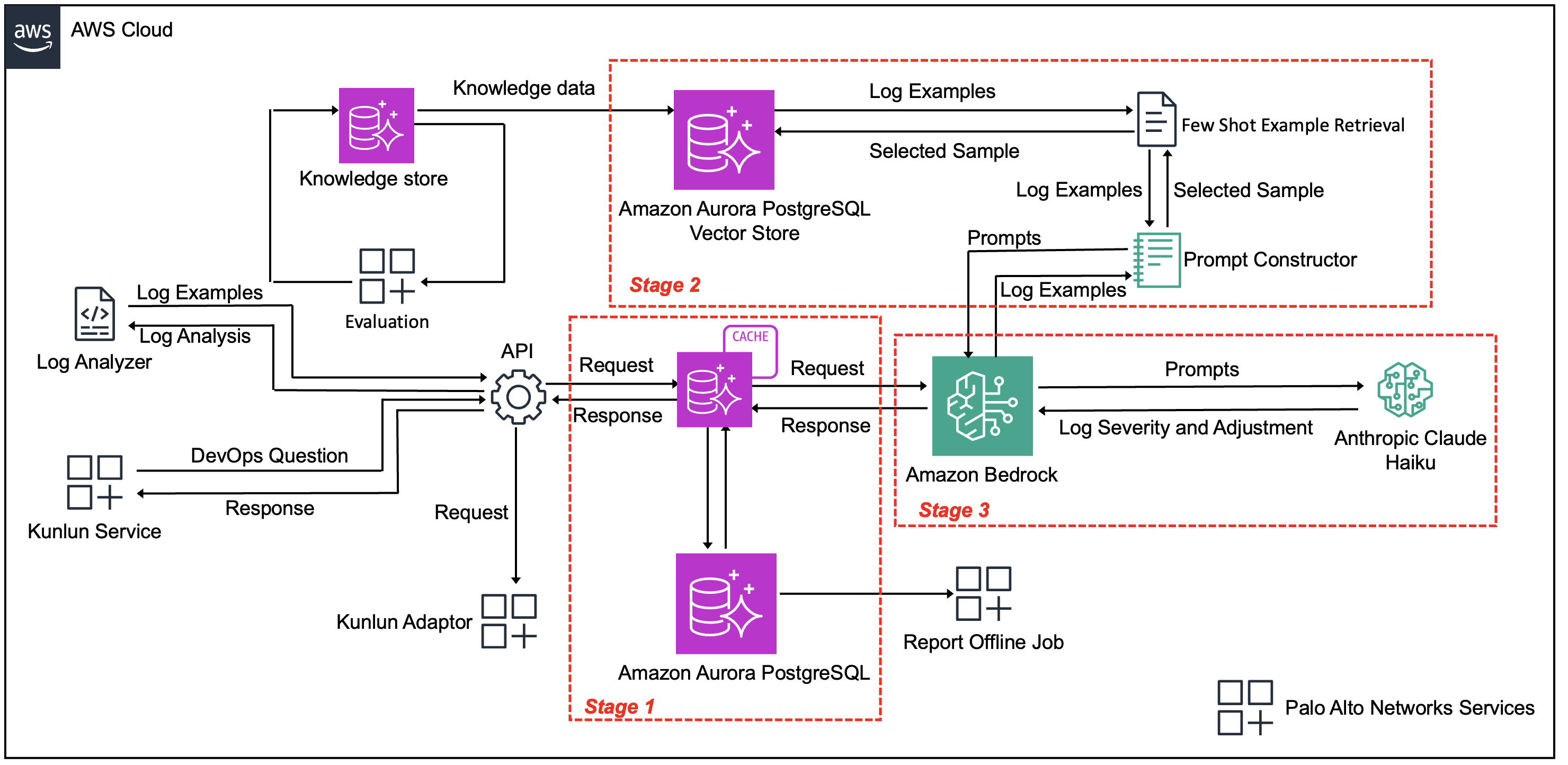
Figure 1: Automated log classification system architecture
The processing workflow moves through the following stages:
- Stage 1: Smart caching and deduplication – Incoming logs from Palo Alto Networks’ FluentD and Kafka pipeline are immediately processed through an Aurora based caching layer. The system first applies exact matching, then falls back to overlap similarity, and finally uses semantic similarity through Amazon Titan Text Embeddings if no earlier match is found. During testing, this approach identified that more than 99% of logs corresponded to duplicate events, although they contained different time stamps, log levels, and phrasing. The caching system reduced response times for cached results and reduced unnecessary LLM processing.
- Stage 2: Context retrieval for unique logs – The remaining less than 1% of truly unique logs require classification. For these entries, the system uses Amazon Titan Text Embeddings to identify the most relevant historical examples from Palo Alto Networks’ labeled dataset. Rather than using static examples, this dynamic retrieval makes sure each log receives contextually appropriate guidance for classification.
- Stage 3: Classification with Amazon Bedrock – Unique logs and their selected examples are processed by Amazon Bedrock using Anthropic’s Claude Haiku model. The model analyzes the log content alongside relevant historical examples to produce severity classifications (P1, P2, P3) and detailed explanations. Results are stored in Aurora and the cache and integrated into Palo Alto Networks’ existing data pipeline for SME review and action.
This architecture enables cost-effective processing of massive log volumes while maintaining 95% precision for critical P1 severity detection. The system uses carefully crafted prompts that combine domain expertise with dynamically selected examples:
system_prompt = """
<Task>
You are an expert log analysis system responsible for classifying production system logs based on severity. Your analysis helps engineering teams prioritize their response to system issues and maintain service reliability.
</Task>
<Severity_Definitions>
P1 (Critical): Requires immediate action - system-wide outages, repeated application crashes
P2 (High): Warrants attention during business hours - performance issues, partial service disruption
P3 (Low): Can be addressed when resources available - minor bugs, authorization failures, intermittent network issues
</Severity_Definitions>
<Examples>
<log_snippet>
2024-08-17 01:15:00.00 [warn] failed (104: Connection reset by peer) while reading response header from upstream
</log_snippet>
severity: P3
category: Category A
<log_snippet>
2024-08-18 17:40:00.00 <warn> Error: Request failed with status code 500 at settle
</log_snippet>
severity: P2
category: Category B
</Examples>
<Target_Log>
Log: {incoming_log_snippet}
Location: {system_location}
</Target_Log>"""
Provide severity classification (P1/P2/P3) and detailed reasoning.Implementation insights
The core value of Palo Alto Networks’ solution lies in making an insurmountable challenge manageable: AI helps their team analyze 200 million of daily volumes efficiently, while the system’s dynamic adaptability makes it possible to extend the solution into the future by adding more labeled examples. Palo Alto Networks’ successful implementation of their automated log classification system yielded key insights that can help organizations building production-scale AI solutions:
- Continuous learning systems deliver compounding value – Palo Alto Networks designed their system to improve automatically as SMEs validate classifications and label new examples. Each validated classification becomes part of the dynamic few-shot retrieval dataset, improving accuracy for similar future logs while increasing cache hit rates. This approach creates a cycle where operational use enhances system performance and reduces costs.
- Intelligent caching enables AI at production scale – The multi-layered caching architecture processes more than 99% of logs through cache hits, transforming expensive per-log LLM operations into a cost-effective system capable of handling 200 million daily volumes. This foundation makes AI processing economically viable at enterprise scale while maintaining response times.
- Adaptive systems handle evolving requirements without code changes – The solution accommodates new log categories and patterns without requiring system modifications. When performance needs improvement for novel log types, SMEs can label additional examples, and the dynamic few-shot retrieval automatically incorporates this knowledge into future classifications. This adaptability allows the system to scale with business needs.
- Explainable classifications drive operational confidence – SMEs responding to critical alerts require confidence in AI recommendations, particularly for P1 severity classifications. By providing detailed reasoning alongside each classification, Palo Alto Networks enables SMEs to quickly validate decisions and take appropriate action. Clear explanations transform AI outputs from predictions into actionable intelligence.
These insights demonstrate how AI systems designed for continuous learning and explainability become increasingly valuable operational assets.
Conclusion
Palo Alto Networks’ automated log classification system demonstrates how generative AI powered by AWS helps operational teams manage vast volumes in real time. In this post, we explored how an architecture combining Amazon Bedrock, Amazon Titan Text Embeddings, and Aurora processes 200 million of daily logs through intelligent caching and dynamic few-shot learning, enabling proactive detection of critical issues with 95% precision. Palo Alto Networks’ automated log classification system delivered concrete operational improvements:
- 95% precision, 90% recall for P1 severity logs – Critical alerts are accurate and actionable, minimizing false alarms while catching 9 out of 10 urgent issues, leaving the remaining alerts to be captured by existing monitoring systems
- 83% reduction in debugging time – SMEs spend less time on routine log analysis and more time on strategic improvements
- Over 99% cache hit rate – The intelligent caching layer processes 20 million daily volume cost-effectively through subsecond responses
- Proactive issue detection – The system identifies potential problems before they impact customers, preventing the multi-week outages that previously disrupted service
- Continuous improvement – Each SME validation automatically improves future classifications and increases cache efficiency, resulting in reduced costs
For organizations evaluating AI initiatives for log analysis and operational monitoring, Palo Alto Networks’ implementation offers a blueprint for building production-scale systems that deliver measurable improvements in operational efficiency and cost reduction. To build your own generative AI solutions, explore Amazon Bedrock for managed access to foundation models. For additional guidance, check out the AWS Machine Learning resources and browse implementation examples in the AWS Artificial Intelligence Blog.
The collaboration between Palo Alto Networks and the AWS GenAIIC demonstrates how thoughtful AI implementation can transform reactive operations into proactive, scalable systems that deliver sustained business value.
To get started with Amazon Bedrock, see Build generative AI solutions with Amazon Bedrock.
About the authors

Rizwan Mushtaq
Rizwan is a Principal Solutions Architect at AWS. He helps customers design innovative, resilient, and cost-effective solutions using AWS services. He holds an MS in Electrical Engineering from Wichita State University.

Hector Lopez
Hector Lopez, PhD is an Applied Scientist in AWS’s Generative AI Innovation Center, where he specializes in delivering production-ready generative AI solutions and proof-of-concepts across diverse industry applications. His expertise spans traditional machine learning and data science in life and physical sciences. Hector implements a first-principles approach to customer solutions, working backwards from core business needs to help organizations understand and leverage generative AI tools for meaningful business transformation.

Meena Menon
Meena Menon is a Sr. Customer Success Manager at AWS with over 20 years of experience delivering enterprise customer outcomes and digital transformation. At AWS, she partners with strategic ISVs including Palo Alto Networks, Proofpoint, New Relic, and Splunk to accelerate cloud modernization and migrations.

Fan Zhang
Fan is a Senior Principal Engineer/Architect at Palo Alto Networks, leading the IoT Security team’s infrastructure and data pipeline, as well as its generative AI infrastructure.