How I Built a Real-Time Traffic Accident Detector Running at 100+ FPS (And Improved Recall by +4)
Balancing real-time edge performance with safety-critical sensitivity using Foundation Models and Knowledge Distillation.

If you’ve ever tried building a perception system for a self-driving car or a smart city grid, you know the harsh reality: the real world is chaotic. It doesn’t care about your clean, curated training dataset.
As machine learning engineers, we spend weeks training models to recognize standard traffic patterns. But what happens when the camera captures a sudden, chaotic anomaly? A high-speed collision, a car skidding off the road, or a multi-vehicle pileup?
In autonomous systems, traffic accident detection requires a delicate — and often frustrating — balance. On one hand, you need real-time performance (running at >100 FPS on edge devices). On the other hand, you need safety-critical sensitivity (a model that doesn’t miss a crash).
Usually, you have to pick one. Today, I’m going to show you how to get both.
In this article, I will break down how I built the Semantic-Anomaly-Distillation project: a Joint Semantic Distillation (JSD) framework that transfers the robust world knowledge of a massive Foundation Model into a tiny, edge-ready neural network, resulting in a 3× improvement in accident detection recall.
The Edge AI Dilemma: Fast but Blind
When tasked with detecting traffic anomalies on edge devices, most developers immediately reach for lightweight architectures like MobileNet.
The logic makes sense. Edge devices have strict computational limits, and you need the system to process video feeds instantly. So, you train a standard MobileNetV3-Small model on a dataset using standard Binary Cross-Entropy (BCE) loss.
But when you deploy it into the real world, you hit a massive wall: The “Normal” Bias.
Traffic datasets are inherently imbalanced. 99% of driving is perfectly normal, and accidents are incredibly rare, split-second events characterized by motion blur, severe occlusions, and unpredictable dynamics. Because the lightweight model lacks deep semantic understanding, it takes the easy way out: it becomes heavily biased toward predicting “Normal” for almost everything.
It runs fast, but it misses the crashes. In safety-critical systems, missing an accident (a False Negative) is catastrophic.
The Paradigm Shift: Joint Semantic Distillation (JSD)
To fix this, we need the deep, rich semantic understanding of a massive Foundation Model, but we need it to run at the speed of MobileNet. This is where Knowledge Distillation comes in.

Instead of training our lightweight model from scratch, we pair it with an incredibly powerful, pre-trained Teacher model. For this project, I chose DINOv2 (ViT-Base). DINOv2 has seen the world; it understands complex spatial relationships, lighting changes, and object interactions at a profound level.
Here is how the Joint Semantic Distillation (JSD) framework operates:
- The Frozen Teacher (DINOv2): We pass our traffic frames through DINOv2. Crucially, its weights are strictly frozen. It acts purely as a master feature extractor, generating rich semantic representations of the scene.
- The Lightweight Student (MobileNetV3-Small): This is our edge-deployable model. It processes the same frames, but it is actively learning.
- The Joint Optimization: Instead of just penalizing the student for wrong classifications, we force its deep internal features to mimic the Teacher’s features.
We jointly optimize the network using two loss functions:
- Binary Classification Loss (L_BCE): To ensure it learns the core task (Accident vs. Normal).
- Semantic Feature Alignment Loss (L_Cos): We use Cosine Similarity loss to force the MobileNetV3 feature maps to align mathematically with the DINOv2 feature maps.
By doing this, the tiny Student model inherits the robust “world knowledge” of the massive Teacher model without adding a single millisecond of latency during inference.
The Results: Shifting the Decision Boundary
To prove this architecture works, I evaluated the framework on the DoTA (Detection of Traffic Anomaly) dataset, utilizing 142,000 test frames packed with highly challenging scenarios like night-time driving and extreme motion blur.

Quantitative Metrics: A +4 Leap in Recall
The results fundamentally proved the power of distillation. By forcing the student to align with DINOv2’s features, we shifted the decision boundary to heavily prioritize safety.
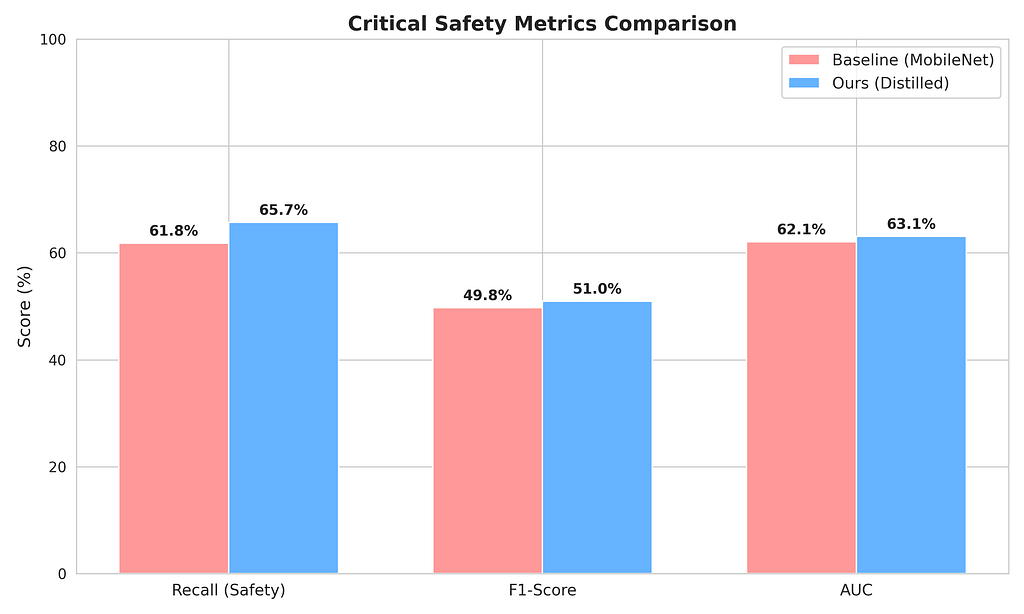
While the raw accuracy dropped slightly (a common trade-off when combating extreme class imbalance), the Recall increased from 61.8% to 65.7%. The distilled model became vastly more sensitive to actual accidents, achieving an F1-Score of 0.510 compared to the baseline’s 0.498. These differences might not look like a big achievement; however, they are very important when the application is safety-critical.
Confusion Matrix Analysis
When we look at the confusion matrices, the story becomes even clearer.

The standard baseline model (left) was severely biased. It predicted “Normal” for almost everything, successfully identifying only a fraction of the actual crashes. Our Distilled Model (right) broke free from that bias, successfully identifying the vast majority of crash events.
Qualitative Success
Beyond the numbers, the distilled model succeeded in the real world where the baseline failed. Because it absorbed DINOv2’s semantic understanding, it successfully detected accidents hidden by severe motion blur and vehicle occlusion.

And the best part? Because we only deploy the MobileNetV3 Student model during inference, the entire system runs at >100 FPS on edge devices.
Why You Should Care
As AI continues to integrate into smart cities and autonomous vehicles, we cannot afford systems that compromise safety for speed.
If your perception pipeline relies on training lightweight models from scratch, you are leaving massive performance gains on the table. Joint Semantic Distillation proves that we can successfully bridge the gap between the heavy, state-of-the-art Foundation Models (like DINOv2) and the strict hardware limits of edge computing.
Try It Yourself
I’ve open-sourced the complete architecture, distillation training loops, and real-time inference scripts. You can clone the repo, run the demo, and see the >100 FPS detection for yourself.
🔗 (https://github.com/Alpsource/Semantic-Anomaly-Distillation)
If you found this deep dive into semantic distillation helpful, please consider starring the repository ⭐! It helps support open-source computer vision research and lets me know what kind of architectures the community wants to see next.
Did you know you can clap up to 50 times on a Medium article? If this saved you time or gave you a new perspective on building edge-ready CV pipelines, hold down that clap button to help push this to the top 1% of computer vision stories, and let’s connect in the comments!
How I Built a Real-Time Traffic Accident Detector Running at 100+ FPS (And Improved Recall by +4) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.