
How Google Solves the AI Problem Everybody Forgets
The internet is facing a crisis of authenticity

Have you read an article today?
Are you sure a human wrote it?
Now that generative AI tools are available to everyone, it is hard to distinguish between what people create and what algorithms produce.
The internet is quickly shifting from being made by people to being run by machines, making it harder than ever to know what is true.
In this blog post, I will explain the problem in more detail and how Google addresses it.
The AI Problems
Generative AI has common flaws that are widely known today, such as hallucinations and bias.
While most people are familiar with common AI flaws, such as hallucination and bias, new challenges are emerging as AI-generated content saturates our digital world.
The first hurdle is AI slope, which refers to cheap, mass-produced, and often unverified AI-generated content.
It is estimated that we have already reached the point where more AI content is produced than human content.
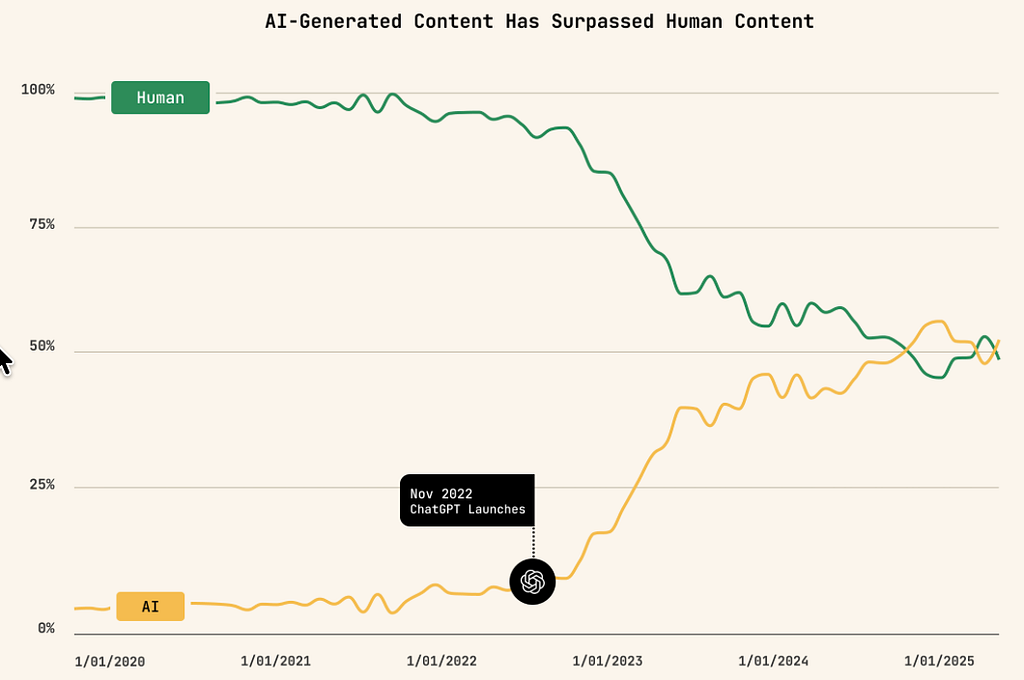
This AI slop causes three problems.
The first issue is with the platforms themselves.
Social media and search engines are now filled with low-quality AI content created to earn ad revenue, boost engagement, or improve SEO rankings.
As low-quality AI content becomes more prevalent than high-quality human content, users place less value on these platforms.
It is increasingly difficult to find reliable and useful information.
Finally, there is the problem of the AI-generated feedback loop.
If AI models begin learning from their own outputs rather than the original human data, the system becomes a closed loop.
When AI is trained on AI, the results begin to degrade, which results in a model collapse, a digital version of inbreeding depression.
The Habsburg dynasty offers a lesson from history.
Generations of close-kin marriages reduced genetic diversity, leading to the accumulation of harmful traits and the eventual decline of the lineage.
This example shows why diversity, whether in genes or information, is important for health and progress.

With generative AI creating more content every second around the world, as shown in the Data Never Sleeps Report AI Edition in 2025, we need an automated way to tell if an image was made by AI.
However, traditional approaches, such as watermarking or additional metadata, are not robust enough to withstand editing, modification, or screenshot capture.

We need a machine-readable watermark so the computer can automatically distinguish between AI-generated and non-AI-generated outcomes, and Google provides this with SynthID.
The solution to the problems
SnythID is the invisible ink of the AI age.
It is a single that survives editing without ruining the content experience, detectable only by machines.
Snyth ID for Images
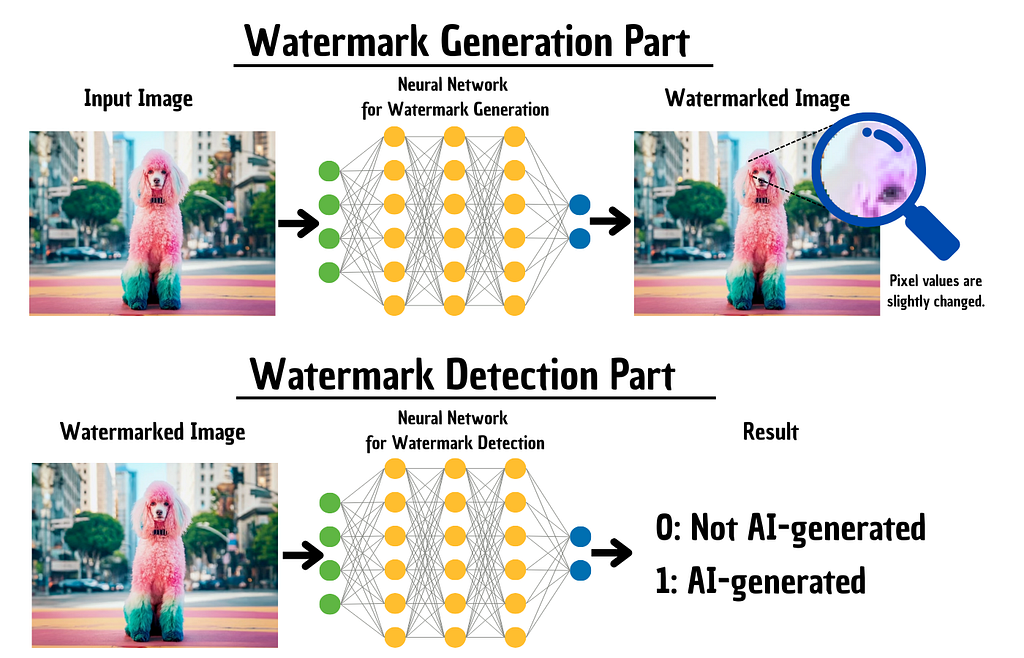
SnythID is based on two deep learning models.
The encoder neural network subtly manipulates pixel colours. The changes are so small that the human eye cannot detect them. The generated piece of content looks exactly the same as without SynthID.
The decoder neural network is trained to detect these small pixel shifts.
Embedding the changes directly in the pixels makes the watermark robust to cropping or image filtering [5].
Synth ID for Videos
A video is composed of a series of images, and SynthID handles it accordingly.
It processes each frame independently, just as it does with images.
Even if you cut, edit, or rearrange scenes, the watermark remains [5].
Synth ID for Audio
Audio watermarking combines physics and coding in an interesting way.
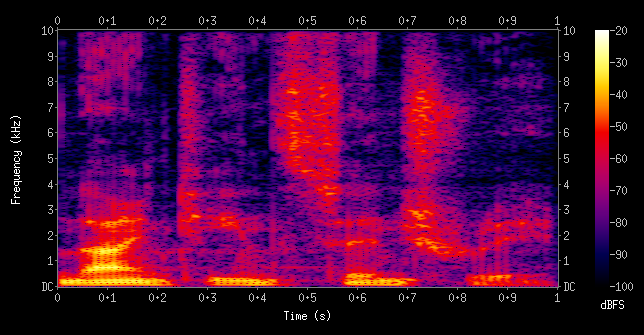
SynthID uses a spectrogram to embed a signal in audio so it cannot be heard.
A spectrogram is a visual map of sound.
The X-axis of a spectrogram shows time, from start to finish.
The Y-axis shows frequency, with low bass at the bottom and high treble at the top.
{kind=link}
Colour represents intensity. Yellow or red indicates loud or high-energy sound, while dark areas indicate silence.
SynthID embeds the watermark directly into this visual representation of the sound wave, then converts it back into audio [5].

However, while it works well with MP3 compression, it struggles with advanced editing such as pitch shifting, time stretching, or heavy compression [5].
Synth ID for Text
Text is the hardest format to work with.
You can’t change a letter in a word without changing how it’s spelt.
So, SynthID works by adjusting probability instead.
Large Language Models create text by predicting the next “token,” which is a word or part of a word, based on how likely it is to come next.
This is where SynthID steps in.
SynthID gently adjusts the probability scores for possible next words in a pseudorandom pattern.

The text remains clear and retains its original meaning.
However, if a detection tool analyses the text, it will identify this unusual statistical pattern.
This method works when you make only small edits to the audio.
However, if you translate or rewrite the text a lot, the watermark and its pattern will be lost [7].
Implementation
Google shared an open-source solution for Text SynthID, enabling developers to integrate it into their projects.
However, it is important to note that this version of SynthID is not as robust as the one Google has deeply integrated into its own models.
For audio, images, and videos, there is no open-source version yet.
If you want to check whether an image, text, or audio file was made by a Google model, you can join the waiting list for the Google SynthID checker [6].
This tool can review all file types [7].
Limitations
SynthID is a big step forward, but it also has its limits.
Here are some important drawbacks for users and developers to consider.
The “Black Box” Problem
Like other AI detection tools, SynthID shows you a result but does not explain its reasoning. It does not explain why it flagged an image, making its decisions hard to understand or challenge.
No Metrics for Non-Text
Currently, there are no publicly available accuracy metrics showing how well SynthID performs on images, audio, or video.
Limited Scope
SynthID only works with content created by models that use SynthID, like Google’s Gemini. It cannot detect AI-generated content from other models.
Final Thoughts
AI didn’t just add more content to the internet.
It changed the economics of content.
Now that anyone can create endless amounts of “good-enough” text, images, and audio for almost no cost, the web is becoming more crowded with content designed for clicks, rankings, and speed rather than truth.
This could lead to an authenticity crisis.
The signal stays the same, but the noise approaches infinity.
SythID is one attempt to fight this problem.
Invisible, robust, and machine-detectable is exactly the kind of design we need if we want platforms to automatically sort content by origin.
But invisible watermarks only become a real success story if they’re standardised.
If every AI company ships its own incompatible watermark, we don’t get clarity.
Thus, the next step after SynthID isn’t just better watermarks.
It also includes shared standards that make origin verifiable everywhere.
P.S.: If you’ve read this far, I hope you’ve gained some value from this article. If you would like to learn more about AI, I would greatly appreciate your support of this project by subscribing or providing feedback to generate more valuable posts about AI for people interested in this recent technological advancement.
Follow & Connect
📝 Substack: https://felixpappe.substack.com/
✍️ Medium: felix-pappe.medium.com/subscribe
💼 LinkedIn: www.linkedin.com/in/felix-pappe
Sources
[1] More Articles Are Now Created by AI Than Humans https://graphite.io/five-percent/more-articles-are-now-created-by-ai-than-humans
https://www.domo.com/de/learn/infographic/data-never-sleeps-ai-edition-2025
[5] More Articles Are Now Created by AI Than Humans https://graphite.io/five-percent/more-articles-are-now-created-by-ai-than-humans
[3] Habsburger Problem https://katzlberger.ai/2024/09/16/modellkollaps-wenn-ki-mit-ki-generierten-daten-trainiert-wird/
[4] Karl II. https://de.wikipedia.org/wiki/Karl_II._(Spanien)
[5] Google’s SynthID: A Guide With Examples
https://www.datacamp.com/tutorial/synthid
[6] SynthID Detector — a new portal to help identify AI-generated content https://blog.google/innovation-and-ai/products/google-synthid-ai-content-detector/
[7] SynthID: Tools for watermarking and detecting LLM-generated Text
https://ai.google.dev/responsible/docs/safeguards/synthid
How Google Solves the AI Problem Everybody Forgets was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.