
Gated Attention & DeltaNets: The Missing Link for Long-Context AI
Paper-explained Series 6

Transformers didn’t take over AI because they were perfect — they took over because they were parallelizable. Attention let models look everywhere at once, unlocking massive scale. But as models grew deeper and wider, a strange pattern emerged: attention wasn’t failing to look, it was failing to decide when to change.
- Loss Spikes: Sudden, destabilizing jumps in training error often caused by massive activations in the residual stream, which limit how fast a model can learn.
- Attention Sinks: A phenomenon where models dump excess attention probability on the first token just to satisfy the Softmax requirement (summing to 1), creating a useless “trash can” for probability mass.
- Brittle Long-Context Behavior: The tendency for models to fail or degrade when processing sequences longer than their training limit, often because noise and attention artifacts accumulate over time.
These weren’t bugs in softmax or dot products. They were symptoms of something more subtle: Transformers always apply their updates, even when they shouldn’t.
The paper “Gated Attention for Large Language Models” makes a deceptively simple but profound move. It reframes attention outputs as Δ (Delta) — proposed changes to the model’s internal state — and introduces gating as a way to decide whether those changes should be applied at all.
This article tells that story properly:
- First, we explain gating in full detail — every tested position, multi-head behavior, MoE handling, and design choice.
- Then, we explain Delta with the same rigor.
- Finally, we connect them into a single, coherent mental model that explains why this works — and why it scales.
What is Gating?
At its core, gating is the neural network equivalent of a faucet handle. Attention proposes an update; the gate decides how much of that update is allowed through. Mathematically, it is almost always an element-wise multiplication between the signal and a “gate score” (usually between 0 and 1).
- If the gate score is 1, the faucet is fully open; the information flows unchanged.
- If the gate score is 0, the faucet is closed; the information is erased (multiplied by zero) before it can reach the next layer.
This simple mechanism gives the model a superpower: Input-Dependent Sparsity. It allows the model to look at the data and say, “This specific part is noise. I am going to shut it off right now.”
Now, let’s look at how two different research teams applied this concept to fix the biggest problems in modern AI.
Part 1: Gated Attention for Transformers
Paper: Gated Attention for Large Language Models
Standard Transformers use Softmax Attention, which forces attention scores to sum to 1.0. This means the model must attend to something, even if the input is garbage. This creates “attention sinks” — useless tokens (like the first token) that hoard attention probability.
1. The Math: How It Is Calculated
The gating mechanism at G1 is calculated as:
Y′=Y⊙σ(XWθ)
- Y: The output of the Scaled Dot-Product Attention.
- X: The input hidden states (specifically, the states after pre-normalization).
- Wθ: A learnable weight matrix.
- σ: The activation function (Sigmoid).
- ⊙: Element-wise multiplication.
This effectively acts as a dynamic filter. If σ(XWθ) outputs close to 0, the information from Y is erased.
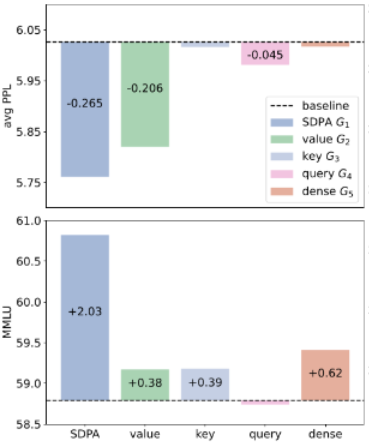
2. The Architecture Search: Where Does the Gate Go?
The researchers didn’t just guess. They conducted a massive ablation study involving over 30 variants of 15B parameter Mixture-of-Experts (MoE) models and 1.7B dense models. They tested gating at five distinct positions:

- G1 (SDPA Output): Applied immediately after the Scaled Dot-Product Attention output.
- G2 (Value Output): Applied after the Value (V) projection but before attention.
- G3 (Key Output): Applied after the Key (K) projection.
- G4 (Query Output): Applied after the Query (Q) projection.
- G5 (Final Output): Applied after the final dense projection (Wo).
The Verdict: The SDPA Output Gate (G1) was the definitive winner.
- It yielded the most significant performance improvements (e.g., 2 points on MMLU).
- Gating at the Value layer (G2) helped, particularly with perplexity, but was inferior to G1.
- Gating at the dense output (G5) had almost no effect because it failed to add non-linearity between the value and output projections.
3. The Arithmetic of Control: Multiplicative vs. Additive
One of the most critical design choices was how to apply the gate. The researchers compared two fundamental operations:
- Multiplicative Gating: Y′=Y⋅σ(Xθ)
- Additive Gating: Y′=Y+σ(Xθ) (often using SiLU)
The Verdict: Multiplication Wins.
- Performance: Multiplicative gating consistently outperformed additive gating in benchmarks.
- The Intuition: Multiplicative gating acts as a filter. By multiplying by a value near 0, the model can completely erase irrelevant information (“shutting the valve”). Additive gating acts as a residual bias — it can add information, but it cannot easily remove noise that is already present in Y.
- The “No” Switch: To fix the “attention sink” problem, the model needs to discard the garbage output from the attention head. Multiplication allows for this erasure; addition merely piles more data on top.
4. Why Sigmoid? Why Not SiLU?
Standard LLMs use SiLU (Swish) for activations. Why switch to Sigmoid?
- The “No” Switch: Sigmoid outputs values strictly between [0,1]. This allows the gate to fully erase information (0) or pass it through (1).
- Performance: The authors tested SiLU at the G1 position and found it performed worse. Because SiLU is unbounded (it can output large numbers), it doesn’t provide the same strict “filtering” capability as Sigmoid.
- Sparsity: Sigmoid gating naturally pushes values toward 0, introducing sparsity that cleans up the signal.
5. Handling Multi-Head Attention
In Multi-Head Attention, the model has multiple “heads” looking at different things. The researchers tested two approaches:
- Head-Shared: One gating score shared across all heads.
- Head-Specific: Each head gets its own unique gating score.
The Verdict: Head-Specific gating is essential. Forcing heads to share a gate diminishes performance. This confirms that different heads capture different features — one head might be looking at critical context (Gate = 1) while another is looking at noise (Gate = 0) simultaneously.
6. Handling MoE Models
The study focused heavily on Mixture-of-Experts (MoE) models (15B total params, 2.5B activated).
- The gating is applied within the attention layer, separate from the Expert routing in the MLP layers.
- Adding these gates introduced negligible parameters (<2M) to the massive 15B model.
- Despite the tiny size, the gates outperformed “brute force” baselines like adding more attention heads or experts.
Part 2: Gated Delta Networks for Linear Models
Paper: Gated Delta Networks: Improving Mamba2 with Delta Rule
Models like Mamba replace quadratic attention with a state-space recurrence, updating an internal state through continuous decay. This design makes them fast and memory-efficient, but it also means information is gradually washed away: older signals fade whether they are still relevant or not. The result feels like writing on a whiteboard that is constantly being erased — scalable, but imprecise.
Delta Rule doesn’t learn by forgetting — it learns by correcting memory. Instead of gradually decaying memory, the Delta Rule maintains an explicit internal memory that is updated through correction-based writes. When new information arrives, the model first checks what its memory already contains for a similar situation. It then updates memory by adding only the difference between what was stored and what was just observed. This makes memory updates precise and additive, changing exactly what is necessary while leaving unrelated information untouched — more like editing a document than erasing a whiteboard.
However, the same mechanism that makes the Delta Rule precise also exposes its central limitation. Because memory updates are purely additive, information is never removed unless it is explicitly corrected later. Once written, a memory entry persists indefinitely, even if it becomes irrelevant to the current context. Over long sequences, this can cause memory to accumulate outdated or distracting information, cluttering the state and reducing effectiveness.
1. The Architecture: Gating Meets Delta
The researchers proposed Gated DeltaNet, which fuses Mamba’s forgetting capability with DeltaNet’s writing precision. The core state update equation is:
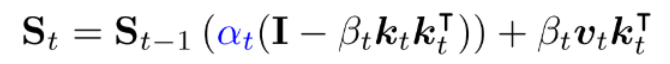
- αt (The Gate): Controls state decay. If the context shifts (e.g., a new document starts), αt can drop to 0, instantly wiping the memory clean.
- βt (The Delta Writer): Controls the writing strength. It allows the model to precisely replace specific key-value associations (vt for kt).
- (I−βtktkt⊤): This is the Householder transition matrix. It projects the state onto a subspace orthogonal to the key kt, effectively “clearing space” for the new data before writing it.
2. Hardware Efficiency: Chunkwise Parallelism
You cannot train this equation loop-by-loop — it is too slow for GPUs. To make it viable, the authors derived a Hardware-Efficient Chunkwise Algorithm.
- They extended the WY representation (a matrix decomposition method) to handle the gating term αt.
- This allows them to process the sequence in “chunks” (blocks of tokens) in parallel.
- Instead of sequential updates, the math is converted into Matrix Multiplications, which Tensor Cores can crunch through at high speed.
3. Why It Wins: The “Needle” Test
The authors tested this on the “Single Needle in a Haystack” (S-NIAH) benchmark:
- Mamba2: Failed as sequences got longer (>2k) because its decay (αt) slowly erased the “needle” (the crucial info).
- DeltaNet: Failed because it couldn’t clear the “haystack” (irrelevant noise) to make room in its memory.
- Gated DeltaNet: Succeeded with ~90–100% accuracy. The βt term wrote the needle precisely, and the αt gate protected it from being overwritten by noise.
Part 3: The Unified Connection
Why are two different papers — one on Softmax Attention and one on Linear SSMs — landing on the exact same solution?
1. Input-Dependent Sparsity is the Universal Fix
- In Softmax (Paper 1): Softmax attention comes with a hard constraint: for every token, attention weights must be non-negative and sum to one. This leaves the model no way to say “none of this context is useful.” Even when a query finds nothing relevant, softmax still forces attention to be assigned somewhere.
In deep layers, small biases accumulate. Tokens like the first or special start token are always present and tend to absorb this excess probability mass, gradually turning into attention sinks. The problem is not that attention routes incorrectly, but that every attention distribution is forced to produce a non-zero update, causing meaningless information to be repeatedly added to the model’s hidden state.
Gating solves this at the update level. A sigmoid gate is applied after attention, scaling the attention output before it is added back to the representation. These gates are highly sparse: when the context is irrelevant, the gate drives the update close to zero. Attention probabilities may still sum to one, but their effect is neutralized. By allowing the model to “look but not update,” gating removes the need for attention sinks and prevents noisy updates from accumulating on anchor tokens. - In Linear Models (Paper 2): The gate αt creates sparsity in the memory space. It allows the model to “reset” its hidden state St when the context shifts, preventing the “memory collision” that plagues fixed-size state models.
2. Non-Linearity at the Crucial Junction
- Paper 1 argues that placing the gate at G1 introduces non-linearity between the linear value projection (Wv) and the output projection (Wo). Without the gate, these two linear layers could technically collapse into a lower-rank transformation. The gate effectively increases the expressiveness (rank) of this mapping.
- Paper 2 argues that the Delta Rule itself (I−βkkT) creates a data-dependent, higher-rank transition matrix compared to Mamba’s simple diagonal decay, and adding the non-linear gate αt further enhances this expressivity.
3. Training Stability Both papers report that gating stabilizes training.
- Softmax: The gate dampens massive activations in the residual stream, which are the root cause of loss spikes in large models.
- Linear: The gate acts as an adaptive weight decay on the hidden state, preventing the state St from exploding or saturating, which is a common failure mode in RNNs.
In summary: Gating is not just a feature; it is the necessary control mechanism for noise. Whether that noise is the “attention sink” in a Transformer or “irrelevant history” in an SSM, the solution is the same: give the model a mathematically precise way to multiply the signal by zero.
Link to original papers:
– Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
– Gated Delta Networks: Improving Mamba2 with Delta Rule
Until next time folks…
El Psy Congroo

Gated Attention & DeltaNets: The Missing Link for Long-Context AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.