From DSP to AI: Evolving Approaches in Audio Processing
Introduction: Audio as a First-Class Intelligence Modality
Audio is one of the most information-dense and perceptually sensitive modalities through which humans interact with the world. Unlike vision or text, audio is continuous in time, governed by physical acoustics, and immediately evaluated by the human auditory system with millisecond-level sensitivity. These properties make audio uniquely challenging for artificial intelligence systems. Even small distortions—phase discontinuities, temporal smearing, and spectral artifacts—can result in degraded intelligibility, listener fatigue, or loss of immersion.
Historically, audio systems were built using deterministic digital signal processing (DSP). These systems relied on mathematically grounded tools such as filters, transforms, adaptive estimators, and physical models of sound propagation. DSP methods provided stability, causality, and real-time guarantees, but they struggled with highly non-stationary signals, complex acoustic environments, and semantic understanding.
The emergence of machine learning introduced a fundamentally different paradigm. Instead of explicitly modeling every acoustic phenomenon, learning-based systems infer complex mappings from data. This change led to big advances in speech recognition, noise reduction, music creation, and modeling spatial audio. However, early attempts to replace DSP entirely with end-to-end neural networks quickly exposed limitations. Purely data-driven models often failed under unseen conditions, violated physical constraints, or required computational resources incompatible with real-time deployment.
Because of this, modern audio intelligence has moved toward a hybrid approach. In this framework, classical signal processing offers structural priors, physical grounding, and system assurances, whereas machine learning enhances adaptability, perception, and contextual reasoning. Audio AI is therefore not simply an application of generic ML, but a domain where intelligence must be engineered within strict temporal, physical, and perceptual constraints.
This article presents a systematic, engineering-focused view of artificial intelligence in audio and signal processing. Instead of seeing progress as just replacing old methods, it highlights how digital signal processing (DSP), machine learning, and systems engineering come together to create effective, usable systems. Each section explores a major dimension of this convergence, maintaining equal depth to reflect the balanced nature of modern audio systems.
Classical Signal Processing Foundations in the AI Era
Despite advances in machine learning, classical signal processing remains foundational to audio intelligence. Audio signals are sampled at high rates, typically between 44.1 kHz and 192 kHz, and must be processed continuously without interruption. This imposes strict computational and architectural constraints that cannot be ignored. Signal processing theory provides the tools to reason about these constraints formally.
One of the most fundamental concepts in audio processing is the time–frequency tradeoff. Representations such as the Short-Time Fourier Transform (STFT) balance temporal resolution against spectral resolution, a tradeoff that directly affects perceived audio quality. Human perception is sensitive to both transient timing and harmonic structure, making representation design a critical engineering decision.
Stability and causality are equally important. Many audio applications—telephony, conferencing, automotive systems, augmented reality—require causal processing with bounded latency. Algorithms that rely on future samples or long context windows may perform well offline but are unsuitable for interactive systems. DSP provides formal guarantees, such as bounded-input bounded-output stability, that ensure predictable behavior under all operating conditions.
Signal processing also encodes physical knowledge. Acoustic propagation, reverberation, and spatial cues arise from well-understood physical processes. Ignoring these principles often leads to models that fit training data but fail catastrophically when conditions change. DSP structures act as inductive biases, guiding learning toward physically plausible solutions.
In the AI era, DSP does not compete with machine learning; it constrains and enables it. By embedding DSP primitives into learning pipelines, engineers reduce sample complexity, improve robustness, and ensure deployability. This foundation is essential for understanding why modern audio AI systems look the way they do.
Audio Perception and Semantic Understanding
Audio perception systems aim to extract semantic meaning from sound. Tasks such as acoustic scene classification, sound event detection, and audio tagging enable machines to interpret their auditory environment. These capabilities are critical for applications ranging from smart devices and surveillance to autonomous systems and assistive technologies.
Most perception pipelines start by changing raw waveforms into time-frequency representations. Log-mel spectrograms are popular because they are easy to use and make sense to the brain. Deep neural networks, which are usually convolutional or transformer-based, then process these representations. These networks learn hierarchical audio features.
A major advance in this domain has been the development of large-scale pretrained audio models. By training on massive, weakly labeled datasets, these models learn general audio representations that transfer effectively across tasks. This has reduced the need for task-specific feature engineering and improved performance in low-data regimes.
However, perception tasks remain sensitive to front-end choices, temporal context, and domain mismatch. Differences in microphones, noise conditions, and recording environments can significantly impact performance. As a result, perception systems often incorporate normalization, data augmentation, and domain adaptation strategies.
Importantly, semantic understanding does not eliminate the need for signal processing. Temporal alignment, phase coherence, and resolution tradeoffs still influence model behavior. Successful perception systems therefore, integrate learned representations within carefully engineered signal pipelines.
Audio Enhancement and Restoration Systems
Audio enhancement focuses on improving signal quality under adverse conditions. Common tasks include noise suppression, dereverberation, echo cancellation assistance, and packet loss concealment. These systems are typically deployed in real-time communication pipelines, where latency and stability are critical.
Enhancement is particularly challenging because errors are immediately perceptible. Artifacts such as musical noise, speech distortion, or temporal pumping degrade user experience and can reduce intelligibility. Unlike perception tasks, enhancement systems must operate causally and continuously.
Predict whether speech is present, create spectral masks, or determine gain functions, while DSP components handle sound reconstruction, combine audio segments, and remove artifacts. Machine learning models determine the presence of speech, create spectral masks, and establish gain functions, while DSP components handle sound reconstruction and the combination of audio segments. This division of labor allows learning systems to focus on inference, ensuring that DSP maintains both physical and perceptual correctness.
Latency limits are the most important factor in design choices. To find the right balance between responsiveness and frequency resolution, frame sizes, hop lengths, and buffering strategies are chosen. Neural models must be optimized for streaming inference, often using causal convolutions or stateful recurrent architectures.
The success of enhancement systems illustrates the broader theme of audio AI: intelligence emerges not from replacing classical methods, but from augmenting them with learned inference under strict system constraints.
Source Separation and Audio Demixing
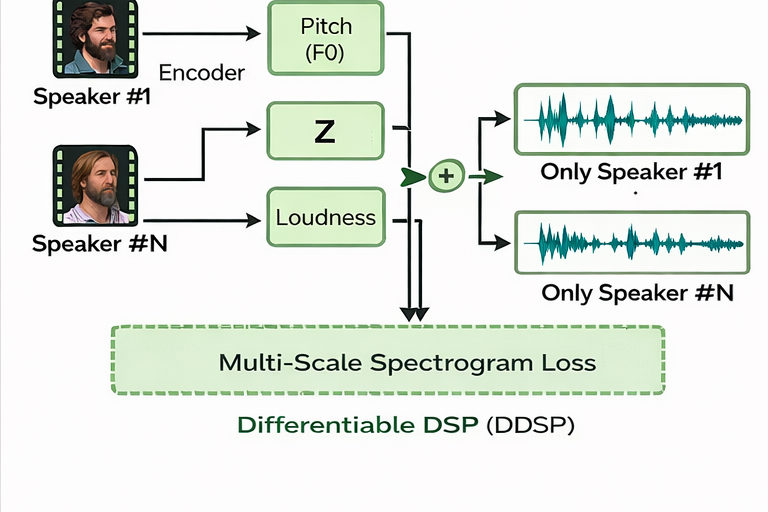
Source separation aims to decompose an audio mixture into its constituent signals. Applications include multi-speaker separation, music stem extraction, and dialog isolation. These tasks are central to media production, communication, and accessibility.
Deep learning has dramatically improved separation quality by learning complex source priors. Most systems operate in the time–frequency domain, estimating masks that isolate individual sources. Phase reconstruction remains a central challenge, as magnitude-only modeling can introduce artifacts.
Hybrid approaches dominate production systems. Neural networks estimate spectral components, while DSP handles synthesis, phase consistency, and temporal smoothing. Multi-resolution losses and perceptual objectives are commonly used to improve quality.
Despite impressive numerical metrics, perceptual evaluation remains essential. Separation systems highlight the limits of purely objective measures and reinforce the importance of human-aligned evaluation in audio AI.
Spatial Audio and Acoustic Scene Modeling
Spatial audio extends intelligence into three-dimensional space. Tasks include sound source localization, beamforming, room modeling, and immersive rendering. These capabilities are essential for AR/VR, automotive systems, and advanced media experiences.
Spatial cues arise from physical geometry: inter-channel time differences, level differences, and spectral coloration. While neural networks can learn mappings from multichannel signals to spatial parameters, these are constrained by physics.
Modern spatial systems use AI for estimation and adaptation, while DSP handles filtering and rendering. This preserves physical consistency while enabling personalization and environmental awareness.
Audio Generation and Differentiable DSP
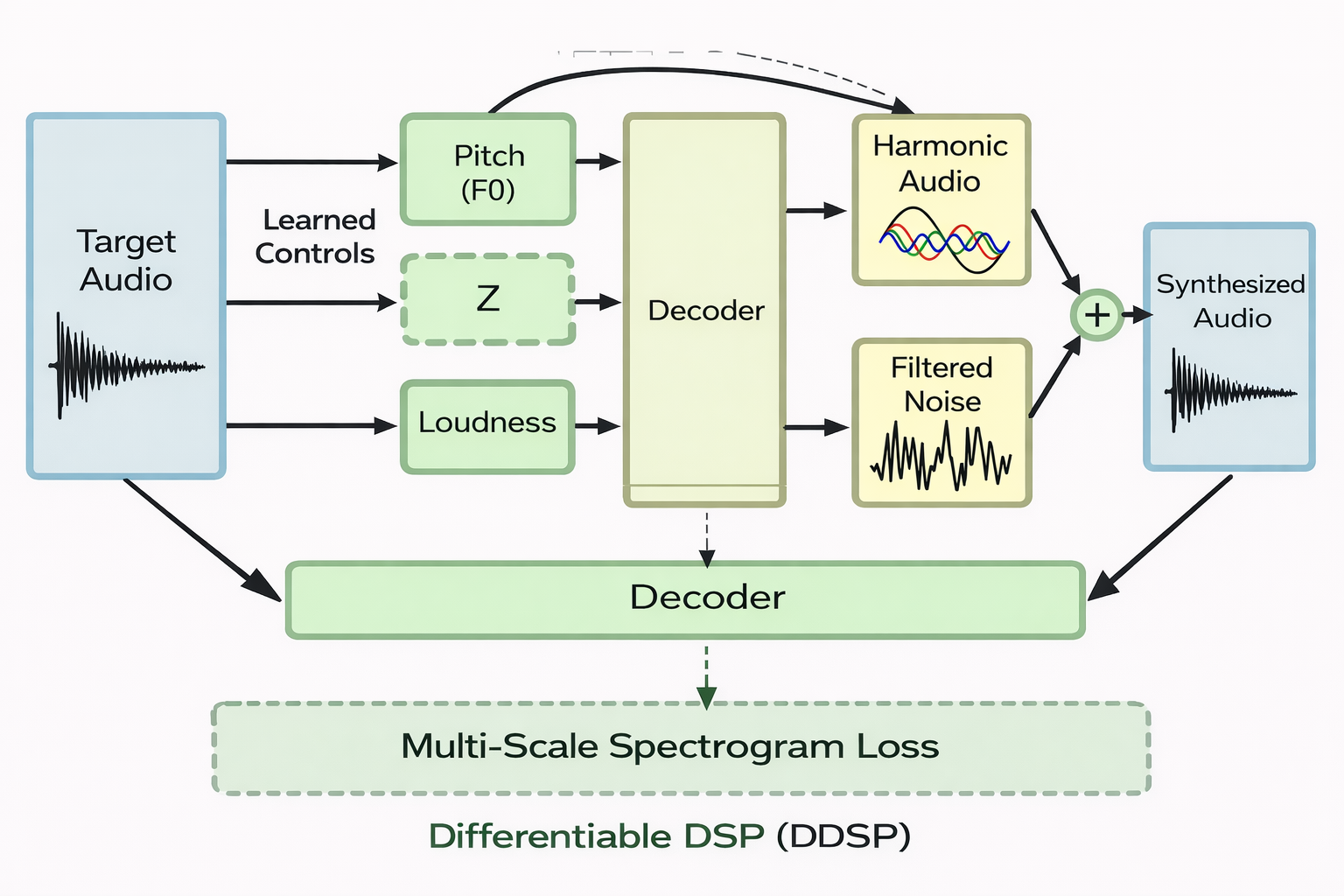
Generative audio systems create sound rather than analyze it. Applications include text-to-speech, music composition, and sound design. While end-to-end neural generation has achieved impressive realism, it often lacks controllability and efficiency.
Differentiable Digital Signal Processing (DDSP) addresses these limitations by embedding signal models directly into neural networks. Oscillators, filters, and envelopes become trainable components, combining interpretability with learning. DDSP exemplifies the hybrid philosophy of modern audio AI learning that operates within structured, physically meaningful models.
Explainability, Evaluation, and Trust
As audio AI systems enter regulated and safety-critical domains, explanation and evaluation become essential. Audio-specific XAI techniques visualize time–frequency contributions, enabling engineers to inspect model behavior.
Evaluation remains challenging due to the gap between objective metrics and perception. Robust systems combine signal, perceptual, task-level, and stress-test evaluations.
Trustworthy audio AI requires transparency, reproducibility, and alignment with human perception.
Systems Engineering and the Future of Intelligent Audio
Ultimately, audio intelligence is a systems engineering problem. Real-time constraints, power budgets, and deployment environments shape every design decision. Successful systems integrate DSP, AI, and software engineering into cohesive pipelines.
The future of audio lies in adaptive, context-aware, explicable systems that operate seamlessly across devices and environments. Audio is no longer a passive signal—it is an intelligent interface connecting humans and machines.
References:
- Steinmetz et al. — “Audio Signal Processing in the Artificial Intelligence Era: Challenges and Directions”
- Akman & Schuller — “Audio Explainable Artificial Intelligence: A Review” (Intelligent Computing)
- McCarthy et al. — “Machine Learning in Acoustics: A Review and Open-source Repository”
- IEEE Signal Processing Magazine — “The Convergence of Machine Learning and Signal Processing…” (framing/editorial page)
- Kong et al. — “PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition”
- Cobos et al. — “An overview of machine learning and other data-based methods for spatial audio capture, processing, and reproduction”