 Without Catastrophic Forgetting")
Fine-Tuning Large Language Models (LLMs) Without Catastrophic Forgetting
Introduction
Fine-tuning large language models (LLMs) is no longer optional — it is the standard way to adapt foundation models to domains such as healthcare, finance, legal text, customer support, or internal enterprise data. However, naive fine-tuning often leads to catastrophic forgetting, where the model learns the new task but degrades on previously learned capabilities.
This article provides a practical, engineering-focused guide to:
- Fine-tuning strategies
- Preventing catastrophic forgetting
- Where and how to apply LoRA / QLoRA
- Layer-by-layer tuning strategies for GPT-style and encoder–decoder models
- Choosing between LoRA, adapters, and prefix tuning
Why Fine-Tuning Matters
Large Language Models (LLMs) like GPT, LLaMA, and T5 are trained on massive amounts of general text. Out of the box, they know language, but they don’t know your domain, your task, or how you want them to behave.
Fine-tuning is the process of adapting these models so they:
- Understand your domain (medical, legal, finance, etc.)
- Perform specific tasks (QA, stigmatization, classification)
- Follow instructions reliably
- Behave safely and consistently
However, fine-tuning must be done carefully — otherwise the model may forget what it already learned.
Pls note: Fine-Tuning Comes Before Pruning
Pretrained Model
↓
Fine-Tuning (Full / PEFT)
↓
(Optional) Pruning / Quantization
↓
Deployment (Edge / Cloud)
Pruning removes model capacity. Fine-tuning needs that capacity to adapt effectively. Therefore, pruning should be applied after fine-tuning, especially for edge deployment.
The Big Risk: Catastrophic Forgetting (In Simple Terms)
Catastrophic forgetting occurs when gradient updates overwrite weights that encode general language knowledge. In Simple words
“The model learns the new thing, but forgets the old things.”
This happens when:
- Learning rates are too high
- All layers are updated aggressively
- The dataset is small
- Important layers are overwritten
Preventing forgetting is largely about where, how much, and how aggressively we update parameters.
Learning Rate: Why Warmup + Cosine Decay Is Important
Warmup
Training starts with a very small learning rate and slowly increases.
Why?
- Prevents sudden weight changes
- Protects pretrained knowledge
- Stabilizes early training
Cosine Decay
After reaching the peak learning rate, it gradually decreases.
Why?
- Learn faster early
- Fine-tune gently later
- Reduce forgetting
This schedule is now the default best practice for transformer fine-tuning.
Understanding Transformer Layers
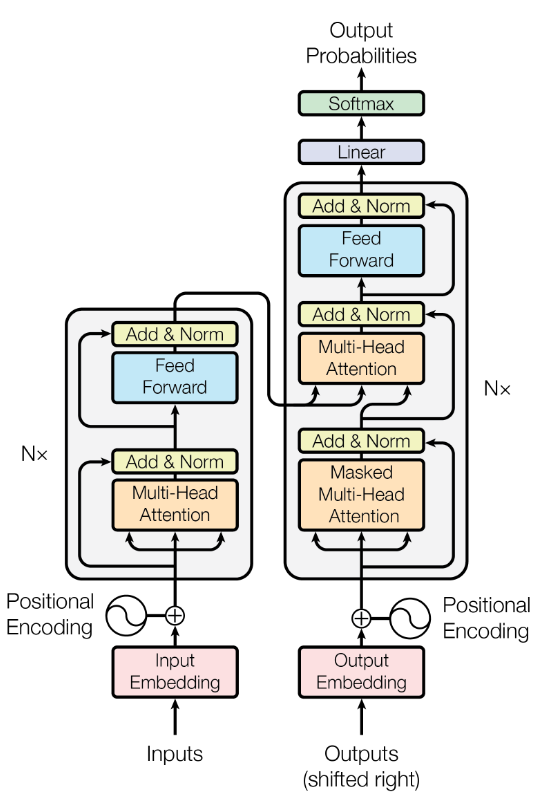
LLM Build with many Transformer layers stacked (Ex. GPT2 has 12 such decoder only layers)
Each layer learns distinct features of the domain. ex for a transformer trained on English summerization task may have each layer learned
Layer | What it learns
Embeddings | Word meaning
Lower layers | Grammar, syntax
Middle layers | Meaning, relationships
Upper layers | Task behavior, style
Key idea: Lower layers remember language basics — don’t change them much.
so its like a kid learning basics of language we want him to become expert of a domain we must retain his basic language understanding so mostly we dont touch lower layers. we should train higher layers. so its better to freeze lower layers (in most of the cases unless we go for full fine tuning)
Example: GPT-style model with 12 layers
Embeddings → frozen
Layers 1–6 → frozen
Layers 7–9 → lightly trainable
Layers 10–12 → fully adaptable
Parameter-Efficient Fine-Tuning (PEFT)
Instead of training billions of parameters, PEFT methods add small trainable components.
Benefits:
- Faster training
- Less memory
- Much less forgetting
LoRA Explained Simply
LoRA (Low-Rank Adaptation) works by:
- Freezing original model weights
- Adding small trainable matrices
- Learning how to adjust behavior, not rewrite knowledge
LoRA is usually applied only to:
- Attention Query (Q)
- Attention Value (V)
This changes what the model focuses on and what it outputs.


Where LoRA Is Placed in a Transformer
Inside each transformer block:
- Attention → LoRA applied
- Feed-forward network → frozen
This protects stored knowledge while allowing adaptation.
Layer-by-Layer LoRA Strategy (GPT Example)
Embedding → frozen
Layer 1–6 (lower) → frozen (no LoRA)
Layer 7–9 (middle) → LoRA (low rank)
Layer 10–12 (upper) → LoRA (higher rank)
LM Head → trainable
Where LoRA is inserted
Self-attention only
Q and V projections only
[Attention Block]
Q_proj ← LoRA
K_proj ← frozen
V_proj ← LoRA
O_proj ← frozen
FFN ← frozen
GPT Example
| Layer Range | Role | Rank (r) | Alpha |
| ----------- | ------ | -------- | ----- |
| 1–6 | frozen | – | – |
| 7–9 | middle | 4–8 | 16 |
| 10–12 | upper | 8–16 | 32 |
| LM head | task | train | – |
Encoder–Decoder Models (T5, BART)
For encoder–decoder models:
Priority order:
- Decoder self-attention
- Cross-attention
- Encoder self-attention (optional)
| Component | Rank |
| ----------------- | -------------- |
| Decoder self-attn | 8–16 |
| Cross-attn | 8–16 |
| Encoder self-attn | 4–8 (optional) |
HuggingFace + PEFT Code
Decoder only
from transformers import AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
model = AutoModelForCausalLM.from_pretrained(
"gpt2",
torch_dtype="auto"
)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["c_attn"], # GPT-2 uses fused QKV
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
layers_to_transform=[9, 10, 11] # upper layers only
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
Note:
- c_attn contains QKV fused
- PEFT internally applies LoRA correctly
Encoder Decoder Type (T5/BART)
from transformers import AutoModelForSeq2SeqLM
from peft import LoraConfig, get_peft_model
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type="SEQ_2_SEQ_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
QLoRA (Same Logic, Less Memory)
QLoRA works by combining several techniques to balance memory efficiency with high performance:
- 4-bit NormalFloat (NF4): This is an information-theoretically optimal data type for normally distributed data used to store the frozen pre-trained model weights in 4-bit precision, drastically reducing their memory footprint.
- Double Quantization: This technique further optimizes memory usage by quantizing even the quantization constants, resulting in additional memory savings.
- Paged Optimizers: QLoRA uses the NVIDIA unified memory feature for the optimizer states, which acts like virtual memory, automatically offloading data to the CPU RAM when the GPU runs out of memory and paging it back when needed, ensuring error-free processing.
- Low-Rank Adaptation (LoRA) Adapters: While the main model weights are frozen in 4-bit, small, trainable “adapter” layers are injected into each layer of the LLM. Only these small adapter weights are trained in a higher precision (e.g., bfloat16), and gradients are backpropagated through the quantized model to update them.
Key Benefits
- Memory Efficiency: QLoRA can fine-tune multi-billion parameter models on a single GPU by significantly lowering VRAM requirements.
- High Performance: Despite the memory savings, QLoRA achieves performance levels comparable to full 16-bit fine-tuning, with minimal performance loss.
- Accessibility: It makes fine-tuning large models more accessible to individuals and smaller institutions with limited computational resources.
- Preservation of Knowledge: The original, frozen model weights remain intact, which helps in preserving the pre-trained knowledge during adaptation to new tasks.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(
"gpt2",
quantization_config=bnb_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
Example of Fine tuning types by usage
- Domain-Specific Fine-Tuning
Goal: Teach the model your domain language.
Examples:
- Medical notes
- Legal contracts
- Financial reports
Characteristics:
- Mostly unlabeled text
- No instructions
Usually done with:
- LoRA or QLoRA
- Middle + upper layers
2. Task-Specific Fine-Tuning
Goal: Teach the model what to do.
Examples:
- Question answering
- Summarization
- Classification
Uses labeled input-output pairs.
3. Instruction Tuning
Instruction tuning teaches the model to follow natural language instructions.
Trainable data Format :
Instruction: Do X
Input: Context
Output: Answer
This enables:
- Zero-shot behavior
- Few-shot generalization
4. Alignment Training (Optional)
Once model is fine tuned the goal of Alignment training to makes models:
- Polite (respond in specific way)
- Safe (use guardrails to prevent model from generating unwanted content)
- Consistent (behave more humanly)
Types:
- Supervised fine-tuning (SFT)
- Preference learning (RLHF / DPO)
Most internal systems do not require RLHF.
How LoRA & QLoRA Reduce Catastrophic Forgetting
Catastrophic forgetting happens when:
- You update core pretrained weights
- Gradients overwrite representations that encode:
- Grammar
- World knowledge
- General reasoning
Full fine-tuning = high risk, especially with:
- Small datasets
- High learning rates
- Domain-specific data
What LoRA Actually Does
W' = W (frozen) + ΔW
ΔW = A · B (low-rank, trainable)
Where:
- W = original pretrained weights (frozen)
- A, B = small trainable matrices
Three Ways LoRA Prevents Forgetting
1. Weight Isolation (Most Important)
- Pretrained weights are frozen
- New knowledge lives in separate parameters
- Forgetting becomes structurally difficult
2. Low-Rank Constraint = Controlled Change
LoRA restricts updates to a low-dimensional subspace.
This means:
- The model can adapt
- But cannot radically rewrite representations
“Adjust the steering wheel, not rebuild the engine.”
3. Targeted Placement (Attention Only)
LoRA is usually applied to:
- Attention Q (what to focus on)
- Attention V (what information to pass forward)
It avoids:
- FFN layers (knowledge-heavy)
- Embeddings (global semantics)
This selective plasticity dramatically lowers forgetting risk.
Key things still to consider event with LoRA/QLoRA
- Add LoRA/QLoRA to Attention: Q, V only
- Rank Selection (r) Rank controls how much the model can change. Higher Rank = higher risk of forgetting
- Learning Rate: Use low LR. Warmup+cosine decay, early stopping
- Dataset Composition: Mix Data (general text + old task example) LoRA protects weights, but data still matters.
- Training Duration: Over-training can cause:
- Over-specialization
- Implicit forgetting (behavioral)
Use: Validation on old capabilities, Early stopping
LoRA shines here:
- One LoRA adapter per domain
- Swap adapters at inference
- No interference between tasks
Can You Train on Multiple Domains with Multiple LoRA Adapters?
Yes — and it’s actually recommended
Instead of one monolithic fine-tune, you can:
- Keep one frozen base model
- Attach multiple LoRA adapters
- Each adapter specializes in one domain or task
Base Model (frozen)
├── LoRA_finance
├── LoRA_medical
├── LoRA_legal
└── LoRA_general
How Does the Model Know Which LoRA to Use?
1 Manual / Explicit Routing (Most Common)
You decide which adapter to load at inference time.
model.set_adapter("medical")
When to use
- Domain is known (API, product feature, dataset)
- Enterprise systems
- Internal tools
Prompt-Based Routing (Lightweight & Practical)
A domain tag in the prompt implicitly activates a LoRA.
<domain=medical>
Patient presents with chest pain...
Implementation
- Train each LoRA with a domain prefix
- The adapter learns to respond only when prefix is present
Learned Router (Mixture-of-LoRA)
A small routing network selects:
- One LoRA
- Or a weighted combination of LoRAs
Input → Router → [w1, w2, w3]
Output = w1·LoRA₁ + w2·LoRA₂ + w3·LoRA₃
This is similar to Mixture of Experts (MoE) its Automatic
Handles mixed-domain inputs
Hierarchical / Cascaded Routing (Advanced)
How it works
- Classify domain
- Activate LoRA
- Generate output
Input
↓
Domain Classifier
↓
Select LoRA
↓
LLM
Can Multiple LoRAs Be Active at Once?
Ans: Yes (but with caution)
Options:
- Single LoRA active (recommended)
- Weighted combination (advanced)
- Sequential LoRA (rare)
LoRA_finance (0.7)
LoRA_legal (0.3)
How PEFT Supports This (HuggingFace)
model.add_adapter("finance", lora_config)
model.add_adapter("medical", lora_config)
model.add_adapter("legal", lora_config)
model.set_adapter("medical") # runtime routing
Training Strategy for Multi-Domain LoRA
Best Practice (Strongly Recommended)
- Train one LoRA per domain
- Do NOT mix domains in a single adapter
- Keep a small “general” adapter if needed
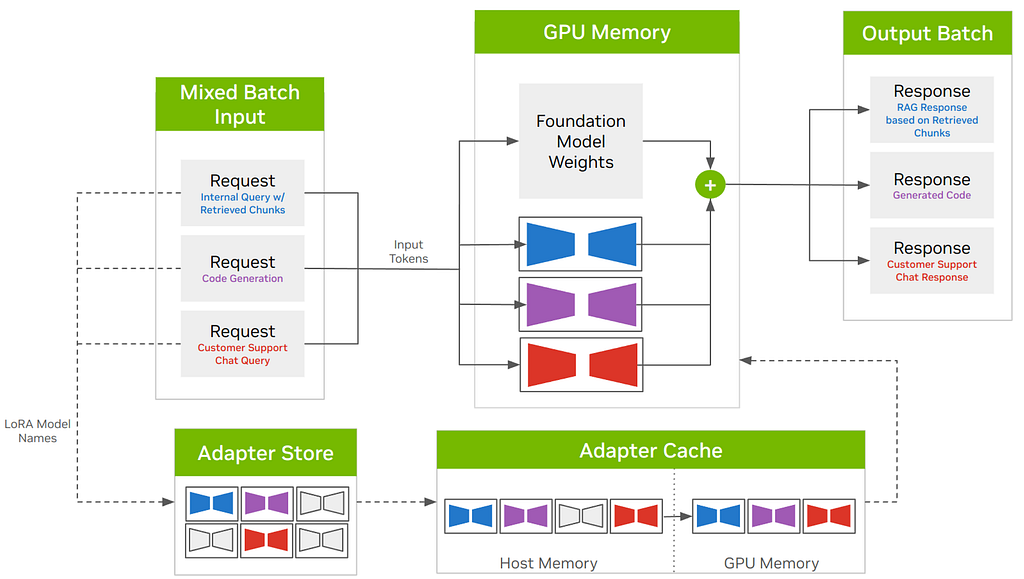
┌────────────────────-┐
Input ───────────▶ │ Base LLM (Frozen) │
│ (GPT / LLaMA / T5) │
└─────────┬─────────-─┘
│
┌────────────────┼────────────────┐
│ │ │
LoRA_finance LoRA_medical LoRA_legal
(isolated) (isolated) (isolated)
Multi LoRA Routing Code
# Load base model
model = load_base_model()
# Add adapters
model.add_adapter("finance", lora_config)
model.add_adapter("medical", lora_config)
model.add_adapter("legal", lora_config)
# Runtime routing
domain = router.predict(input_text)
model.set_adapter(domain)
output = model.generate(input_text)
Maths Behind LoRA
Any Standard Layer (attention or FFN) has
y=xW
x∈R1×din, W∈Rdin×dout
During full fine-tuning, we update: W←W+ΔW
Fine-tuning updates lie in a low-rank subspace
rank(ΔW)≪min(din,dout)
LoRA Parameterization
ΔW=BA
Where:
A∈Rr×din
B∈Rdout×r
r≪din,dout
So the effective weight becomes:
W′=W+BA
Parameter breakdown (GPT2 as example)
| Component | % of params |
| --------------- | ----------- |
| FFN (MLP) | ~65–70% |
| Attention | ~25–30% |
| Embeddings + LN | ~5% |
we dont apply lora at FFN so we ignore 70% weights for tunning
we apply LoRA on Attention (Multihead) layers that too with low rank so overall tunable paramters are quite low ~ 0.1% of overall
How many attention heads are there in model
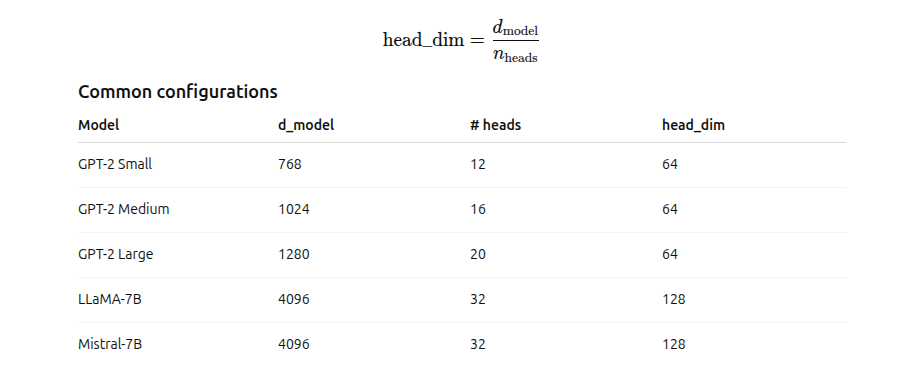
Head dimension is usually 64 or 128
What is the “size” of one attention head?
Each head has its own:
- Query projection
- Key projection
- Value projection
each head of size=head_dim×dim_model
For GPT-2 Small: 64×768
for we combine all heads together then apply LoRA
head=h1⊕h2⊕h3…⊕hn
In multi-head attention, LoRA is applied to the single combined projection matrix (Q/K/V), not to individual heads.
All heads are combined, the LoRA update is added, and then the result is split into heads.
Order of operations
- Combine all heads (they are already combined in WQW_QWQ)
- Add LoRA update BA
- Compute projection
- Split into heads
Q = X @ (W_Q + B @ A)
Q = Q.view(batch, seq, n_heads, head_dim)
LoRA sees all heads together
Fine-Tuning Large Language Models (LLMs) Without Catastrophic Forgetting was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.