
Essential Python Libraries for Data Science
Part 5: AutoML and Scalable Experimentation

Once data pipelines are stable and models are governed, the bottleneck in data science systems shifts.
In the earlier parts of this series, we focused on building control before complexity. We established strong data foundations, validated assumptions through diagnostics, introduced classical machine learning with discipline, and extended into gradient boosting without breaking reproducibility or governance.
At that stage, models are no longer fragile. They are reliable.
Yet progress often slows.
Not because teams lack algorithms, but because experimentation itself becomes expensive. Each new idea requires manual setup. Each comparison takes time. Each iteration introduces the risk of inconsistency. As datasets grow and modeling options expand, the cost of exploration begins to dominate the workflow.
This is the point where many teams turn to AutoML.
That decision is often misunderstood.
AutoML is not about replacing data scientists, automating judgment, or skipping fundamentals. In mature systems, AutoML serves a very specific role: scaling experimentation without weakening control.
This part focuses on AutoML from that perspective.
We will examine how AutoML frameworks accelerate model comparison, hyperparameter exploration, and pipeline construction, while still respecting the constraints established earlier in the series. The goal is not to let tools make decisions for us, but to reduce the friction involved in testing ideas responsibly.
As with previous parts, this discussion is grounded in production reality. We will treat AutoML as an extension of disciplined workflows, not a shortcut around them. The same principles still apply: reproducibility, explainability, evaluation rigor, and governance remain non-negotiable.
By the end of this part, AutoML will no longer feel like a black box or a threat to good practice. It will feel like what it is meant to be in real systems: a controlled accelerator layered on top of sound engineering.
Transition to the First Section
Before introducing any AutoML framework, it is important to clarify what AutoML should and should not be responsible for in a production data science system.
That is where we will begin.
Step 21: What AutoML Is — and What It Is Not
Before introducing any AutoML framework, it is essential to be clear about what AutoML is responsible for in a mature data science system, and what it is not.
Most misunderstandings around AutoML stem from misplaced expectations. Teams either expect too much from it or reject it entirely based on poor early experiences. Both reactions miss the point.
AutoML is not a replacement for fundamentals. It is a multiplier for well-designed workflows.
What AutoML Is
In production-oriented environments, AutoML is best understood as an automation layer over experimentation.
Its primary responsibilities include:
- Systematically exploring model choices
- Managing hyperparameter search
- Standardizing evaluation
- Reducing manual repetition
- Accelerating comparison across approaches
Used correctly, AutoML reduces friction without removing human judgment.
What AutoML Is Not
AutoML is not:
- A substitute for data understanding
- A shortcut around diagnostics
- A guarantee of optimal performance
- A replacement for domain expertise
- An excuse to skip evaluation discipline
When AutoML is applied to poorly prepared data or undefined objectives, it simply automates failure at scale.
Why AutoML Appears Powerful (and Why That Can Be Dangerous)
AutoML often looks impressive because it produces results quickly. However, speed alone does not equal correctness.
Without guardrails:
- Models may overfit silently
- Validation may be misaligned with business goals
- Results may be irreproducible
- Governance requirements may be violated
AutoML amplifies whatever process it is applied to. Strong processes improve. Weak processes collapse faster.
The Right Mental Model
A useful way to think about AutoML is this: AutoML automates search, not thinking.
Humans still define:
- The problem
- The data boundaries
- The evaluation criteria
- The constraints that matter
AutoML simply explores within those boundaries more efficiently than manual experimentation.
Why This Distinction Matters Before Tools
If this boundary is not clear, AutoML tools tend to be misused:
- Treated as black boxes
- Trusted blindly
- Or rejected prematurely
Neither outcome is productive.
This step ensures that AutoML is introduced deliberately, as an engineering decision rather than a reaction to complexity.
Transition to the Next Step
With expectations clearly defined, we can now examine where AutoML fits naturally into the workflow we have already built.
Step 22: Where AutoML Fits in a Production ML Pipeline
AutoML delivers the most value when it is placed deliberately within an existing workflow. When inserted too early, it amplifies noise. When inserted too late, it adds little value.
In mature data science systems, AutoML does not replace stages of the pipeline. It operates within them, under clearly defined constraints.
The Pipeline We Have Built So Far
By this point in the series, the pipeline already includes:
- Structured and validated data foundations
- Documented assumptions and diagnostics
- Stable train-test splits
- Baseline models with known behavior
- Controlled nonlinear models with governance in place
This context is critical. AutoML is not being asked to discover structure from chaos. It is being asked to explore within known boundaries.
Where AutoML Adds Real Value
AutoML is most effective in three areas:
- Model Comparison at Scale
Instead of manually testing one model at a time, AutoML can explore multiple algorithm families consistently and fairly. - Hyperparameter Exploration
AutoML frameworks can search parameter spaces more efficiently than manual tuning, while preserving evaluation rigor. - Pipeline Standardization
AutoML enforces consistent preprocessing, validation, and metric computation across experiments.
In all three cases, AutoML reduces repetition rather than responsibility.
Where AutoML Does Not Belong
AutoML should not be used to:
- Replace exploratory data analysis
- Decide business objectives
- Override diagnostic insights
- Select metrics without context
- Mask poor data quality
These decisions remain human-owned.
A Useful Placement Rule
A simple rule that works well in production:
If a step requires judgment, AutoML should not own it.
If a step requires repetition, AutoML probably should.
This rule keeps authority where it belongs.
How This Preserves Control
By positioning AutoML after foundations and diagnostics, but before final model selection, teams gain:
- Faster iteration
- Broader exploration
- Comparable results
- Reproducible experiments
Without sacrificing:
- Interpretability
- Governance
- Accountability
This balance is what makes AutoML viable in long-lived systems.
Transition to the Next Step
With AutoML placed correctly in the pipeline, the next step is to examine specific frameworks and understand what problems each one is designed to solve.
Step 23: AutoML Frameworks — What Each Tool Is Actually Good At
AutoML is often discussed as a single capability. In reality, it is a family of tools with very different design goals. Treating them as interchangeable leads to misuse and disappointment.
In production systems, the question is not which AutoML tool is best, but which tool fits the constraints of the problem.
This step focuses on understanding AutoML frameworks by what they optimize for, rather than by feature lists.
PyCaret: Structured, Opinionated Experimentation
PyCaret is designed to accelerate experimentation for structured data problems by enforcing a standardized workflow.
Its strengths include:
- Rapid baseline generation
- Consistent preprocessing and evaluation
- Clean comparison across multiple models
- Low setup overhead
PyCaret works best when:
- The problem is well-defined
- Metrics are agreed upon
- Fast iteration is needed
- Transparency matters more than deep customization
It is less suitable when highly custom pipelines or unusual constraints are required.
Auto-sklearn: Optimization Within Familiar Boundaries
Auto-sklearn builds directly on scikit-learn. Instead of replacing the ecosystem, it automates:
- Algorithm selection
- Hyperparameter tuning
- Pipeline configuration
This makes it appealing in environments where:
- scikit-learn is already standard
- Reproducibility is important
- Existing pipelines must remain compatible
Auto-sklearn trades speed for thoroughness. It is most effective when exploration time is available and results must integrate cleanly with existing systems.
H2O AutoML: Scale and Distributed Experimentation
H2O AutoML is built for scale.
It excels when:
- Datasets are large
- Training must be distributed
- Enterprise environments are involved
- Model tracking and governance are required
Its ecosystem is broader and more opinionated. This can be an advantage in large organizations, but a barrier in lightweight workflows.
TPOT: Evolutionary Search for Pipelines
TPOT uses genetic programming to evolve entire pipelines.
Its strength lies in:
- Discovering non-obvious combinations
- Exploring unconventional pipelines
- Maximizing performance without manual design
However, this flexibility comes at a cost:
- Reduced interpretability
- Longer runtimes
- Less predictable behavior
TPOT is best suited for research-oriented exploration rather than tightly governed production systems.
Optuna and FLAML: Control with Acceleration
Optuna and FLAML focus on optimization rather than abstraction.
They are particularly effective when:
- The model class is known
- The search space is well defined
- Fine-grained control is required
- Experiment tracking matters
These tools integrate cleanly into custom pipelines and are often preferred in mature engineering environments.
Choosing Based on Constraints, Not Hype
A practical way to select an AutoML framework is to map tools to constraints:
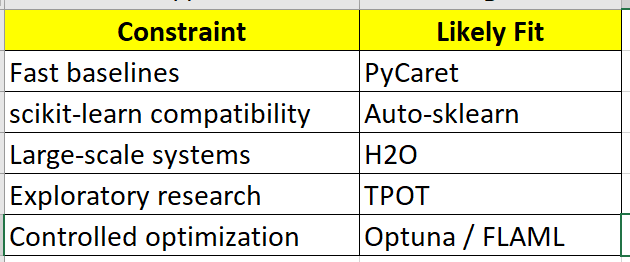
No tool replaces judgment. Each simply accelerates a different part of the workflow.
Why This Step Matters
AutoML tools encode assumptions. Using them blindly imports those assumptions into your system.
Understanding what each framework is designed to optimize for allows teams to:
- Avoid unnecessary complexity
- Preserve governance
- Scale experimentation responsibly
Transition to the Next Step
With the landscape of AutoML tools clarified, the next step is to use one deliberately within the pipeline we already control.
Step 24: Using AutoML Without Breaking Reproducibility
AutoML promises speed. Reproducibility demands restraint.
The tension between these two is where many otherwise strong data science systems fail. AutoML frameworks explore large search spaces quickly, but without explicit controls, that exploration can become opaque, non-repeatable, and difficult to govern.
This step focuses on how to use AutoML without sacrificing reproducibility, which remains a non-negotiable requirement in production environments.
Why Reproducibility Is at Risk with AutoML
AutoML systems often introduce variability through:
- Randomized search strategies
- Dynamic pipeline generation
- Parallel execution
- Adaptive stopping criteria
Without guardrails, two AutoML runs on the same data can produce different models with no clear explanation. In regulated or long-lived systems, this is unacceptable.
Reproducibility Starts Before AutoML Runs
Before any AutoML framework is invoked, the following must already be fixed:
- Dataset version
- Feature definitions
- Train-validation-test splits
- Evaluation metrics
- Random seeds
AutoML should operate inside these boundaries, not redefine them.
Controlling Randomness Explicitly
Most AutoML frameworks expose controls for randomness. These should always be set deliberately.
Examples include:
- Global random seeds
- Deterministic execution flags
- Fixed cross-validation folds
- Bounded search spaces
The goal is not to eliminate randomness entirely, but to make it traceable and repeatable.
Logging Is Not Optional
Every AutoML run should produce a complete record of:
- Model configuration
- Hyperparameters
- Preprocessing steps
- Evaluation metrics
- Training duration
- Data versions
If a result cannot be reconstructed from logs, it should not be trusted.
Treat AutoML Outputs as Candidates, Not Decisions
AutoML should propose models, not select them blindly.
In disciplined workflows:
- AutoML outputs are reviewed
- Top candidates are retrained manually
- Results are re-evaluated using fixed pipelines
- Only then are models promoted
This step is critical. It converts AutoML from an autonomous decision-maker into a structured assistant.
A Practical Pattern That Works
A pattern commonly used in production systems:
- Use AutoML to explore broadly
- Identify a small set of promising configurations
- Rebuild those models explicitly in code
- Validate behavior across multiple runs
- Promote only reproducible configurations
This preserves both speed and control.
Why This Step Protects the System
AutoML increases the rate of change in a system. Reproducibility slows change down just enough to make it safe.
This balance ensures that:
- Improvements are real
- Failures are explainable
- Rollbacks are possible
- Audits are survivable
Transition to the Next Step
Once AutoML is constrained and reproducible, the next challenge is knowing when to stop.
Not every improvement is worth operational complexity.
Step 25: Knowing When AutoML Adds Value — and When It Does Not
AutoML can accelerate progress, but acceleration is not always desirable.
In production systems, the question is not whether AutoML can improve performance. The question is whether it improves the system as a whole.
This step focuses on recognizing the boundary between useful automation and unnecessary complexity.
When AutoML Adds Genuine Value
AutoML tends to be most effective when:
- The problem is well-defined
- Data quality is stable
- Evaluation metrics are trusted
- Multiple model families are plausible
- Iteration cost is high
In these cases, AutoML reduces manual effort while preserving outcome quality.
When AutoML Adds Risk Instead
AutoML often adds risk when:
- The dataset is small or unstable
- Metrics are poorly aligned with business goals
- Interpretability is mandatory
- Data leakage risks are high
- Governance requirements are strict
In these scenarios, AutoML may produce improvements that are fragile, misleading, or unacceptable in production.
A Signal-Based Decision Framework
Rather than defaulting to AutoML, mature teams watch for signals:
- Plateaued performance despite sound modeling
- High experimentation cost relative to expected gains
- Well-understood feature behavior from diagnostics
- Clear baselines already in place
When these signals align, AutoML is likely to help.
The Cost of Over-Automation
Overuse of AutoML can lead to:
- Loss of model intuition
- Increased debugging complexity
- Difficulty explaining decisions
- Fragile retraining pipelines
These costs compound over time and often outweigh marginal performance gains.
Why Human Judgment Remains Central
AutoML explores options. Humans decide direction.
Even in highly automated systems, humans must still:
- Define success
- Set constraints
- Approve trade-offs
- Accept responsibility for outcomes
AutoML does not change accountability. It only changes velocity.
Why This Step Completes the AutoML Story
AutoML is neither a silver bullet nor a threat. It is a tool whose value depends entirely on context.
Used deliberately, it accelerates learning without undermining control. Used indiscriminately, it amplifies uncertainty.
This step ensures AutoML is applied with intent, not impulse.
Transition to the Closing Section
With AutoML properly contextualized, it is time to step back and assess what scalable experimentation really means in production systems.
Closing Thoughts for Part 5
AutoML is often framed as a shortcut. In mature data science systems, it is something very different.
When used responsibly, AutoML becomes a way to scale experimentation without scaling risk. It reduces repetition, enforces consistency, and allows teams to explore ideas more efficiently while preserving the discipline established earlier in the pipeline. What it does not do is replace judgment, ownership, or accountability.
By the end of this part, AutoML should no longer feel like a black box or a threat to good practice. It should feel like a controlled accelerator layered on top of sound engineering, activated only when the system is ready for it.
This perspective matters. Many production failures attributed to “AutoML limitations” are actually failures of process, not tooling. When foundations are strong and constraints are clear, AutoML amplifies good decisions rather than obscuring them.
If this way of thinking reflects how you approach experimentation and model governance, consider clapping to signal that the perspective was useful, leaving a comment to share how you have used (or avoided) AutoML in real systems, or following the series as it moves into its final stage. Sharing the article with others working on production ML systems also helps extend the discussion beyond a single post. Thanks !!!
Transition to Part 6
With scalable experimentation in place, the remaining challenge is unstructured data.
In Part 6, we will move beyond tabular systems and explore deep learning and NLP frameworks, focusing on how modern models handle text and language while still fitting into governed, production-grade pipelines.
Essential Python Libraries for Data Science was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.