
Essential Python Libraries for Data Science
Part 4: Gradient Boosting in Production

If you look closely at real-world tabular machine learning systems, a clear pattern emerges. Across industries, datasets, and problem domains, the same class of models keeps appearing in production environments.
It is not deep neural networks. It is not AutoML platforms. It is gradient boosting.
This dominance is not accidental. Gradient boosting frameworks such as XGBoost, LightGBM, and CatBoost consistently deliver strong performance on structured data while retaining a level of control that production systems demand. They sit at a pragmatic intersection of expressiveness, stability, and operational feasibility.
The need for these models usually appears at a specific moment in a system’s evolution.
Linear and generalized linear models are honest. They expose their assumptions, behave predictably, and fail in ways that are easy to understand. That is precisely why we started with them. In Parts 1 ( Part 1, Part 2, part 3 ) through 3, we focused on building strong foundations, validating data behavior, and establishing disciplined baselines using classical machine learning.
But real data rarely stays linear for long.
As datasets grow and feature interactions become more important, performance plateaus even when data quality improves. At that point, adding more features or tuning linear models yields diminishing returns. The structure in the data is no longer captured by linear boundaries alone.
This is where gradient boosting becomes relevant. Not as a shortcut, and not as a replacement for careful process, but as a controlled step forward when additional expressive power is justified by evidence.
This part continues directly from the same notebook and workflow established in Part 1, Part 2, and Part 3. No data is reloaded. No assumptions are reset. The baseline models, evaluation metrics, and diagnostic insights already established now serve as reference points for comparison.
The focus of this part is not on winning benchmarks or maximizing scores. It is on understanding why gradient boosting works so well for tabular data, how these models differ from one another, and what changes when they are introduced into a production-oriented pipeline.
We will examine how boosting frameworks handle nonlinearities and feature interactions, how they should be evaluated relative to classical baselines, and what additional considerations arise around tuning, explainability, and governance.
By the end of this part, gradient boosting will no longer feel like a black box upgrade. It will feel like a deliberate, justified extension of the system we have already built.
What Part 4 Will Cover
This part focuses on gradient boosting as it is actually used in production tabular machine learning systems, not as a leaderboard trick or a parameter-tuning exercise.
We will build directly on the baselines, pipelines, and evaluation framework established in Part 3, using them as reference points rather than discarding them.
Specifically, this part will cover:
- Why gradient boosting works so well for tabular data
Understanding the inductive bias of boosting models and why they capture structure that linear models cannot. - Comparing boosting frameworks in practice
XGBoost, LightGBM, and CatBoost are often discussed together, but they make different trade-offs around speed, memory, categorical handling, and stability. - Introducing boosting models into an existing pipeline
How boosting fits into the same scikit-learn–style workflow without breaking reproducibility or evaluation discipline. - Tuning with intent, not brute force
Which hyperparameters actually matter, how to reason about them, and when tuning stops being productive. - Production considerations
Latency, explainability, monitoring, and governance challenges that emerge once models become more powerful.
Each step will extend the same end-to-end notebook, using the same dataset, the same splits, and the same evaluation metrics. Improvements will be measured relative to the classical baselines, not in isolation.
The goal is not to make models more complex. The goal is to make them meaningfully better, without sacrificing control.
Transition to the First Technical Step
Before training any boosting model, it is important to understand what changes conceptually when we move beyond linear decision boundaries.
That is where we will begin.
Step 16: Why Gradient Boosting Works for Tabular Data
Before introducing any boosting framework or writing a single line of training code, it is worth understanding why gradient boosting performs so well on structured, tabular data.
This is not about mathematical elegance. It is about inductive bias and how models interact with real-world datasets.
The Limits of Linear Models
Linear and generalized linear models assume that relationships between features and outcomes can be expressed as weighted sums. Even with interaction terms, this assumption remains restrictive.
In practice, tabular datasets often contain:
- Nonlinear thresholds
- Conditional interactions between features
- Local patterns that apply only to subsets of data
- Mixed feature importance across regions of the input space
Linear models struggle to capture this structure without extensive manual feature engineering.
Decision Trees as Building Blocks
Decision trees address many of these limitations. They naturally model:
- Nonlinear boundaries
- Feature interactions
- Conditional logic
- Region-specific behavior
However, single trees are unstable. Small changes in data can lead to very different trees, and deep trees tend to overfit.
This instability makes standalone decision trees poor production models.
Boosting: Turning Weak Learners into Strong Models
Gradient boosting solves this problem by combining many simple trees, each of which focuses on correcting the errors of the previous ones.
Instead of learning the full structure at once, boosting:
- Starts with a simple model
- Iteratively adds trees that model residual errors
- Gradually refines predictions
- Controls complexity through learning rate and tree depth
This process allows the model to capture complex structure while remaining regularized.
Why Boosting Fits Tabular Data So Well
Tabular data tends to reward models that:
- Handle heterogeneous feature scales
- Capture conditional interactions
- Adapt to local patterns
- Work well with limited feature engineering
Gradient boosting excels in these conditions. It does not require strict distributional assumptions and is resilient to many quirks of real-world data.
This is why boosting frameworks consistently outperform linear models and many deep learning approaches on structured datasets.
The Cost of Expressiveness
More expressive models introduce new challenges:
- Increased risk of overfitting
- Greater sensitivity to hyperparameters
- Higher computational cost
- Reduced interpretability
These trade-offs are manageable, but only if they are acknowledged and handled deliberately.
This is why boosting should be introduced after baselines, diagnostics, and evaluation discipline are in place.
Why This Step Matters Before Training
Understanding why boosting works changes how models are trained, tuned, and evaluated. It prevents blind experimentation and encourages intentional design.
In production systems, this mindset is often the difference between sustainable improvement and fragile complexity.
Transition to the Next Step
With the conceptual foundation in place, we can now introduce gradient boosting models into the existing pipeline and evaluate them relative to classical baselines.
We will start with the most widely used framework in production systems.
Step 17: Introducing XGBoost — A Production-First Boosting Framework
When teams first adopt gradient boosting for tabular data, XGBoost is often the entry point. Not because it is the newest framework, but because it established the practical template that many others later refined.
XGBoost did not become popular by accident. It solved several problems that appeared when boosting models moved from research into production systems.
Why XGBoost Became the Default
XGBoost formalized gradient boosting as a regularized, efficient, and scalable system, rather than a theoretical algorithm.
Key characteristics that made it production-ready include:
- Explicit regularization to control overfitting
- Efficient tree construction optimized for tabular data
- Robust handling of missing values
- Deterministic behavior when configured correctly
- Compatibility with scikit-learn workflows
Most importantly, XGBoost treats model complexity as something to be managed, not hidden.
How XGBoost Fits into Our Existing Pipeline
One of the reasons XGBoost integrates well into mature workflows is that it does not require a redesign of the pipeline.
We already have:
- A normalized, validated dataset
- Stable train-test splits
- Baseline evaluation metrics
- A reproducible modeling structure
XGBoost simply becomes another estimator in the same framework, allowing fair comparison rather than isolated experimentation.
Importing and Initializing XGBoost
from xgboost import XGBClassifier
At this stage, we intentionally avoid tuning. The goal is not to maximize performance, but to establish a controlled reference model.
xgb_model = XGBClassifier(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
subsample=0.8,
colsample_bytree=0.8,
random_state=42,
eval_metric="logloss"
)
These parameters reflect conservative defaults:
- Shallow trees to control complexity
- Moderate learning rate
- Subsampling to improve generalization
This mirrors how XGBoost is often introduced in real systems.
Training the Model
xgb_model.fit(X_train, y_train)
Training at this stage should feel familiar. That is intentional. Complexity is being added incrementally, not abruptly.
Evaluating Against Established Baselines
from sklearn.metrics import accuracy_score, roc_auc_score
y_pred = xgb_model.predict(X_test)
y_proba = xgb_model.predict_proba(X_test)[:, 1]
accuracy = accuracy_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_proba)
accuracy, roc_auc
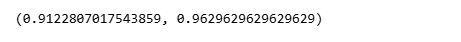
These metrics are interpreted relative to:
- The logistic regression baseline
- Any tree-based baselines introduced earlier
Improvement matters, but consistency and stability matter more.
What to Look For in Early Results
At this stage, we are not chasing marginal gains. We are observing behavior:
- Does performance improve meaningfully over linear models?
- Are gains consistent across metrics?
- Does the model appear stable across runs?
If improvements are small or erratic, that is a signal — not a failure.
Why We Start with Conservative Defaults
Many teams make the mistake of aggressively tuning boosting models before understanding their baseline behavior.
Starting conservatively allows us to:
- Establish trust in the model
- Detect overfitting early
- Preserve interpretability
- Maintain reproducibility
Only once these conditions are satisfied does tuning make sense.
Transition to the Next Step
XGBoost is powerful, but it is not the only boosting framework used in production. Different systems make different trade-offs.
Before tuning further, it is important to understand how other frameworks differ conceptually and operationally.
Step 18: LightGBM and CatBoost — Speed, Scale, and Categorical Awareness
Once gradient boosting is introduced into a system, the next question is rarely whether to use it. The real question becomes which boosting framework fits the constraints of the system.
XGBoost, LightGBM, and CatBoost all implement gradient boosting, but they make different trade-offs. Understanding those differences is essential when models move beyond experimentation and into production.
LightGBM: Optimized for Speed and Scale
LightGBM was designed with a specific goal: handle large datasets efficiently.
Its core innovation is a histogram-based tree construction approach combined with a leaf-wise growth strategy. In practice, this means:
- Faster training on large datasets
- Lower memory usage
- Efficient handling of high-dimensional data
These advantages make LightGBM attractive in systems where:
- Training time matters
- Datasets are large
- Feature counts are high
- Frequent retraining is required
However, leaf-wise growth can also increase the risk of overfitting if depth is not controlled carefully. This places greater responsibility on tuning discipline and monitoring.
CatBoost: Designed for Categorical Features and Stability
CatBoost addresses a different set of production problems.
Many real-world datasets contain categorical variables that are difficult to encode cleanly without leakage or loss of information. CatBoost was built to handle this scenario explicitly.
Key characteristics include:
- Native handling of categorical features
- Built-in strategies to prevent target leakage
- Stable performance with minimal preprocessing
This makes CatBoost particularly valuable in domains such as:
- Finance
- Marketing
- Customer behavior modeling
- Risk and fraud systems
CatBoost often performs well with less tuning, which can be an advantage in regulated or resource-constrained environments.
Comparing the Frameworks Pragmatically
There is no universally best boosting framework. The choice depends on constraints rather than scores.

This comparison is not about preference. It is about alignment with system needs.
Why We Don’t Switch Frameworks Lightly
Changing boosting frameworks introduces:
- Different default behaviors
- Different tuning sensitivities
- Different explainability tooling
- Different monitoring considerations
In mature systems, framework changes are deliberate architectural decisions, not experimental swaps.
Transition to the Next Step
Now that we understand the trade-offs between boosting frameworks, the next challenge is tuning them responsibly.
Poor tuning can erase the advantages of even the best model.
Step 19: Tuning Gradient Boosting Models Without Losing Control
Once gradient boosting models are introduced, tuning becomes inevitable. This is also the point where many otherwise solid systems begin to drift into fragility.
The goal of tuning is not to squeeze out every last decimal point of performance. The goal is to improve models without sacrificing stability, interpretability, or reproducibility.
Why Blind Tuning Fails in Production
Gradient boosting exposes many hyperparameters, but not all of them deserve equal attention.
Common failure patterns include:
- Exhaustive grid searches without clear hypotheses
- Overfitting to validation sets
- Models that perform well once but behave inconsistently across retraining cycles
- Configurations that are difficult to explain or reproduce
In production systems, these failures are more damaging than slightly suboptimal performance.
A Small Set of Parameters That Actually Matter
In practice, most performance gains come from a limited number of controls:
- n_estimators
Controls how many trees are added. More trees increase capacity but also training time and overfitting risk. - max_depth (or equivalent)
Governs model complexity. Shallow trees generalize better and are easier to reason about. - learning_rate
Controls how aggressively the model learns. Lower rates improve stability but require more trees. - subsample / colsample_bytree
Introduce randomness that improves generalization.
Everything else tends to have diminishing returns unless the dataset is unusually complex.
Tuning as Controlled Experimentation
Responsible tuning follows a simple pattern:
- Change one dimension at a time
- Compare against a fixed baseline
- Observe behavior across multiple runs
- Stop when gains become marginal
This approach favors understanding over optimization.
Conservative Tuning Example (XGBoost)
xgb_tuned = XGBClassifier(
n_estimators=200,
max_depth=3,
learning_rate=0.05,
subsample=0.8,
colsample_bytree=0.8,
random_state=42,
eval_metric="logloss"
)
xgb_tuned.fit(X_train, y_train)

This configuration increases capacity gradually while maintaining regularization.
Evaluating Stability, Not Just Performance
y_pred = xgb_tuned.predict(X_test)
y_proba = xgb_tuned.predict_proba(X_test)[:, 1]
accuracy_score(y_test, y_pred), roc_auc_score(y_test, y_proba)
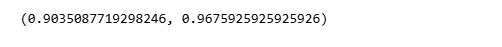
Performance improvements should be:
- Consistent
- Explainable
- Repeatable
If gains fluctuate significantly, tuning has likely gone too far.
When to Stop Tuning
Tuning should stop when:
- Performance improvements flatten
- Variance across runs increases
- Interpretability degrades
- Retraining time becomes unacceptable
These are signals that the system is approaching its optimal complexity.
Why This Step Protects the System
In production, models live longer than experiments. Tuning decisions persist through retraining cycles, audits, and incident reviews.
This step enforces intentional complexity, ensuring that performance gains do not undermine system trust.
Transition to the Next Step
Once a boosting model is tuned responsibly, the next challenge is explaining and governing it.
More powerful models demand stronger transparency.
Step 20: Explainability, Monitoring, and Governance for Boosting Models
As models become more expressive, the cost of misunderstanding them increases.
Gradient boosting delivers strong performance on tabular data, but that performance comes with added responsibility. In production systems, it is not enough for a model to be accurate. It must also be explainable, monitorable, and governable.
This step focuses on what changes operationally once boosting models enter the system.
Explainability Is No Longer Optional
Boosting models capture nonlinear interactions and conditional behavior that linear models cannot. That power makes them harder to reason about intuitively.
In real systems, explainability serves several purposes:
- Building trust with business stakeholders
- Supporting regulatory and audit requirements
- Debugging unexpected behavior
- Understanding model failure modes
Feature importance becomes a baseline requirement, not a luxury.
Practical Explainability Techniques
At minimum, teams should be able to answer:
- Which features matter most overall?
- How do features influence predictions locally?
- Are there features dominating decisions unexpectedly?
For boosting models, common tools include:
- Built-in feature importance (gain, weight, cover)
- Permutation importance
- SHAP-based explanations for local and global behavior
The goal is not to fully interpret every interaction, but to ensure that the model’s behavior aligns with domain understanding.
Monitoring Goes Beyond Performance Metrics
Once deployed, boosting models must be monitored continuously.
Accuracy and AUC alone are insufficient. Production monitoring should include:
- Input data drift
- Feature distribution shifts
- Prediction stability
- Confidence calibration
- Performance decay over time
Boosting models are sensitive to distributional changes. Without monitoring, degradation often goes unnoticed until business impact is visible.
Model Drift Is a System Problem, Not a Model Problem
When performance degrades, the cause is rarely the algorithm itself. It is usually:
- Changes in upstream data sources
- Shifts in user or customer behavior
- Delayed feedback loops
- Broken assumptions carried forward from training
Treating drift as a modeling failure leads to repeated retraining without addressing root causes.
Governance and Reproducibility
In mature environments, governance is what separates experimentation from production.
For boosting models, governance typically includes:
- Versioned training data
- Logged hyperparameters
- Reproducible training runs
- Clear approval and rollback processes
- Documented evaluation results
These practices ensure that improvements can be explained, repeated, and reversed if necessary.
Why This Step Completes the Boosting Story
Gradient boosting is often presented as a performance upgrade. In reality, it is a system upgrade.
It changes:
- How models are evaluated
- How failures are investigated
- How retraining is managed
- How accountability is enforced
Ignoring these shifts is what causes many high-performing models to fail in production.
Closing Thoughts for Part 4
Gradient boosting dominates tabular machine learning not because it is complex, but because it balances expressive power with operational control when used correctly. It extends classical models without abandoning the discipline that production systems require.
When introduced deliberately, tuned conservatively, and governed responsibly, boosting models become stable, long-lived components of real systems rather than fragile experiments optimized for short-term gains. This is what allows teams to move beyond linear assumptions without sacrificing trust, reproducibility, or explainability.
This part completes the transition from classical machine learning to production-grade nonlinear modeling, while preserving the pipeline discipline established throughout the series.
If this perspective aligns with how you build or review machine learning systems, consider clapping to signal value, leaving a comment to share how you approach boosting models in production, or following the series to continue into the next phase. Sharing the article with others working on tabular ML systems also helps broaden the discussion beyond a single post. Thanks !!!
Transition to Part 5
With strong, governed boosting models in place, the next challenge is scale.
In Part 5, we will explore AutoML and scalable experimentation, focusing on how modern tools accelerate iteration without replacing judgment or weakening control over data, models, and decisions.
Essential Python Libraries for Data Science was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.