
Customer Impersonation Detection using LLM
Detecting Customer Fraud in Merchant Space
Q1. What was the business usecase?
In merchant space there are different types of fraud that can happen like:
- Fraudsters impersonating the platform (e.g., pretending to be support)
- Fraudsters contacting merchants via phone/SMS.
- Social engineering attempts(revealing confidential info) to steal money, OTPs, credentials
- Suspicious phone numbers used in impersonation scams
Q2. What type of datasets did you use for this model ?
We used structured dataset from redshift.
a) raw_cs_contact_reports
case_id | merchant_id | customer_id | channel_type | transcript_text |contact_start | contact_end | language_code | agent_id | case_status | region
Size: ~300M+ per year ( ~6M row per week)
b) phone_number_extraction_log
case_id | extracted phone_number | extraction_timestamp | merchant_id
Size: 75 M rows per year
- *20–30% of transcript contain phone number.
Q3. Give me an overall flow diagram of the approach you have used to solve the problem.
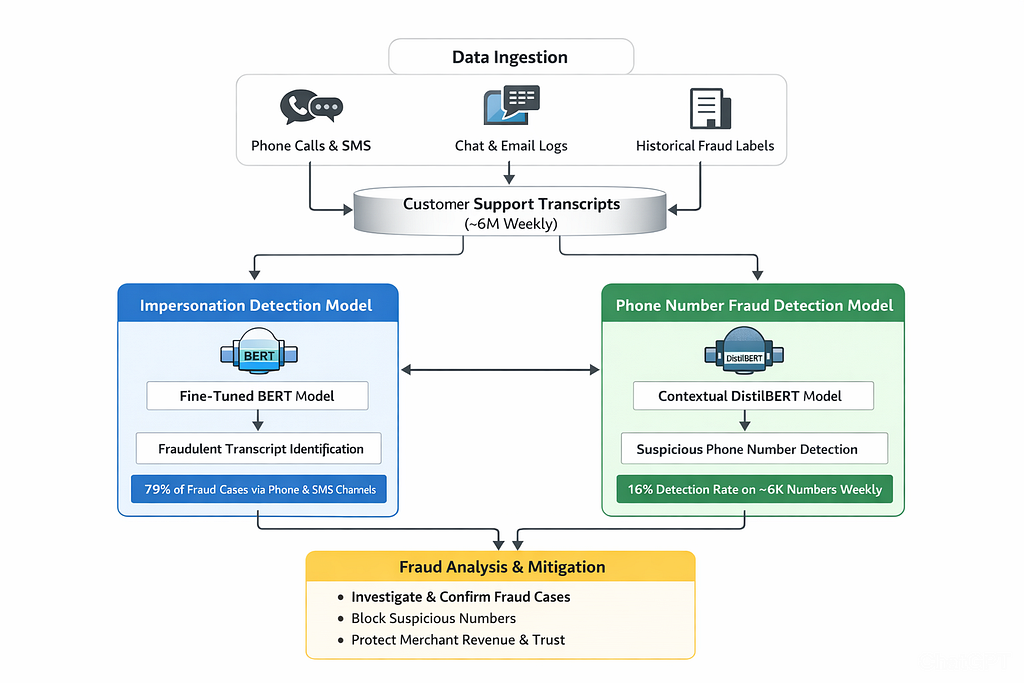
Q4. What does output of Impersonation Detection Model and Phone Number Detection Model look like?
a) Impersonation Model Detection Output:

b) Phone Number Fraud Detection Model

Q5. Discuss the model development lifecycle for Impersonation Detection model.
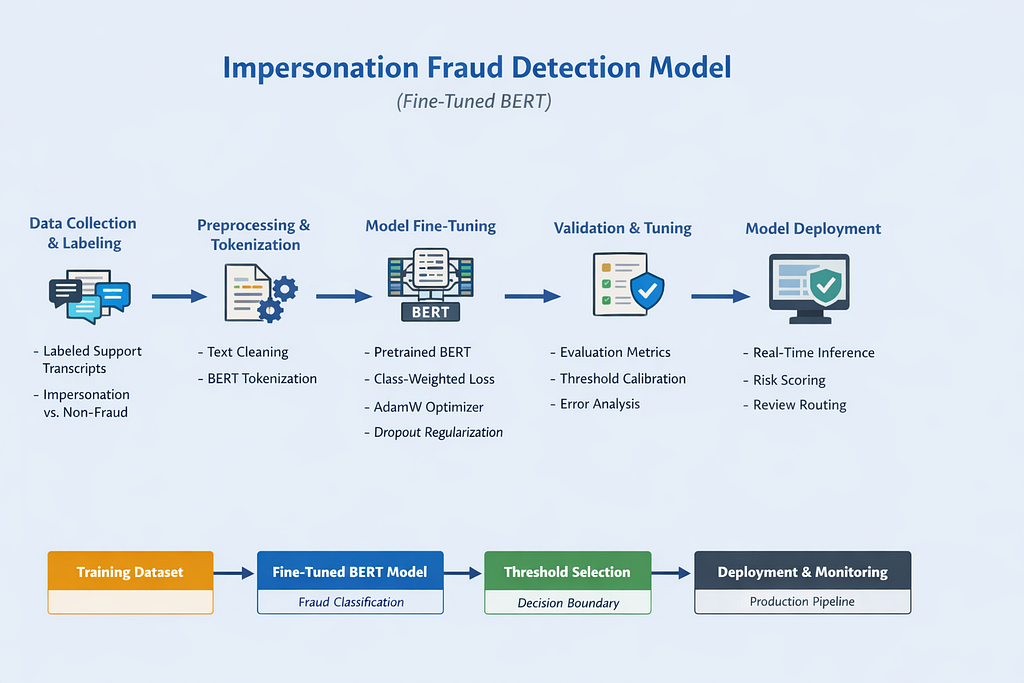
a) Data Collection and labeling
- Extracted historical customer service transcripts (chat, phone, SMS) from internal data lake.
- Merged transcript data with confirmed fraud investigation outcomes to create ground-truth labels.
- Defined binary classification labels: Impersonation Fraud (1) and Non-Fraud (0).
- Removed PII and performed data anonymization to ensure compliance.
- Cleaned and deduplicated transcripts to avoid data leakage(Data leakage is when your model accidentally gets access to information during training that it wouldn’t have at prediction time. This causes the model to perform unrealistically well during training or validation, but fail in real-world scenarios).
- Balanced the dataset to handle class imbalance (fraud vs non-fraud).
- Split labeled data into train(70), validation(15), and test(15) datasets for model development.
**For training we have used 1M labelled records(20k million frauds)from historical data.
Tech Stack Used:
AWS S3, AWS Redshift, AWS Sagemaker
b) Processing & Tokenization (Impersonation Fraud Detection Model)
- Text Cleaning: Removed HTML tags, special characters, system-generated templates, and irrelevant metadata from transcripts.
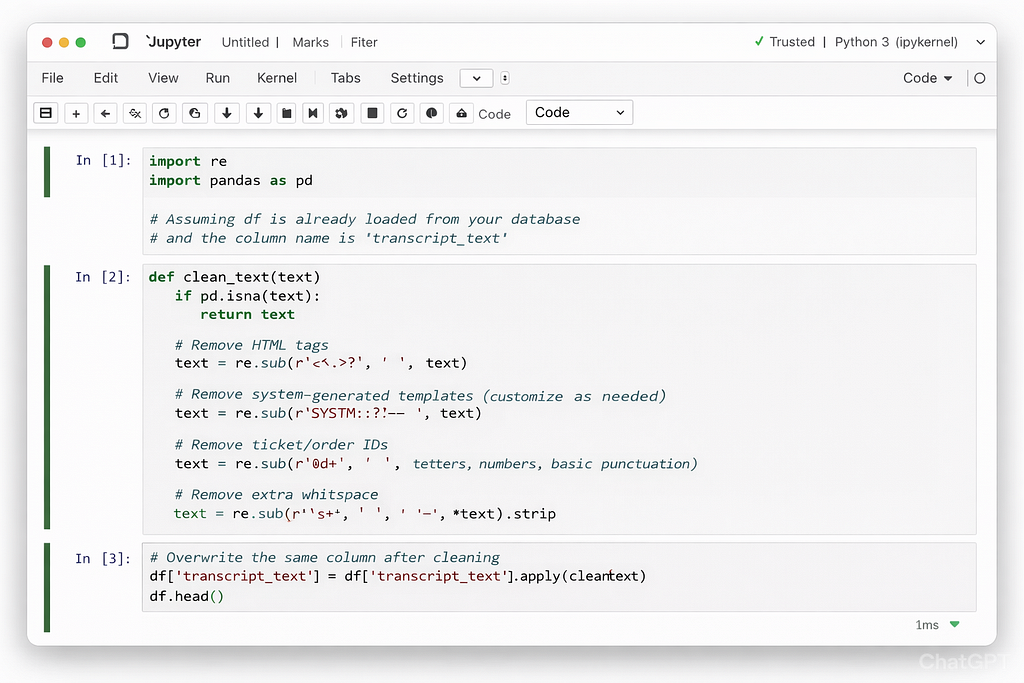
- PII Masking: Replaced sensitive entities (phone numbers, emails, order IDs) with placeholder tokens (e.g., <PHONE>, <EMAIL>).

- Normalization: Converted text to lowercase, standardized abbreviations, and corrected common misspellings.
- Conversation Structuring: Preserved speaker turns (Agent vs Customer) to maintain contextual flow.
- Handling Long Transcripts: chunked transcripts to fit model max token length and then used max aggregation to identify the fradulent one.(e.g., 512 tokens for BERT).

- Tokenization using BERT Tokenizer: Applied WordPiece tokenization to convert text into input IDs and attention masks.
- Padding & Attention Masks: Added padding for uniform sequence length and generated attention masks for model training.
( BERT requires: Fixed sequence length per batch (e.g., 512) and Information about which tokens are real vs padding)
- Encoded Labels: Converted fraud/non-fraud labels into numerical format for supervised learning.
import torch
labels = torch.tensor(df[“label”].astype(int).values)
c) Model Fine-Tuning(IFD)
- Loaded pre-trained BERT (bert-base-uncased) with a binary classification head (num_labels=2).
- Prepared training inputs: input_ids, attention_mask, and encoded fraud labels (0/1).
- Split data into train, validation, and test sets.
- Defined CrossEntropy Loss for binary classification.
- Configured hyperparameters: learning rate (e.g., 2e-5), batch size (16/32), epochs (3–5), weight decay.
- Used AdamW optimizer for stable fine-tuning.
- Performed forward pass → computed loss → backpropagation → weight updates.
- Evaluated on validation set after each epoch (Precision, Recall, F1, AUC).
- Monitored overfitting and tuned threshold for fraud detection.
- Saved fine-tuned model and tokenizer for production inference.
d) Tuning
- Fed input_ids + attention_mask + labels into BERT
- Performed forward pass to get logits (raw predictions)
- Computed CrossEntropy loss between predicted logits and true labels
- Performed backpropagation to calculate gradients
- Updated model weights using AdamW optimizer
- Repeated for all batches in the dataset
- Completed multiple epochs (e.g., 3–5 passes over data)
e) Validation
- Ran model in eval() mode
- Disabled gradient computation (torch.no_grad())
- Passed validation input_ids + attention_mask
- Generated predictions
- Calculated performance metrics:Accuracy, Precision, Recall, F1 Score ROC AUC.
- Compared validation loss vs training loss
- Checked for overfitting
- Adjusted hyperparameters if needed
e) Model Deployment
e) Model Deployment — Simple Steps
- Saved the fine-tuned BERT model and tokenizer.
- Built an inference pipeline (cleaning → tokenization → chunking → prediction → aggregation).
- Exposed the model through an API endpoint for real-time scoring.
- Integrated the endpoint with the fraud detection system / case management system.
- Set a fraud risk threshold to automatically flag suspicious transcripts.
- Enabled logging and monitoring for model performance and errors.
- Set up periodic retraining using newly labeled fraud data.
Q6. Discuss model development lifecycle for Phone Number Fraud Detection model.
Problem Definition
- Objective: Identify fraudulent or impersonation-linked phone numbers from customer interactions.
- Business goal: Reduce fraud exposure, protect merchants, and automatically flag high-risk phone numbers.
Data Collection
- Extracted phone numbers from customer support transcripts and call logs.
- Mapped numbers to known fraud cases for labeling.
- Collected contextual text around each number (±N tokens) for NLP input.
Data Cleaning & Labeling
- Standardized phone number format (removed special characters, unified country codes).
- Removed duplicates and invalid entries.
- Labeled: 1 → Fraudulent number, 0 → Legitimate number
Tokenization & Encoding
- Used DistilBERT tokenizer (WordPiece) on the surrounding context text.
- Added padding and attention masks for uniform input lengths.
- Encoded labels into numerical format (0/1) for supervised learning.
Feature Engineering (Optional)
- Contextual embeddings from DistilBERT.
- Aggregated numeric features:
Number of associated merchants
Historical fraud flags
Prior rule-engine signals
Country code features
Model Training & Validation
- Fine-tuned DistilBERT on labeled phone number context.
- Trained with:
Input: tokenized text, attention masks, numeric features
Output: probability of fraud
- Validation metrics:
- Precision, Recall, F1-score, ROC-AUC
- Threshold tuning for optimal fraud flagging.
Model Deployment
- Saved fine-tuned DistilBERT model and tokenizer.
- Built inference pipeline for incoming phone numbers:
- Preprocessing → Tokenization → DistilBERT → Probability → Risk score → Flag.
- Integrated with fraud monitoring system for real-time or batch scoring.
Monitoring & Retraining
- Monitored performance over time (drift detection, fraud detection rate).
- Periodically retrained with new labeled numbers.
- Updated thresholds or rules based on evolving fraud patterns.
Q7. How did you use the two models to solve for the business use case?
- Generated conversation-level fraud probability using a fine-tuned BERT model and phone-number risk score using a contextual DistilBERT model.
- Aligned both predictions at the case/transcript level to create a unified fraud-risk feature table.
- Applied rule-based fusion logic where high transcript risk or highly suspicious phone numbers directly triggered fraud classification.
- Introduced a manual-review tier for medium-risk signals to balance fraud recall with investigation workload.
- Used the final fused decision to drive mitigation actions such as fraud investigation, suspicious number blocking, and merchant risk protection.
Q8. How did you handle class imbalance for Impersonation Usecase ?
Some of the ways to deal with class imbalance would be:
a) Oversampling
b) Evaluation metrics focussed on Imbalanced classess.
c) Threshold Tuning
d) Weighted Loss Function
Q9. Could you think of another approach for this one?
I could think of GNNs and semi supervised anomaly detection techniques.
Q10. How did you handle the scale of ~6M weekly transcripts efficiently?
- Used AWS SageMaker endpoints to host fine-tuned BERT and DistilBERT models for inference.
- Parallelized preprocessing (cleaning, PII masking, tokenization) using batch jobs / SageMaker Processing Jobs.
- Chunked long transcripts into 512-token segments for efficient batch inference.
- Leveraged GPU-backed instances for high-throughput scoring of transcripts.
Customer Impersonation Detection using LLM was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.