
Building Real-Time Semantic Code Search With Tree-sitter and Vector Embeddings

Index your codebase for semantic search with incremental updates — only reprocess what’s changed, powered by native Tree-sitter parsing.
Every developer has experienced the frustration: you know some code exists in your repository that does exactly what you need, but you can’t remember where. Grep works for exact matches, but what if you want to find code that’s semantically similar to what you’re looking for?
Imagine being able to query your codebase like this:
- “Find all functions that handle HTTP authentication”
- “Show me code similar to this error handling pattern”
- “Where is the database connection pooling logic?”
This is where semantic code search shines. By converting code into vector embeddings and storing them in a database, you unlock powerful similarity-based queries that traditional text search can never achieve.
In this article, we’ll build a practical CocoIndex pipeline that:

- Reads code files from your local filesystem
- Splits code into semantic chunks using Tree-sitter parsing
- Generates vector embeddings for each chunk
- Stores everything in Postgres with pgvector for similarity search
- Automatically updates only when source files change
The full source code is available on GitHub .
Setup
- Install Postgres, follow installation guide.
- Install CocoIndex
pip install -U cocoindex
Flow Definition
Let’s break down the key components of this CocoIndex pipeline.
1. Add the Codebase as a Source
We use the LocalFile source to ingest code files. The pipeline includes file patterns for common code extensions (.py, .rs, .toml, .md, .mdx) and excludes directories like node_modules and target.
import os
@cocoindex.flow_def(name="CodeEmbedding")
def code_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
data_scope["files"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path=os.path.join('..', '..'),
included_patterns=["*.py", "*.rs", "*.toml", "*.md", "*.mdx"],
excluded_patterns=[".*", "target", "**/node_modules"]))
code_embeddings = data_scope.add_collector()
flow_builder.add_source will create a table with sub fields (filename, content).
2. Split Code into Semantic Chunks
Unlike naive text splitting, CocoIndex uses Tree-sitter for language-aware chunking. Tree-sitter understands the syntax of dozens of programming languages, ensuring chunks respect function boundaries, class definitions, and other semantic units.
For example, when processing Python code, Tree-sitter recognizes function definitions, class declarations, and module-level statements. This prevents chunks from awkwardly splitting in the middle of a function.
Let’s define a function to extract the extension of a filename while processing each file.
@cocoindex.op.function()
def extract_extension(filename: str) -> str:
"""Extract the extension of a filename."""
return os.path.splitext(filename)[1]
We use the SplitRecursively function to split the file into chunks. SplitRecursively is CocoIndex building block, with native integration with Tree-sitter. You need to pass in the language to the language parameter if you are processing code.
with data_scope["files"].row() as file:
# Extract the extension of the filename.
file["extension"] = file["filename"].transform(extract_extension)
file["chunks"] = file["content"].transform(
cocoindex.functions.SplitRecursively(),
language=file["extension"], chunk_size=1000, chunk_overlap=300)
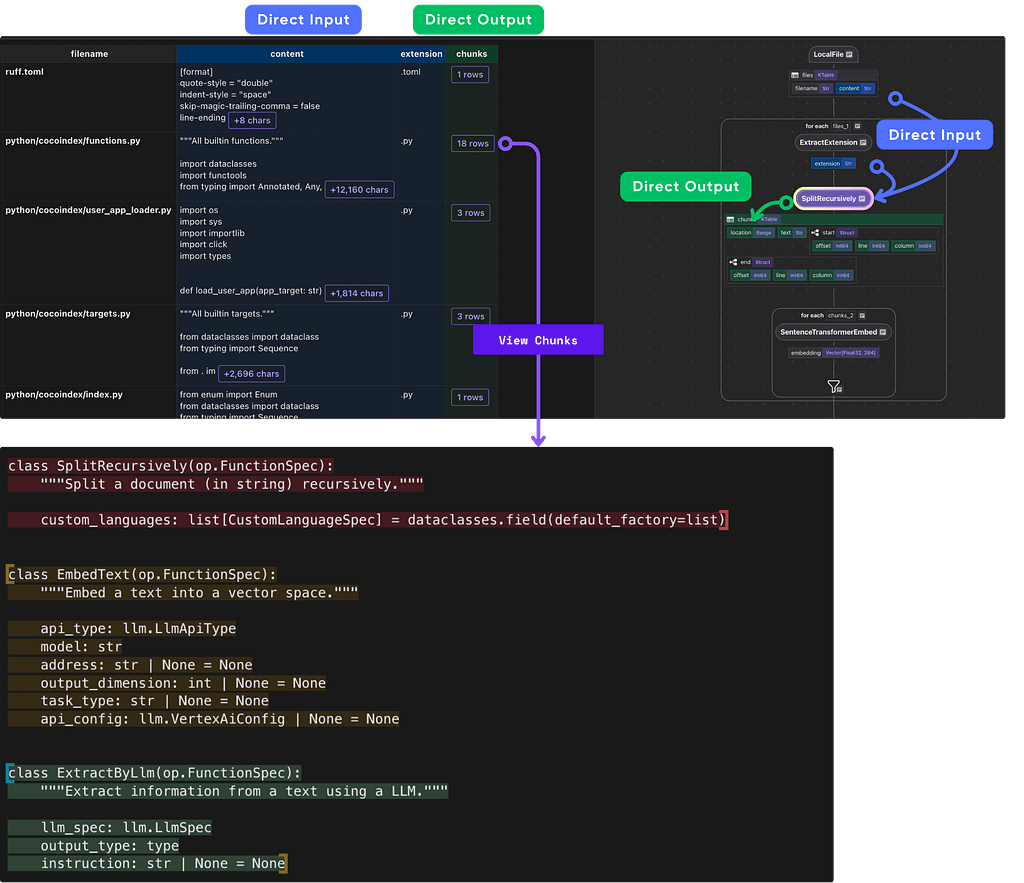
3. Generate Embeddings
We use SentenceTransformers (specifically all-MiniLM-L6-v2) to convert each code chunk into a 384-dimensional vector. The @cocoindex.transform_flow() decorator ensures the same embedding model is used for both indexing and query time.
@cocoindex.transform_flow()
def code_to_embedding(text: cocoindex.DataSlice[str]) -> cocoindex.DataSlice[list[float]]:
return text.transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))
Then for each chunk, we will embed it using the code_to_embedding function, and collect the embeddings to the code_embeddings collector.
with data_scope["files"].row() as file:
with file["chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].call(code_to_embedding)
code_embeddings.collect(filename=file["filename"], location=chunk["location"],
code=chunk["text"], embedding=chunk["embedding"])
4. Store in Postgres with pgvector
The embeddings are stored in Postgres using the pgvector extension for efficient similarity search. CocoIndex handles the schema creation and index management automatically.
code_embeddings.export(
"code_embeddings",
cocoindex.storages.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[cocoindex.VectorIndex("embedding", cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)])
The Power of Incremental Processing
This is where CocoIndex truly shines. Traditional indexing approaches reprocess the entire codebase on every update. With a large codebase of thousands of files, this becomes prohibitively expensive.
CocoIndex’s incremental processing means:
• Only changed files trigger reprocessing
• Unchanged files keep their cached embeddings
• The database receives minimal mutations
• Updates happen in near real-time
For an enterprise with 1% daily code churn, only 1% of files hit the embedding model on each update cycle. The remaining 99% of files never touch the expensive compute path.
Querying the Index
Once your index is built, querying is straightforward. The search function:
1. Converts your natural language query into an embedding using the same model
2. Performs a cosine similarity search against the stored vectors
3. Returns the most relevant code chunks with similarity scores
The query reuses the same embedding computation defined in the indexing flow, ensuring consistency between indexing and retrieval.
def search(pool: ConnectionPool, query: str, top_k: int = 5):
# Get the table name, for the export target in the code_embedding_flow above.
table_name = cocoindex.utils.get_target_storage_default_name(code_embedding_flow, "code_embeddings")
# Evaluate the transform flow defined above with the input query, to get the embedding.
query_vector = code_to_embedding.eval(query)
# Run the query and get the results.
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute(f"""
SELECT filename, code, embedding <=> %s::vector AS distance
FROM {table_name} ORDER BY distance LIMIT %s
""", (query_vector, top_k))
return [
{"filename": row[0], "code": row[1], "score": 1.0 - row[2]}
for row in cur.fetchall()
]
Running the Pipeline
Getting started is simple:
1. Install dependencies: pip install -e .
2. Update the index: cocoindex update main
3. Test queries: python main.py
Once you start the query interface, you can enter natural language queries like “spec” or “flow definition” and receive ranked results with file names, code snippets, and similarity scores.
Supported Languages
CocoIndex’s SplitRecursively function has native Tree-sitter support for all major programming languages including Python, Rust, JavaScript, TypeScript, Go, Java, C, C++, Ruby, and many more. The language is automatically detected from the file extension, so no additional configuration is needed.
Extending Beyond Code
This pattern extends far beyond code repositories:
- Documentation search — Index technical documentation with semantic search capabilities
• Infrastructure-as-code — Enable SRE teams to search Terraform, Kubernetes configs, and deployment scripts
• Config file analysis — Track configuration drift and search for specific patterns across environments
• Multi-repo indexing — Build a unified search across multiple repositories in your organization
Conclusion
Building semantic code search doesn’t have to be complex. With CocoIndex’s incremental processing, Tree-sitter integration, and vector storage, you can create a production-ready code search system in under 100 lines of Python.
The key takeaways:
• Tree-sitter provides language-aware chunking that respects code semantics
• Incremental processing dramatically reduces compute costs for large codebases
• Vector embeddings enable powerful similarity-based retrieval that traditional search cannot match
• The same pipeline pattern works for any text corpus, not just code
Whether you’re building context for AI coding agents, powering an internal code search tool, or enabling automated code review, this architecture provides a solid foundation that scales with your codebase.
Building Real-Time Semantic Code Search With Tree-sitter and Vector Embeddings was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.