
Building an ARC-2 Solver — From Socratic Panels to a Single Oracle
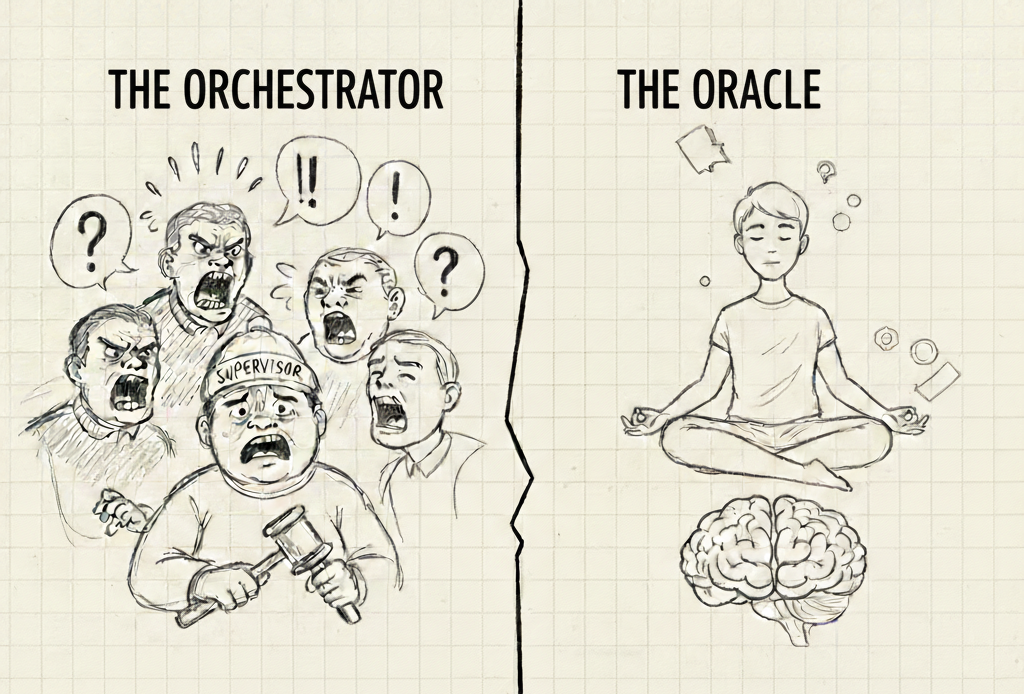
In Part 1 of this series, I explored a multi-agent Socratic architecture to tackle ARC-2. A supervisor agent orchestrated a panel of specialists, each debating hypotheses about object transformations, symmetry, and spatial reasoning.
In Part 2 , I narrowed in on what felt like the real bottleneck: perception.
Frontier models could often reason correctly once the rule was clearly articulated — but they struggled to see the structure in the first place. Images and text turned out to provide orthogonal signals. When visual grounding improved, reasoning followed.
For Part 3, I completed and the results are promising — 50–70%+ on the ARC-2 public evaluation dataset.
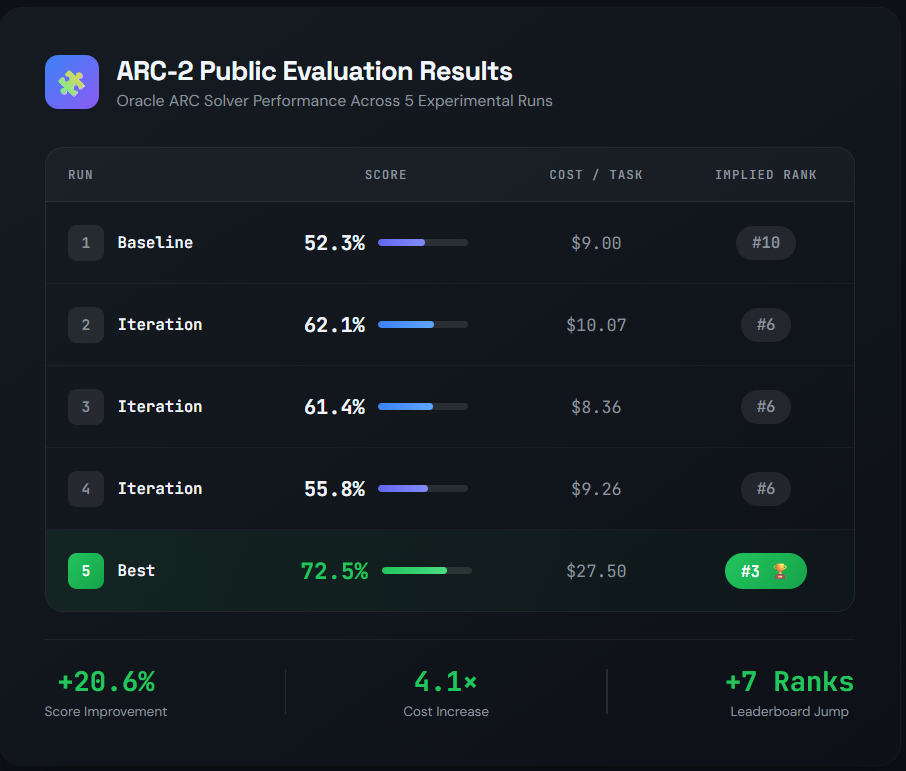
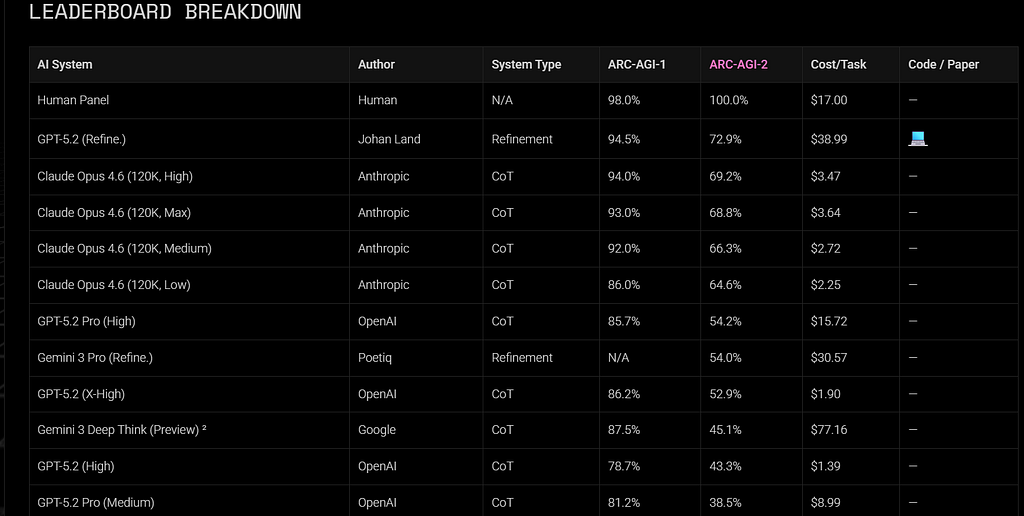
Which compares favorably with the top-10 on the ARC-2 leaderboard.
But the numbers aren’t the most interesting part.
The architecture changed — radically.
I removed the supervisor. I removed the panel. I abandoned structured debate.
Instead, I built a single, tool-augmented Oracle.
Why even bother with ARC-2?
This project has been a meaningful investment — in time, in compute, in LLM usage, and in infrastructure. There were moments where I asked myself whether it was worth it.
ARC-AGI-2 isn’t just another benchmark. It exposes something uncomfortable about modern language models. These systems are trained on incomprehensible amounts of data — billions of tokens — and yet ARC asks them to generalize from two or three examples.
Two or three.
That inversion is what makes ARC so compelling. It strips away memorization and scale advantages and asks a more primitive question:
Can you derive the rule from almost nothing?
That question feels fundamental. Not just for puzzles — but for intelligence itself.
Why the Multi-Agent Model Didn’t Scale
The Socratic model described in Part 1 was intellectually beautiful.
The hypothesis was simple: intelligence emerges from structured disagreement.
Multiple agents. Diverse hypotheses. Supervisor-guided refinement. Iterative dialogue.
It felt principled. Almost philosophical.
But something subtle happened in practice.
If perception was wrong, debate amplified the error.
All panelists shared the same flawed visual grounding. More voices didn’t correct it — they reinforced it.
Token usage ballooned.
Accuracy improved, but not proportionally.
The marginal gains weren’t justifying the cognitive overhead.
ARC-2 isn’t a philosophy seminar. It’s a binary benchmark. Either every cell in the output grid is correct — or you get zero.
At some point I had to admit something uncomfortable: Intelligence wasn’t emerging from argument. It was emerging from better instrumentation.
That realization changed everything. So I changed course.
The Oracle Model
Instead of many shallow thinkers debating, I built one deep thinker with tools and time.
The architecture is a single-agent loop built on LangGraph:
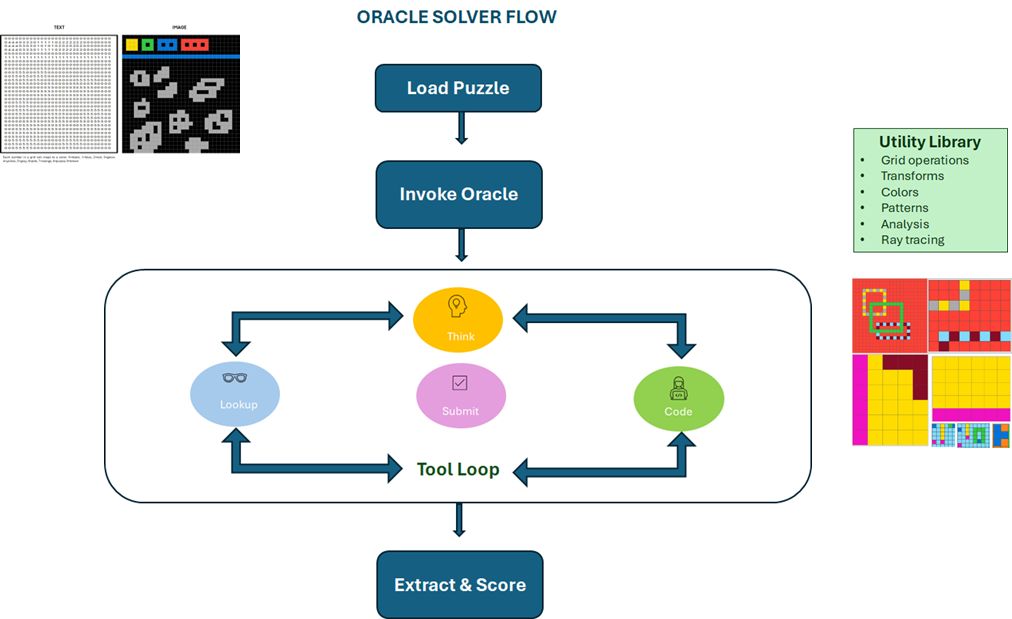
The Oracle receives the puzzle (text, images, or both) and operates inside a constrained tool environment:
- think(reflection) — structured reasoning (free, no execution cost)
- lookup_util() — browse a tested utility library
- run_python(code) — execute analysis (stateless)
- submit_grid(grid) — submit final answer directly
No debate. No orchestration layer. No theatrical disagreement.
Just reflection, experimentation, and verification.
The system feels quieter. And in that quiet, it performs better.
Python as an Analytical Microscope
One design principle became central: Python is an analytical microscope — not a solution generator.
Many ARC transformations are trivial to describe in English:
- “Fill the holes.”
- “Reflect the object.”
- “Recover the hidden region.”
But implementing these robustly in procedural code is surprisingly fragile. Small indexing errors cascade. Edge cases multiply.
So I separated cognition from implementation:
- The LLM reasons visually.
- Python tests hypotheses.
- The final answer is submitted directly as a grid — not generated by code.
This avoids a common ARC failure mode: the model correctly infers the rule but mis-implements it procedurally.
Stateless Execution as Discipline
Every run_python() call is stateless. Nothing persists between executions.
This constraint initially felt limiting. But it forced discipline:
- No hidden mutation.
- No silent state accumulation.
- Every experiment must be explicit.
- Every hypothesis must be re-articulated.
It mirrors scientific experimentation. Every tool call is a clean lab test. If the hypothesis fails, you don’t patch around it. You revise it.
Leaning Into Vision
In Part 2 , I realized perception was the bottleneck.
So in Part 3, I leaned heavily into vision.
The solver supports multiple grid presentation modes:
- text_only
- image_only
- text_and_image
Grids can include:
- Row and column indices
- Visual formatting
- Optional coordinate representations
- An optional grid legend of common ARC object archetypes

This wasn’t just about rendering prettier grids. It was about engineering a perceptual interface.
Orthogonal Signals
Text grids provide exact symbolic information. Images provide spatial and gestalt cues.
Together, they improve grounding in ways that are hard to quantify but easy to observe.
The grid legend primes pattern recognition for:
- Arrows
- Connectors
- Symmetry markers
- Edge alignments
- Tiling structures
It seems minor. It isn’t. ARC is fundamentally visual. Treating it as pure text quietly handicaps the model. Once I accepted that, performance followed.
Encoding ARC Archetypes Into Utilities
Another early lesson: If you let the LLM reinvent connected-component detection every time, it will get it wrong.
So I built a tested utility library: arc_utils.
It contains primitives for:
- Grid transforms (rotate, flip, scale)
- Object detection
- Symmetry detection
- Color analysis
- Pattern detection
- Ray casting
- Region recovery
Instead of improvising procedural logic, the LLM composes verified building blocks. This changed the texture of the reasoning process.
Example: Finding Objects
Consider ARC puzzle 221dfab4.

The objective is to draw a vertical pattern aligned with the yellow on the edge of the grid. But first — because it’s a sparse grid — the solver must identify the objects correctly.
The yellow bars are clearly pattern markers to a human. The green bars bleed into the objects.
Obvious to us. Not obvious to a model.
And implementing object segmentation naïvely requires a surprising amount of code.
In the trace, you can see the solver think, attempt custom code, fail, reflect, and then decide to look up a utility to detect objects robustly.
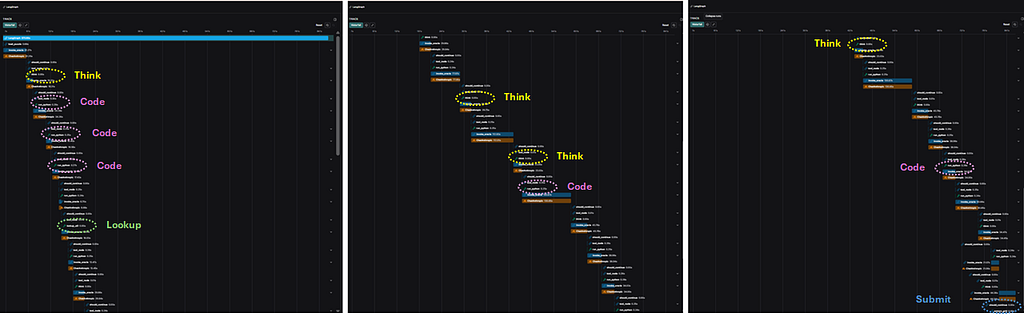
The utility analyzes sparse grids and returns structured object data. It reduces token cost, reduces fragility, and encodes prior structural knowledge.
No guessing. No partial credit. Full falsification before commitment.
Over time, the utility library became a vocabulary of ARC archetypes.
Mandatory Verification
ARC scoring is binary. If even one grid cell is wrong, the score is zero.
So the Oracle must:
- Apply its inferred transformation to all training examples.
- Confirm exact matches.
- Only then submit the test output.
This enforces epistemic humility.
The solver doesn’t “feel confident.” It proves correctness before acting.
That small discipline reduces hallucinated generalizations.
Thinking Time Is Intelligence
One of the most revealing parameters in the system is: MAX_ORACLE_TOOL_CALLS
This caps how many tool calls the LLM can make per puzzle.
Higher cap → more exploration → higher accuracy → higher token cost.
Lower cap → faster submission → lower accuracy.
What surprised me is how cleanly performance tracks with allocated thinking budget.
ARC becomes a benchmark of reasoning depth under constraint.
The solver’s accuracy meaningfully correlates with how much “thinking time” it’s allowed.
That observation shifted how I think about intelligence in these systems.
It’s not just architecture. It’s budget.
Confidence-Gated Multi-Model Strategy
The solver also supports a dual-model setup.
- Primary model attempts first.
- If it voluntarily submits before hitting the tool limit, we accept its answer.
- If it’s forced to submit due to tool exhaustion, we escalate to a secondary model.
Voluntary submission becomes a rough proxy for internal certainty.
This is cost-aware reasoning. Smarter escalation without blindly doubling compute.
Results
Across configurations and models, evaluation accuracy ranged from 52.3% to 72.5%
Improving performance required increasing token costs per task — from roughly $9 at the low end to more than 3× that for the 72.5% configuration.
These numbers are self-reported on the public dataset. The official submission is still pending review. Given the volume of ARC submissions, evaluation turnaround is understandably slow.
But for me, the number isn’t the headline. What matters more is what the architecture revealed:
- Deep reflection beats debate.
- Perceptual scaffolding matters.
- Verification is non-negotiable.
- Thinking time scales performance.
If I’m honest, I now believe ARC-2 will be effectively solved — and saturated — in the coming months, maybe even weeks. The combination of architectural refinement and rapid frontier model improvement is accelerating quickly.
The Arc of This Series
Looking back, the progression feels almost inevitable.
Exploration — multi-agent Socratic reasoning.
Diagnosis — perception is the bottleneck.
Part 3
Resolution — a single Oracle with instrumentation, vision, utilities, and enforced verification.
What began as a distributed debate system evolved into something more disciplined.
Less theatrical. More deliberate.
Final Reflections
ARC-2 doesn’t test language modeling.
It tests structured abstraction under minimal supervision.
What I learned building this solver:
- Debate doesn’t fix bad perception.
- Tools extend cognition.
- Stateless experimentation enforces rigor.
- Verified primitives outperform ad-hoc generation.
- Thinking time is a measurable resource.
- Vision isn’t optional — it’s foundational.
The Oracle architecture is just a structured loop: Reflect. Experiment. Falsify. Submit.
And sometimes, that’s enough to recover structure from chaos.
When I posted Part 1, frontier models had effectively saturated ARC-1 but were struggling on ARC-2. State-of-the-art results were in the 50%+ range, while the human baseline remained 100%.
At the time, I wrote that the benchmark remained effectively unsolved.
That statement no longer feels accurate.
As of last week, SOTA on ARC-2 has crossed 70%+. The trajectory is unmistakable. We are closing the gap quickly.
Whether ARC-2 falls in months or weeks is hard to predict. But it no longer feels distant.
Now onto ARC-3.
Building an ARC-2 Solver — From Socratic Panels to a Single Oracle was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.