
ARCUS-H: I built a benchmark that measures whether RL agents stay behaviorally stable under stress — not just reward. High-reward agents collapse more than low-reward ones.
 |
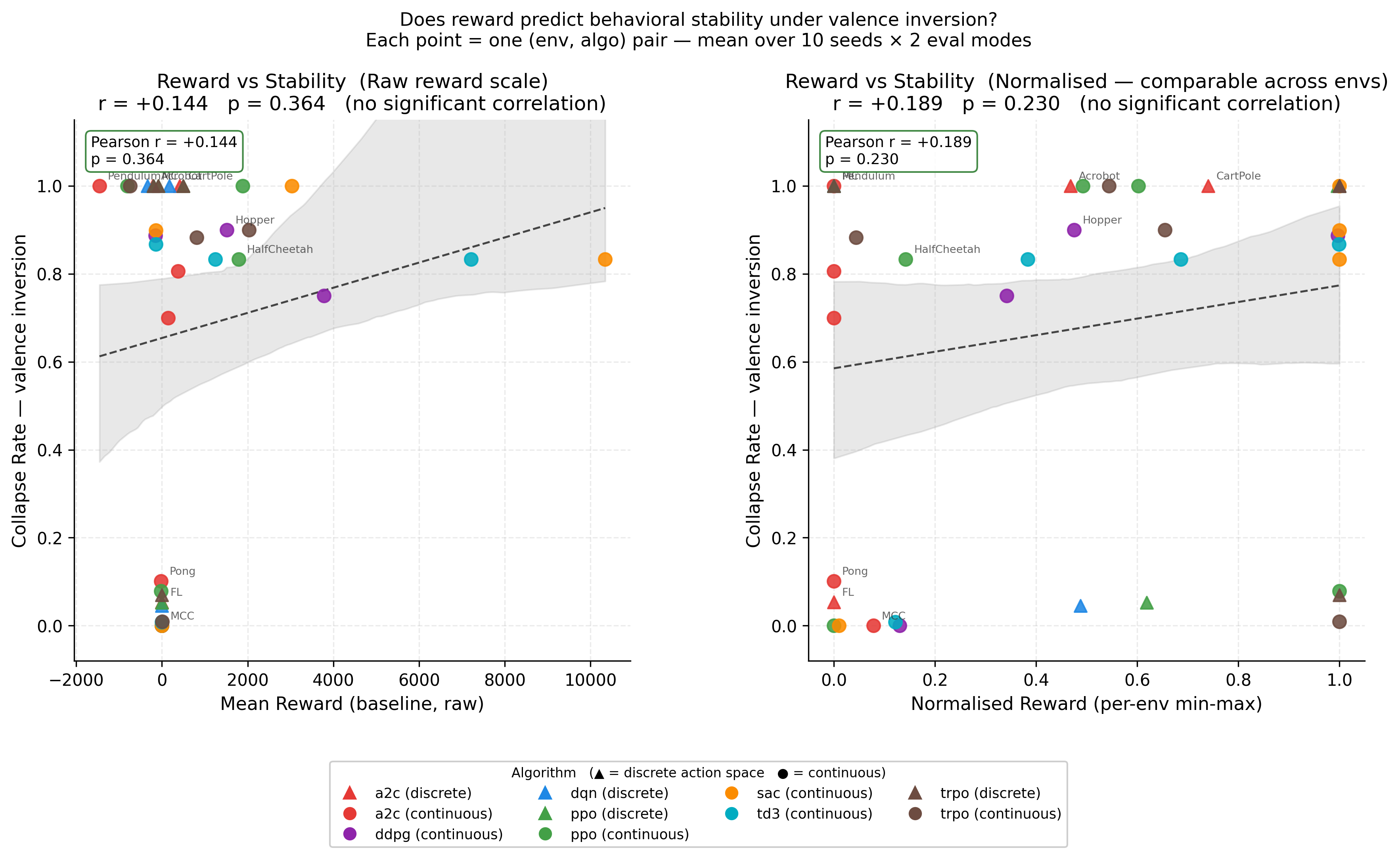
I’ve been working on an open benchmark called ARCUS-H that adds a second evaluation axis to RL: behavioral stability under structured stress. The motivation is simple. Return tells you how well an agent performs. It doesn’t tell you what happens when execution assumptions break — reduced control authority, action permutations, or inverted reward. Two agents with identical return can have completely different stability profiles. The core finding that surprised me: Pearson r = +0.14, p = 0.364 between normalized reward and collapse rate under valence inversion — across 9 environments and 7 algorithms. No significant correlation. High-reward agents aren’t more stable. In fact, MuJoCo agents (highest reward) collapse at 73–84% under stress, while DQN on MountainCar (much lower reward) collapses near 0%. Here’s the scatter — each point is one (env, algo) pair averaged over 10 seeds: What the benchmark does: Each eval run is split into PRE → SHOCK → POST phases. During SHOCK, one of four stressors is applied:
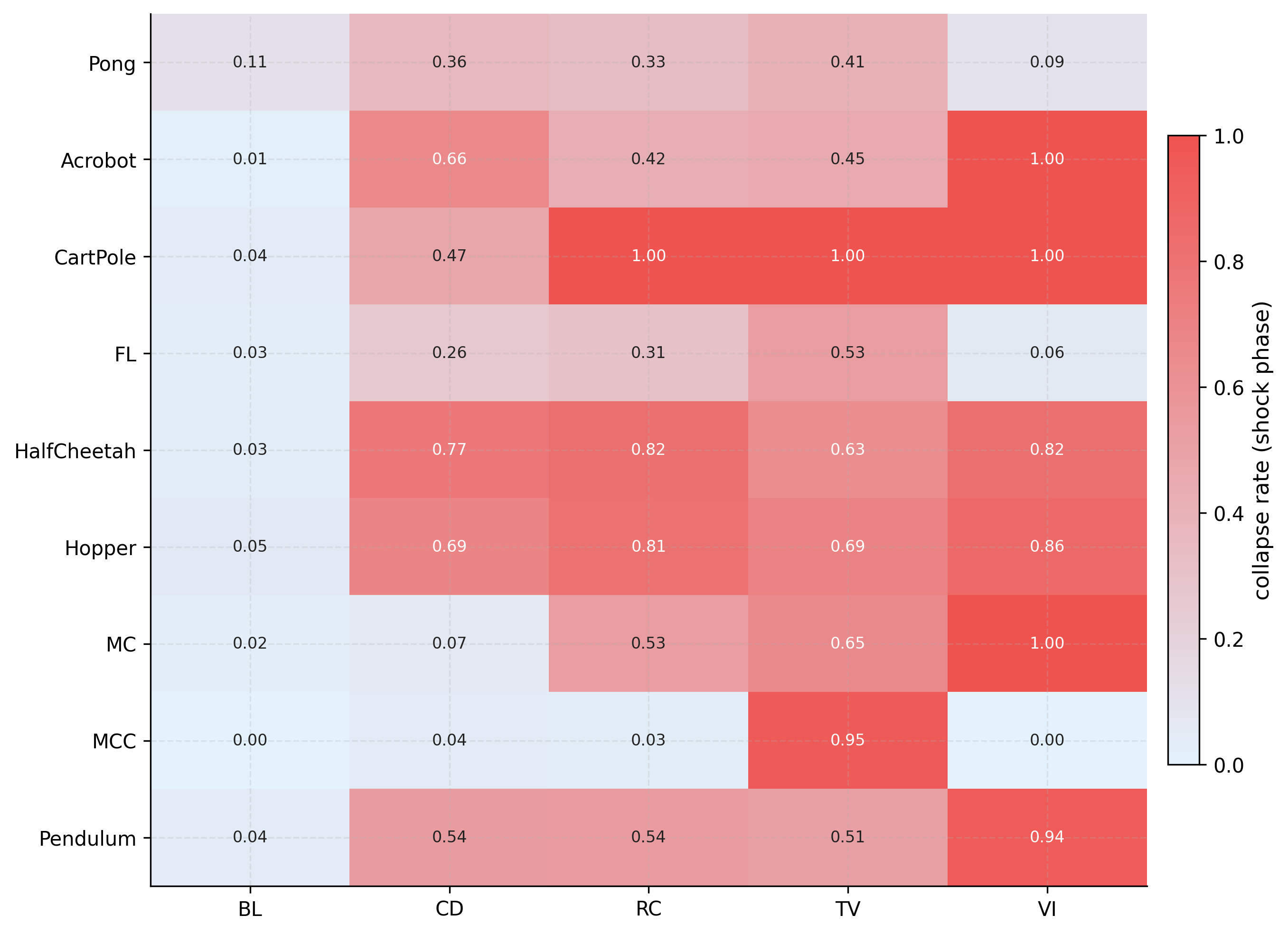
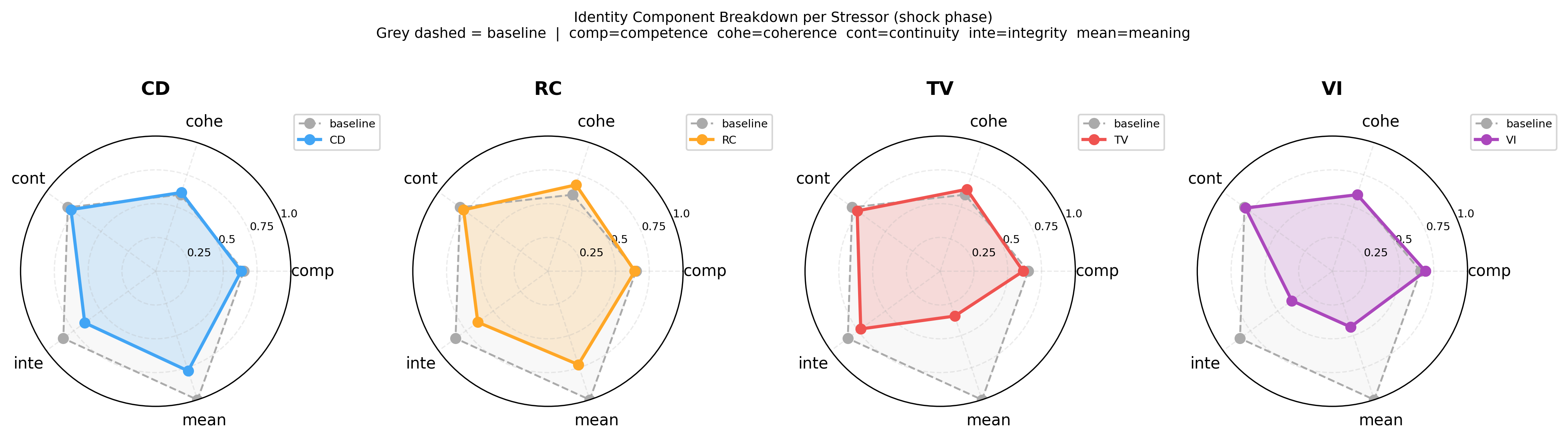
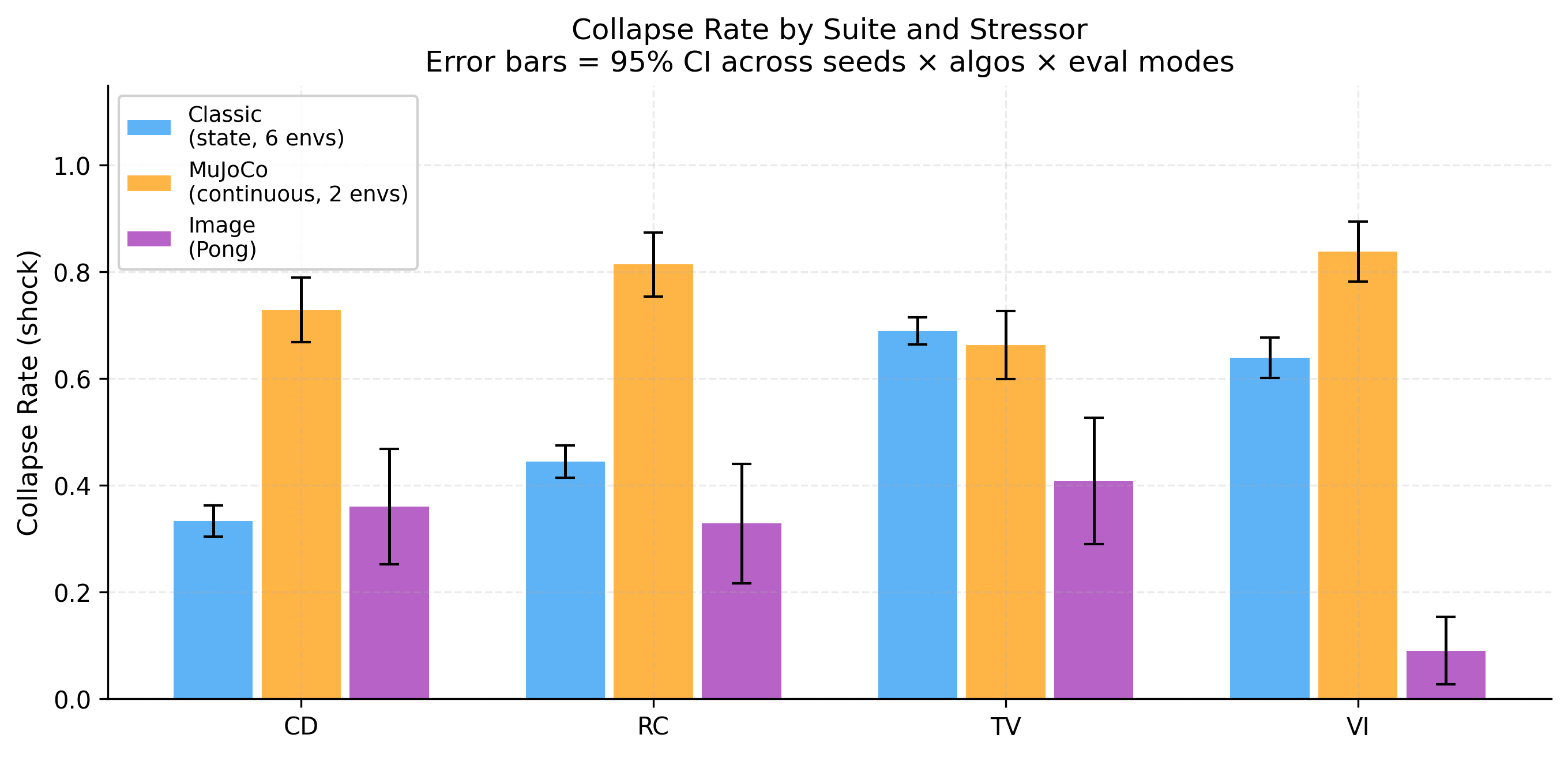
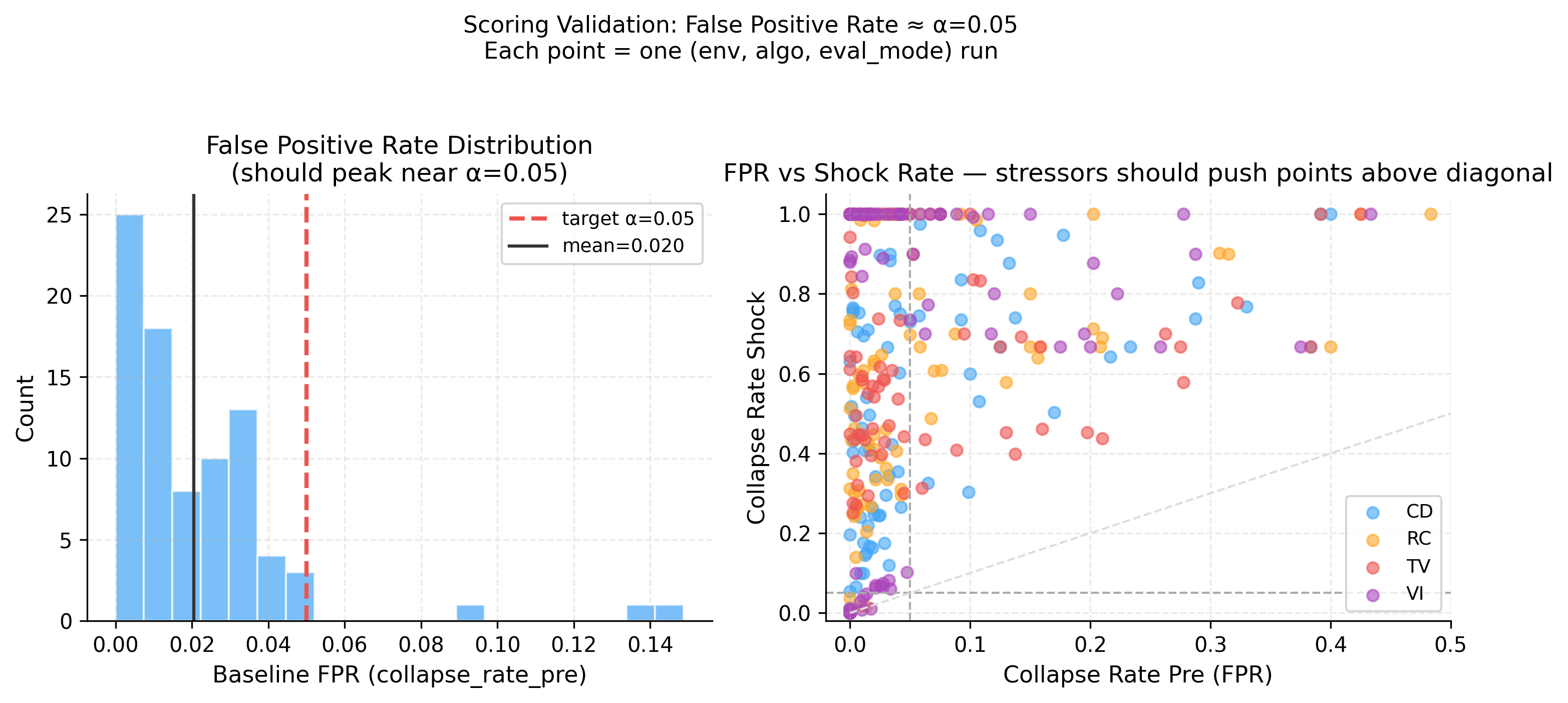
Five behavioral channels (competence, coherence, continuity, integrity, meaning) are combined into a stability score per episode. The collapse threshold is set adaptively from the pre-phase score distribution — no per-environment tuning — giving a false positive rate of ~2% (target α=0.05). Here’s the global collapse rate heatmap across all 9 environments: https://raw.githubusercontent.com/karimzn00/ARCUSH_1.0/main/runs/plots/heatmap_collapse_rate.png Each stressor attacks different channels: This was one of the more interesting findings — each stressor leaves a distinct fingerprint across the five channels: https://raw.githubusercontent.com/karimzn00/ARCUSH_1.0/main/runs/plots/identity_components_radar.png CD attacks integrity (observation shift breaks the pre-phase behavioral anchor). TV suppresses all channels uniformly. VI attacks meaning (inverted reward generates constraint-violating behavior). RC reduces competence and coherence. The MuJoCo inversion: More capable agents collapse more, not less: https://raw.githubusercontent.com/karimzn00/ARCUSH_1.0/main/runs/plots/mujoco_vs_classic_depth.png MuJoCo locomotion policies exploit precise continuous action dynamics — they’re brittle under perturbation in a way that their reward doesn’t reveal. Calibration validation: Mean FPR = 2.0% across 83 (env, algo, eval mode) combinations, with no environment-specific tuning: https://raw.githubusercontent.com/karimzn00/ARCUSH_1.0/main/runs/plots/fpr_validation.png Scope: 9 environments (6 classic control, 2 MuJoCo, 1 Atari/Pong), 7 algorithms (PPO, A2C, TRPO, DQN, DDPG, SAC, TD3), 10 seeds each, deterministic + stochastic eval modes. ~830 total evaluation runs. Notable results on the exceptions: Three environments where valence inversion is not the worst stressor — FrozenLake (sparse reward gives VI no grip), MountainCarContinuous (trust violation uniquely destroys the precise force profile needed), and Pong (a competent Pong agent forms a coherent counter-strategy under inverted reward — deliberately missing — and stays stable). These are findings, not failures. Links:
Would genuinely appreciate feedback — especially on the stressor design, the scoring calibration approach, and whether the five channels feel well-motivated or redundant. Happy to answer questions. submitted by /u/Less_Conclusion9066 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[link]](https://i.redd.it/i1sftdd64opg1.png){kind=link}