
Architecting the Cognitive Engine: A Fault-Tolerant, Intent-Aware AI Agent for Enterprise Big Data
Engineering a Deterministic Bridge: How to transform Probabilistic GenAI into a Fault-Tolerant Enterprise Analyst using Contract Engineering and Self-Healing Architectures.

Introduction: The “Stochastic Parrot” Problem
In Part 1 of this series, we focused entirely on Knowledge Base Infrastructure and Security. We architected a robust ‘Triple-Lock’ mechanism to securely ingest varied enterprise data, ranging from unstructured PDFs to raw APIs. This system utilizes Serverless Spark (EMR on EKS) and Airflow 3, feeding the data into a secure, Multi-Tenant Knowledge Base. We successfully implemented a secure semantic memory layer with granular access controls, enforcing data isolation via Identity Context and Document Level Security (DLS).
But a secure database, no matter how robust, is not intelligence.
Most enterprise RAG (Retrieval-Augmented Generation) implementations fail because they equate indexing with understanding. They assume that once the data is stored, the job is done. However, if a user asks, “How is the campaign performing?”A standard RAG system acts like a Stochastic Parrot. It searches for documents containing the word ‘campaign’ and simply regurgitates the text.
In the enterprise, users don’t want a parrot. They want an Analyst.
The enterprise requires a system capable of Logical Deduction, not just text retrieval. It must inherently discern that “How does the Time-Decay attribution model work?” necessitates a static methodology retrieval, whereas “How many conversions were attributed to the Mobile channel yesterday?” demands a real-time aggregation over the secure client index.
In this article, I will break down the Cognitive Engine that sits on top of our Big Data pipeline. I will detail how we evolved from simple vector retrieval to a Multi-Modal AI Agent that utilizes Semantic Routing to reason, calculate, and visualize answers on the fly.
Key Concepts Guide
- Stochastic Parrot: An AI that mimics human language by guessing the next word, often without understanding the actual facts.
- RAG (Retrieval-Augmented Generation): The process of giving an AI access to a private library of data so it answers with facts, not just memory.
- Semantic Routing: A ‘traffic controller’ that analyzes what a user wants (e.g. aggregations vs definitions) and sends them to the right tool.
- k-NN (Vector Search): A search method that finds results based on meaning (e.g., finding ‘laptop’ when you search ‘computer’) rather than just keywords.
- Lexical Search: Traditional search that looks for exact keyword matches (like ‘Ctrl+F’), crucial for specific IDs or error codes.
- DTO (Data Transfer Object): A strict digital container or ‘form’ used to ensure data moves between the AI and the web application in a predictable format.
- Deterministic vs. Probabilistic: The conflict between software, which is rigid and predictable (Deterministic), and AI, which is creative and random (Probabilistic).
Section 1: The Orchestration Layer (The Executive Function)
If the Knowledge Base acts as the system’s Hippocampus (long-term memory), the Orchestration Layer functions as its Pre-Frontal Cortex (executive decision-making). Its role is not to store information, but to arbitrate intent.
In standard RAG architectures, queries are blindly fired at a vector database, hoping for a match. We rejected this ‘spray and pray’ approach. Instead, we architected a Semantic Gateway in Python that intercepts every user prompt before it touches the underlying data layer.
We treat every query as a High-Dimensional Classification Problem first.
This Orchestration Layer leverages Claude (via Amazon Bedrock) not as a content generator, but as a Deterministic Router. It deconstructs the semantic nuance of the prompt, distinguishing between a request for static methodology and a request for temporal analytics to determine the precise data topology required.
By resolving this intent upstream, we achieve two critical engineering goals:
- Hallucination Prevention: The model is strictly grounded in the correct context (e.g., it won’t try to ‘calculate’ a definition).
- Query Optimization: We avoid expensive, unnecessary scans of the raw data lake when a simple documentation lookup will suffice.
1. Architecture: The ‘Intent-First’ Flow
Here is the exact lifecycle of a request through our system:
- User Query: The process begins when the user submits a prompt (e.g., “What was my ROAS last week?”).
- Intent Classification: The Python API intercepts this query and uses the LLM to classify the intent (Static Definition vs. Live Metrics).
- Routing: Based on that classification, the system deterministically routes the request to the correct OpenSearch index.
- Context Injection: The system retrieves the raw data (text chunks or JSON metrics) and ‘injects’ it into the LLM’s prompt window, effectively giving the model a temporary, accurate memory of that specific client’s data.
- Prediction (Generation): The Generator Model (Claude) processes this enriched context to construct the final answer, strictly adhering to the output contract (Text vs. Graph).

2. The Engineering Challenge: Handling Ambiguity
Routing sounds simple, but in practice, user queries are very vague. A query like “It’s not working” is mathematically useless to a vector store.
To solve this, we didn’t just ask Claude to ‘classify’. We engineered a Chain-of-Thought System Prompt that forces the model to reason before routing. We treat the Router not as a chatbot, but as a rigid decision tree customized for our specific data topology.
Here is the actual System Prompt we optimized for the Orchestration Layer:
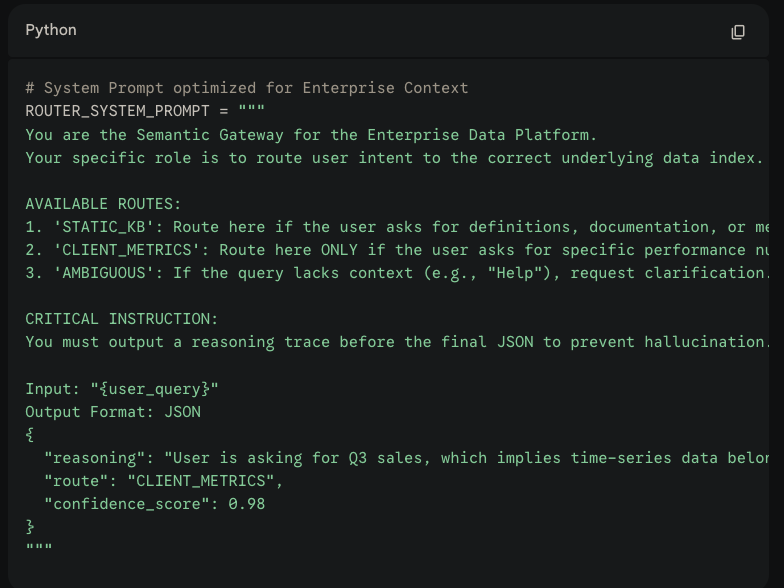
Section 2: Retrieval & Grounding
1. The Dual-Index Strategy
Once the Orchestration Layer determines the ‘Intent’, the system transitions from Decision to Execution. The Python API does not simply ‘search the database’, it executes a targeted retrieval strategy against a bifurcated OpenSearch topology.
We architected our retrieval layer around two distinct index types, each optimized for different data behaviors:
- The Static Methodology Index: This index stores high-density text, definitions, API and product documentation. It relies heavily on dense vector embeddings to capture conceptual nuance.
- The Client Metrics Index: This index stores high-velocity performance data, campaign stats and conversion metrics. It is optimized for exact value lookups and time-series filtering.
- Security as a Performance Accelerator: This separation drives massive efficiency. Because the Router determines the intent before the search begins, we can physically ignore irrelevant indices.
If a user asks for a static definition (e.g., “What is ROAS?”), the system explicitly targets only the Static Index. We do not waste compute resources scanning millions of records in the Client Data index for a definition that isn’t there. By narrowing the “search field” to only the relevant bucket, we significantly reduce query latency.
Furthermore, this mechanism reinforces the ‘Triple-Lock’ Security from Part 1. When the system does need to search the Client Metrics Index, it forcibly injects a client_id filter at the database level. This ensures that even if the AI makes a mistake, the underlying search engine is physically restricted to that specific client’s partition.
Bonus Tip: Context is King. A strict contract needs rich data. Indexes beyond the basics include Shared Static Knowledge, Client Data, Contractual Documents and so on. The more specific the index, the more precise the resulting Data Transfer Object (DTO) will be.
2. The Precision Paradox: Why Vector Search Wasn’t Enough
During our beta testing, we encountered a critical failure mode inherent to modern AI: The Loss of Lexical Precision.
Pure Vector Search (Semantic Search) is excellent at understanding concepts, but terrible at specific identifiers. For example, if a user searched for ‘Error Code 505’, the embedding model focused on the ‘meaning’ of the text would often retrieve generic documents about ‘server errors’ or ‘connectivity issues’, completely missing the specific technical documentation for code ‘505’.
In an enterprise context, ‘close enough’ is not good enough.
To solve this, we implemented a Hybrid Retrieval Strategy. We combined the best of both worlds within a single OpenSearch query:
- Semantic Search (k-NN): Captures the user’s rough intent and conceptual meaning.
- Lexical Search (Keyword Matching): Enforces precision by matching exact identifiers like IDs or error codes wherever necessary.
By weighting these two scores together, we created a retrieval engine that understands nuance but respects exact identifiers.
Section 3: The Deterministic Bridge – Engineering Reliability
The true power of this architecture lies in its Multi-Modal Output. The system understands that users don’t always want text, sometimes, they need visualizations for faster understanding.
However, delivering this introduces a fundamental conflict in computer science: The Probabilistic vs. Deterministic Conflict.
- The LLM is Probabilistic: It is creative, statistical, and prone to variance.
- The Frontend UI is Deterministic: It is rigid. A dashboard library (like D3.js or Recharts) expects a precise JSON schema. A single missing comma or malformed key crashes the response required by the user.
To bridge this gap, we rely on two layers of defense: Contract Engineering and Fault-Tolerant Architecture.
1. Contract Engineering: The First Line of Defense
We moved away from generic prompt engineering (“Please give me JSON”) to Contract Engineering. By defining strict Pydantic models in the Python layer, we create an immutable contract between the AI’s flexibility and the UI’s rigidity.
When combined with a highly specific system prompt, one that includes “One-Shot” examples of valid graph configurations, the model is constrained to output a specific Data Transfer Object (DTO).
This approach alone makes the system robust for 90% of use cases. But for an enterprise system, 90% is not enough.
2. Pattern for Fault Tolerance: The ‘Self-Healing’ Loop
For engineers looking to build truly resilient Agents, the most effective pattern to adopt is Recursive Validation.
Instead of treating an LLM response as final, treat it as untrusted user input. By wrapping your generation calls in a try/except validation block, you can create a ‘Self-Healing’ mechanism.
If the Pydantic validation fails (e.g., the model misses a key field), you don’t crash. Instead, you capture the specific validation error and feed it back to the model as a new prompt. This allows the model to ‘read’ its own mistake and correct it in real-time.
This pattern transforms the LLM from a ‘black box’ into a collaborative engineer, capable of debugging its own output before the user ever sees a glitch. However, this loop must be carefully rate-limited. Without proper safeguards, recursive validation can lead to runaway token usage and increased operational costs.
Conclusion: Breaking the Support Bottleneck
The evolution from a standard data pipeline to a Cognitive Engine represents more than just a technical upgrade, it is a fundamental shift in our operational model.
In Part 1, we solved the problem of Access, building a secure ‘Triple-Lock’ infrastructure to unify enterprise data into a Knowledge Base. In Part 2, we solved the problem of Latency, moving beyond simple retrieval to build an Agent capable of reasoning and self-correcting visualization.
But the true impact of this system isn’t measured in query speeds or vector dimensions. It is measured in autonomy.
Before this architecture existed, “getting an answer” was a human-intensive workflow. A stakeholder needing specific campaign metrics or methodology clarifications faced hours of support tickets, weeks of back-and-forth emails, and scheduled meetings just to align on definitions. The data existed, but it was gated behind human bottlenecks.
By strictly enforcing Identity Context, utilizing Semantic Routing for intent isolation, and bridging the Probabilistic/Deterministic divide, we have eliminated those weeks of friction. We didn’t just build a tool; we democratized intelligence.
What once required a support team to compile is now available at the user’s fingertips in seconds. That is the true promise of Enterprise AI, not just answering questions, but removing the wait between curiosity and insight.
Architecting the Cognitive Engine: A Fault-Tolerant, Intent-Aware AI Agent for Enterprise Big Data was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.