
Architecting Enterprise RAG with Spark, EMR on EKS & Airflow 3
Generating an on-the-fly Knowledge Base from diverse Big Data: PDFs, CSVs, Zoom recordings, and Open API specs.

Introduction: The “Stale Data” Trap
In the rush to adopt Generative AI, many engineering teams fall into a common trap, they treat their data like a static library. The standard RAG (Retrieval Augmented Generation) tutorial teaches you to upload a PDF or a text file, vectorize it, and chat.
But the world of Big Data fundamentally rejects the concept of “static.”
As a Software Engineering Manager, I know that my customers don’t just want to chat with a manual. They need to interrogate living data. They need to ask, “Why are the metrics lower this month compared to last month?” or “Explain the methodology behind this specific drop.”
To answer these questions, an LLM cannot just “read” documents, it needs to “understand” Big Data delivered through internal APIs. The goal was to build a highly responsive customer-facing chatbot capable of answering complex business questions. However, we quickly realized that a chatbot is only as good as its data pipeline.
In this series, I will break down how we architected the underlying RAG platform that doesn’t just read documents; it taps into the pipeline. This is the story of how we used heavy-hitting Big Data tools like Spark, EMR on EKS, Airflow 3, and OpenSearch to build a secure, multi-tenant knowledge base engine on the fly.
The Blueprint: Core Concepts & Technologies
Before diving into the architecture, it is essential to define the building blocks of this system. We moved beyond standard implementations to leverage specific enterprise grade capabilities:
- RAG (Retrieval-Augmented Generation): A technique that optimizes LLM output by referencing an authoritative knowledge base outside its training data. Instead of relying on the model’s (potentially outdated) memory, we “ground” its answers in our live data.
- Multi-Tenancy: An architecture where a single instance of the software serves multiple customers (tenants). The critical challenge here is Data Isolation, ensuring Client A never sees Client B’s data, even though they share the same database.
- Vector Embeddings: The translation of text (or API specs) into lists of numbers (vectors) that represent semantic meaning. This allows the system to search for “concepts” rather than just matching keywords.
- Amazon EMR on EKS: A deployment model that runs Apache Spark (big data processing) on Amazon EKS (Kubernetes). This approach allows compute resources to spin up and down instantly, contrasting with traditional, always-on clusters.
- Apache Airflow 3: The latest version of the industry-standard workflow orchestrator. We utilized its Dataset-Aware Scheduling to trigger pipelines based on data arrival rather than just fixed time intervals.
- OpenSearch (Vector Engine): A distributed search and analytics suite. We utilized its k-NN (k-nearest neighbors) plugin to store vectors and its DLS (Document Level Security) to enforce strict access controls.
1. The Elephant in the Room: Data Diversity & The “API Knowledge” Gap
The biggest challenge in Enterprise AI isn’t the model; it’s the data sources. Real-world business intelligence is messy. It lives in REST APIs, CSV files, and complex analytical data sources.
We realized that simply ingesting data wasn’t enough. We had to teach the system how to fetch relevant data.
Instead of standard scraping, we engineered a pipeline that ingested OpenAPI Specifications (Swagger) directly into our Knowledge Base. If you have a standard REST API that comes with OpenAPI specs, ingesting the specs themselves trains your LLM to accurately judge which endpoint to call for a user-based query.
By vectorizing the API definitions, we gave the AI ability to understand how to construct queries on the fly. This transformed the system from a passive reader into an “active agent” that could interpret a user’s intent and map it to the correct API endpoint or business intelligence report. This capability bridges the gap between static knowledge and dynamic action, allowing the LLM to interface with any standard REST API autonomously.
2. Selective Ingestion: The “Whitelisted” Approach
A common pitfall in RAG systems is “Semantic Chunking” of raw JSON responses. This creates noise. An LLM doesn’t need to ingest every single field in a JSON blob to answer a business question.
We took a strictly engineered approach: Configurable Field Whitelisting.
We built a knowledge base ingestion engine that didn’t just dump data; it acted as a sophisticated filter. We defined “Knowledge Templates”, easy-to-configure JSON schemas that specified exactly which fields were relevant for the customer (e.g. average_frequency, reach). We also implemented intelligent precision handling stripping away high-precision floating-point noise (e.g. rounding 9 decimal digit precision) that confuses vector models without adding business value.
This Pre-Processing Filtering served three critical purposes:
- Signal-to-Noise Ratio: It ensured the embeddings in OpenSearch were dense with meaning, not syntax.
- Cost Efficiency: We processed and stored only high-value data, drastically reducing vector storage costs.
- High-Performance Retrieval: With a leaner index free of “data junk,” query latency decreased, resulting in faster and more accurate retrievals.
3. The Engine: Serverless Spark with EMR on EKS
The choice of compute infrastructure was critical. In a traditional Big Data setup, you spin up a dedicated Amazon EMR cluster on EC2. You pay for the master nodes 24/7, and you pay for the core nodes even when they are idle between batches.
For an “on-the-fly” system, this legacy model was a non-starter.
- The Latency Problem: A standard EMR cluster can take 10–15 minutes just to bootstrap. In a world where data velocity matters, we couldn’t afford that startup penalty every time a new dataset (like a Zoom transcript or API spec) arrived.
- The Cost Problem: Keeping a cluster running for sporadic ingestion jobs is financially irresponsible. We needed a system that only billed us for the minutes of compute used to process the embeddings.
The Solution, EMR on EKS. We architected the system using Amazon EMR on EKS, effectively creating a serverless Spark environment.
By decoupling the compute (Spark) from the infrastructure (EC2), we achieved three major wins:
- Instant Scalability: Since our Airflow 3 instance was already hosted on the same EKS cluster, triggering a Spark job became as fast as scheduling a Kubernetes pod. There was no “cluster creation” time but just immediate execution.
- Resource Density: We could pack multiple tenant ingestion jobs onto the same underlying EKS nodes without them fighting for resources, thanks to Kubernetes namespaces and resource quotas.
- Cost Optimization: We eliminated the “idle tax.” If no data was flowing, our compute cost was negligible.
This shift allowed us to run a high-performance Big Data pipeline with the agility and cost profile of a microservice.
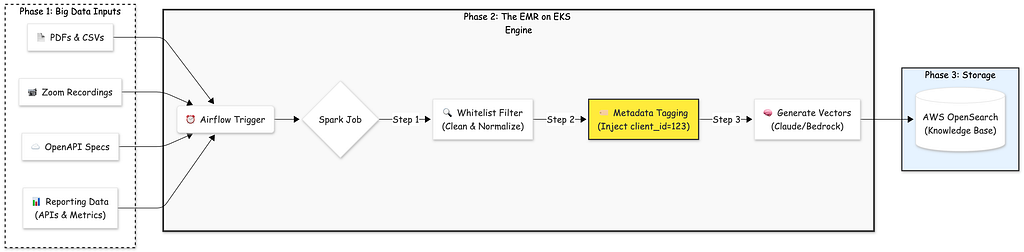
4. The Fortress: Multi-Tenancy & Client Data Isolation
For a customer-facing platform, “Hallucination” is an annoyance, but “Data Leakage” is an extinction level event.
We could not afford a “trust the frontend” approach. If a user from Client A asked a question, it had to be physically impossible for the system to retrieve an embedding belonging to Client B.
We implemented a “Triple-Lock” Isolation Architecture that enforced tenancy at the Identity, Application, and Database layers.
Phase 1: The “SSO” Integration (Identity & Scope Narrowing)
Security begins the moment the user hits the application. We integrated our RAG system directly with the enterprise SSO provider to establish a strict “Identity Context.”
- Mandatory Context: Upon login, the system derives the client_id and binds it to the user’s session. This client_id becomes a mandatory, immutable field for every single downstream retrieval operation.
- Entitlement Mapping: We didn’t just stop at “Who are you?” We also asked, “What did you pay for?” The login process retrieves the client’s specific contract details (Product Suite, API Access Level).
- World Narrowing: This effectively “shrinks the universe” for the AI. If a client only has access to the “Reporting Module” but not the “Forecasting Module,” the system automatically narrows their search scope. The AI is blind to data or APIs that fall outside their contractual entitlements.
Phase 2: The “Zero-Trust” Ingestion Strategy (Spark & Routing)
Many engineers make the mistake of creating a separate OpenSearch index for every tenant. At our scale, with thousands of clients, this would explode the cluster state (the “Too Many Shards” problem).
Instead, we architected a Shared-Index Strategy with Custom Routing:
- Immutable Tagging: During the Spark ingestion job on EKS, every single document (whether from a PDF, API spec, or CSV) is stamped with a mandatory client_id field. This is not optional; the schema validation fails the job if this field is missing.
- Custom Routing: We configured the client_id as the Routing Key in OpenSearch. This ensures that all data for a specific client resides on the same physical shard. This doesn’t just improve isolation; it dramatically speeds up query performance because the engine only needs to check one shard instead of broadcasting the query to all nodes.
Phase 3: The “Double-Lock” Query Execution
When a query arrives, we don’t rely on a single defense mechanism. We enforce isolation at two distinct layers:
- Lock 1: Code-Side Injection (The Application Layer): We never trust user input. Instead, we extract the client_id directly from the secure SSO token (JWT). Our internal Query Builder then intercepts every request and injects a mandatory Hard Filter for that specific client ID. This ensures that the query sent to the database is mathematically incapable of requesting another tenant’s data.
- Lock 2: Service-Side Enforcement (The Database Layer): As a final fail-safe against code errors, we configured OpenSearch Document Level Security (DLS). We mapped our backend service roles to dynamic policies that validate every read operation. Even if the application logic failed, the OpenSearch engine itself would physically suppress any document that does not match the authenticated tenant’s signature.

5. Summary: To Build Great AI, You Must Build Great Pipelines
There is a common misconception that Generative AI renders traditional engineering obsolete. The reality is the opposite, AI has exponentially raised the bar for our infrastructure.
LLM is only as intelligent as the context you provide it. You can have the world’s most advanced model, but if it is fed by a data pipeline that is slow, insecure, or unorganized, it will fail to deliver value. The success of this project wasn’t defined by the prompt engineering; it was defined by the infrastructure engineering.
As Big Data leaders, our role has evolved. We are no longer just moving data; we are curating intelligence. The future belongs to the builders who can treat vector embeddings with the same rigor and security as we treat financial transactions.
Don’t just build a chatbot. Build a Fortress of Intelligence that stands on the shoulders of Big Data.
6. Coming Up Next: The Brain Behind the Bot
We have built the Fortress (Security) and the Factory (Ingestion). But a secure database is not a chatbot.
In the next article, I will peel back the layers of the AI Logic that sits on top of this infrastructure. I will move beyond simple “Prompt Engineering” to show how we architected a Semantic Reasoning Layer using AWS Bedrock and Claude.
What we will cover:
- The “Intent Router”: How we built a semantic classifier to decide before the LLM even sees the question: “Is this a reporting query? A contract question? Or just small talk?”
- Hallucination Control: Implementing strict “Grounding” checks to ensure the AI never invents metrics.
- The “Prediction Engine”: How we achieved high-accuracy answers by coupling OpenSearch’s retrieval with the LLM. I will demonstrate how we used the specific shards and vectors we architected in Part 1 to drive the LLM’s prediction logic turning raw search hits into precise, mathematically correct business answers.
Follow me to get notified when Part 2 goes live. We are going to turn this passive data into an active agent.
Architecting Enterprise RAG with Spark, EMR on EKS & Airflow 3 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.