
AI Tools Decoded: Capabilities, Limitations, Problem-Solution Matching, and Why Projects Fail
When I was preparing AI sessions for colleagues in Asia in late 2025, I asked what they most wanted to learn. The answer wasn’t about the latest LLM architecture or cutting-edge research. They wanted something more fundamental: How do we identify real AI use cases? How do we experiment with our data? What concrete steps can we actually take?
These questions get to the heart of AI’s challenge in business. Everyone knows AI is powerful, but many organizations struggle to move from pilot projects to production. They chase use cases one by one, invest without strategy, and wonder why progress is so slow and nothing scales.
I shared with them what I’ve learned over years with different industries. We’ll work through AI foundations, analyze a public customer churn dataset with AI’s help, build prediction models collaboratively, talk honestly about why most AI projects fail (spoiler: it’s rarely the technology), my perspectives on starting AI transformation holistically, and how cloud platforms facilitates the journey.
This blog covers a subset of those sessions. I hope it helps people with similar questions understand the AI toolkit, match problems to solutions, and develop a realistic picture of what it takes to make AI work in business.
I will share more on other aspects in my next posts.
AI Basics: Breaking Down the Toolkit
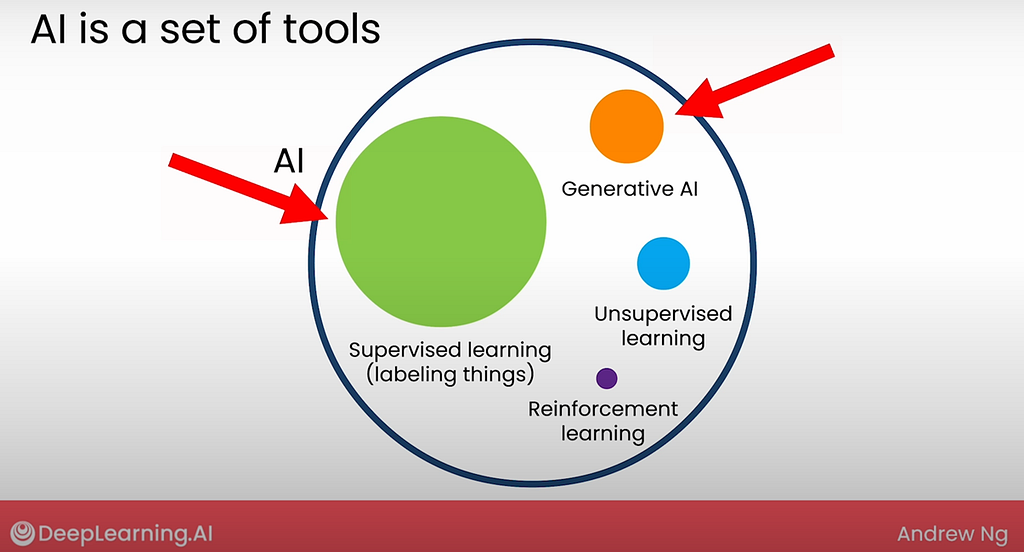
What is Artificial Intelligence (AI) actually? Strip away the buzzwords, AI is an umbrella term. It is a set of tools that enables machines to learn from experience, adapt to new inputs, and execute tasks resembling human capabilities — think of it as the entire hardware store.
Across industries, supervised learning and generative AI (GenAI) are the subsets of tools you’ll use most often, along with good old classical automation. Each has its place, and knowing when to use which one is half the battle.
Let’s start with classic supervised learning, which is the workhorse that’s been quietly powering business applications for years.
Supervised Learning: Teaching by Example

Supervised learning works like teaching a child through examples. You show it many instances: “This email is spam, this one isn’t.” “This customer churned, this one stayed.” “This transaction is fraudulent, this one is legitimate.”
The model learns patterns from these examples, which are called “labelled data”, to find patterns often too complex for humans to articulate but consistent enough for machines to detect.
You’ve probably interacted with supervised learning today without realizing it, for example: email spam filters, product recommendations on e-commerce sites, credit scoring models, medical diagnosis support tools and so on.
It excels at categorization. But here’s where many projects go wrong: the reliability of your output depends on your data quality.
Three critical questions determine success:
1. Does your sample data accurately represent the population?
For example, a model trained on Norwegian telco customers most likely won’t work well for Pakistani customers. The usage patterns, economic factors, competitive landscape, and customer behaviours are different. This seems obvious, but I’ve seen this mistake repeatedly, thinking “model is model.”
2. Does your data contain sufficient predictive information?
Imagine trying to predict customer churn using only names and gender. It would be nearly like a coin flip, since it’s missing many things that actually matter: service quality, pricing satisfaction, contract terms, support interactions, usage patterns etc.
If the signal isn’t in the data, no advanced algorithms will create it. “You can’t squeeze juice from a rock, no matter how good your juicer is.”
3. Is your data properly labelled?
If your historical churn labels are wrong — customers marked as “churned” who actually just paused service, or vice versa — your model learns incorrect patterns. Garbage labels in, garbage predictions out.
When you have a high portion of mislabelled data in your training set. Spending months on optimizing the model architecture, trying different algorithms, tuning hyperparameters won’t help much. But when you have finally cleaned the labels, a simple model will likely outperform the complex ones immediately.
Generative AI: The Content Creator

Generative AI (GenAI) is the subset of AI that produces content — text, images, audio, video. This is what everyone’s excited about right now, and for good reason.
Among GenAI technologies, Large Language Models (LLMs) are among the most impactful. LLMs are primarily trained using self-supervised learning, where they predict the next token, in a sequence. They learn from large datasets sourced from publicly available internet content, books, and other text sources, allowing them to understand patterns in language.
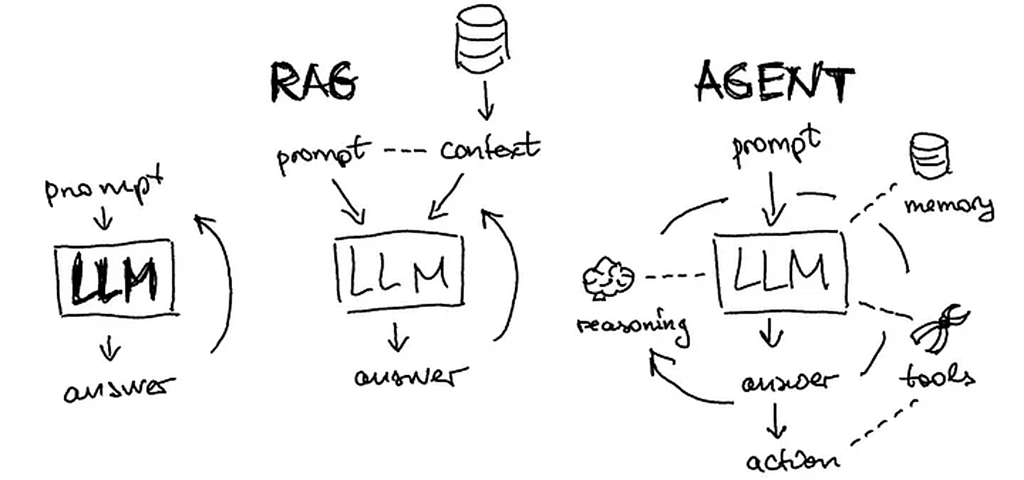
LLMs often serve as the “reasoning engine” of agentic systems. For those confused about the concepts of LLMs, RAG, and Agents, here are their key differences:
- LLMs: The core model that processes and generates text based on learned patterns
- RAG (Retrieval-Augmented Generation): A technique that combines an LLM with a retrieval system, allowing it to search relevant documents or databases and incorporate that information into its responses
- Agents: Systems that use an LLM as their reasoning component to perceive their environment, make decisions, use tools, take actions toward goals, and maintain memory of past interactions
Since LLMs are trained on internet content from a specific time period and predict the next token based on learned patterns, they have important limitations you need to understand:
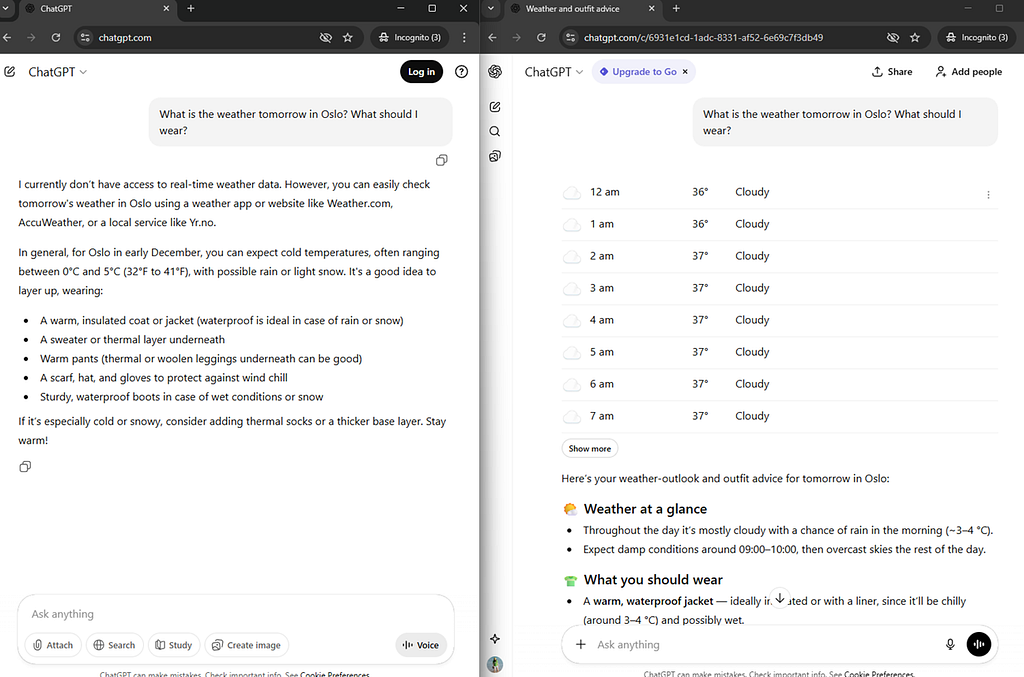
Knowledge Cutoff: The model’s knowledge is frozen at the time of training. It doesn’t have information about current events, real-time data, or future predictions. The solution is to give the LLM access to external knowledge sources — such as web search, RAG systems, databases, or real-time data feeds. In the screenshots below, you can see the difference between ChatGPT without and with internet access. Without access, it cannot provide tomorrow’s weather forecast. With access, it retrieves current data from weather services and provides an accurate answer.
Hallucination: LLMs can generate false, fabricated, or inaccurate information while presenting it confidently as fact. This happens because the model is predicting plausible-sounding text based on patterns, not retrieving verified information. Unfortunately, it’s currently impossible to fully eliminate hallucinations. However, there are several strategies to reduce their frequency:
- Access to external knowledge sources: Connecting the LLM to databases, RAG systems, or web search allows it to ground responses in verified information
- Improved prompting: Instructing the model to acknowledge uncertainty rather than guessing (e.g., “If you don’t know, say you don’t know”)
- Verification systems: Implementing fact-checking mechanisms or requiring the model to cite sources
- Temperature control: Using lower temperature settings makes outputs more deterministic and focused on high-probability responses (higher temperature = more creative/random, lower = more conservative/predictable)
Note: Vectara Hallucination Leaderboard tracks how frequently different LLMs hallucinate when summarizing documents.
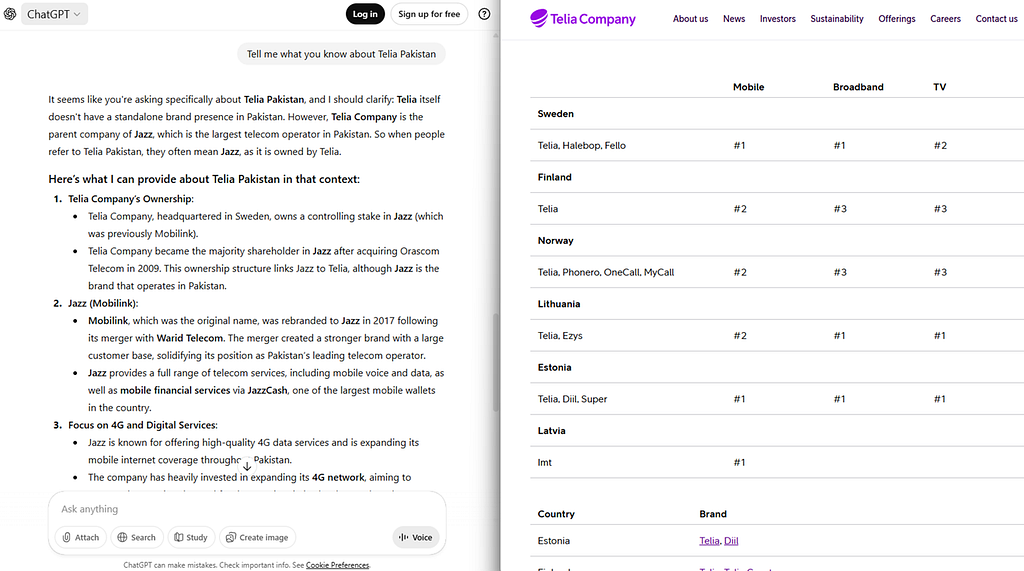
Biases and Harmful Content: LLMs are trained on human-generated data from the internet, which often contains societal biases, stereotypes, and harmful content. These biases can be reflected in the model’s outputs. For example, in Norwegian, “kjæresten min” is gender-neutral, meaning “my partner/boyfriend/girlfriend.” However, as shown in the image, Google Translate makes gendered assumptions based on occupational stereotypes — translating it as “girlfriend” for HR roles but “boyfriend” for engineering roles and management roles. This reveals how models can perpetuate gender biases present in their training data.

To address this, organizations deploy guardrails that validate content at two stages: filtering harmful or inappropriate user inputs before they reach the model, and reviewing AI outputs to catch biased, offensive, or inaccurate responses before they reach users.
Limited Context Window: LLMs can only process a finite amount of text at once, which means they may lose track of information from earlier in long conversations. Agent memory systems help address this by storing and retrieving important context.
Weak Mathematical and Structured Reasoning: LLMs struggle with precise calculations, complex math, and structured data operations because they’re trained to predict text patterns, not perform logical computations. Equipping AI agents with specialized tools solves this limitation — for example, connecting them to calculators, databases, APIs, or code execution environments. These tools also enable agents to take real-world actions (like sending emails, updating databases, or making API calls), transforming them from conversational interfaces into capable systems that can both think and act.
Classical Automation: Rule-Based Systems
Classical automation is code that follows predefined rules and logic. For example: “When a new order arrives, check inventory levels, update the database, and send a confirmation email.” It doesn’t make decisions or learn from experience — it executes the exact same steps every time based on the rules you programmed.
When it works well: classical automation excels when your process is stable, well-defined, and predictable. It’s fast, reliable, cost-effective, and easy to maintain.
When it breaks down: It only works when you can explicitly define all the rules and conditions. It fails when:
- Processes are too complex or nuanced to capture in rules
- You can’t anticipate every possible scenario or edge case
- Requirements change frequently
- The task requires judgment, interpretation, or handling ambiguity
Where to Use AI: Matching Problems to Solutions
The key to effective AI implementation isn’t just understanding what AI can do — it’s knowing when to use it. Deploying complex AI models for tasks a simple script can handle adds unnecessary cost, complexity, and maintenance burden without real benefit.
Classical Automation: Rule-Based Tasks
Best for: Repetitive, routine tasks that follow clear, deterministic rules where “if X, then Y” logic applies.
Examples: Data validation, scheduled reports, workflow automation, ETL pipelines
Key question: “Can I write down the exact steps?”
Why choose it: More cost-effective, faster, more reliable, and easier to maintain than AI. It performs exactly as programmed with no surprises, model drift, or retraining needed. If you can articulate the complete logic — “First do this, then check that, if this condition then do that” — use automation and save your AI budget for problems that truly need it.
Supervised Learning: Pattern Recognition
Best for: Complex patterns that defy explicit rules but can be learned from examples.
Examples: Customer churn prediction, demand forecasting, recommendation engines, fraud detection
Key question: “Do I have examples but can’t explain the rule?”
Why choose it: Handles complexities you can’t articulate. If you think “I know it when I see it, but I can’t explain how,” supervised learning can discover the patterns in your data.
Generative AI: Reasoning and Synthesis
Best for: Tasks requiring judgment, context understanding, reasoning, and communication.
Examples: Drafting emails, summarizing documents, generating code, synthesizing research, customer support conversations
Key question: “Would I trust a smart new hire with good instructions to handle this?”
Why choose it: When tasks require intelligence — understanding context, making judgment calls, adapting approaches based on situations. If the task needs someone who can think and reason, Generative AI is appropriate.
Combining Approaches
Real-world applications rarely use just one approach — they combine all three, each doing what it does best. For example, a customer service email system can be designed with:
- Language Models analyze incoming emails for sentiment (frustrated/neutral/happy) and classifies topics (billing/technical/service changes), and draft tailored responses
- Supervised Learning predicts churn risk based on customer history
- Classical Automation routes tickets to the right team (billing→payments, technical→support) and prioritizes high-risk, negative-sentiment cases

Note: Can you use Generative AI to build classical automation, supervised learning models, and even GenAI solutions themselves? Absolutely. Use AI tools to build AI solutions — let GenAI handle tedious coding and analysis while you focus on strategic thinking.
The goal isn’t strict boundaries — it’s starting with the simplest appropriate tool and layering in complexity only when needed.
It sounds straightforward: understand the problem, break it into manageable pieces, select the right solution for each component, and integrate them. In theory, yes. In practice? Not quite.
Why AI & Data-Driven Initiatives Fail
To paraphrase Tolstoy’s opening to Anna Karenina: “All successful AI projects are alike; every failed AI project fails in its own way.”
Successful AI projects share common characteristics — high-quality data, adequate infrastructure, robust governance, solid business needs, a clear, holistic, and executable roadmap, competent teams, customer-centric culture, clear ownership, cross-functional collaboration, and sustained investment.
But failed projects fail for dozens of different, specific reasons:
- Data quality issues: Pilot data works beautifully, but production data reveals chaos
- No real business case: Solutions built without addressing actual business needs
- Lost in translation: Bureaucracy creates gaps between problem definition and implementation
- Fragmented investment: Chasing one-off use cases without strategic coherence
- Orphaned initiatives: Unclear process ownership means no operational champions to drive adoption or ensure data quality
- Integration nightmares: Ambiguous system ownership causes failures when connecting to legacy systems
- Skills shortage: Endless planning meetings but little progress on building and deploying
- Pilot purgatory: Successful pilots without clear paths to production
- Cost shocks: Underestimated expenses for talent, infrastructure, and compliance
- Delayed stakeholder involvement: Critical teams (legal, compliance, security) engaged too late to course-correct
The list of potential failures is nearly endless — each organization encounters its own unique combination of these challenges based on its structure, culture, and maturity.
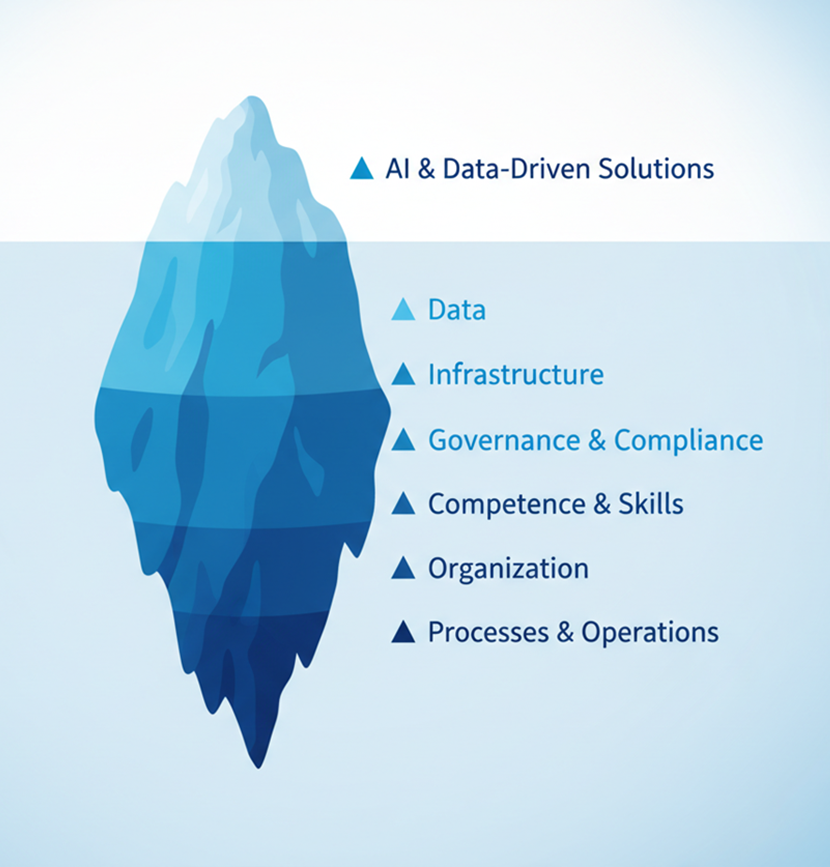
As the iceberg diagram illustrates, AI and data-driven solutions are just the visible tip. Below the waterline lie critical foundational layers. We often focus on what’s visible above the surface while neglecting what holds it up.
In my experience, I’ve only seen “icebergs” sink due to fractures below the waterline — never from issues at the visible tip.
I often compare delivering enterprise AI and data-driven solutions to running a restaurant: once you have a reliable supply chain, a well-organized kitchen, quality ingredients in your fridge and freezer, and trained staff, creating good dishes becomes achievable. But without those foundations, even the best chef will struggle. Similarly, AI success requires ensuring every foundational layer is solid before expecting the visible solution to deliver value.
AI Tools Decoded: Capabilities, Limitations, Problem-Solution Matching, and Why Projects Fail was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.