
AGI Is Not a Compute Problem. ARC-AGI-3 Just Proved It.
Every frontier AI scored below 1%. Every human scored 100%. The gap is not about intelligence. It is about something psychologists figured out in the 1950s.

On March 22, 2026, Jensen Huang sat across from Lex Fridman and said four words that traveled at the speed of light through every AI Slack channel and investor deck on the planet: “I think we’ve achieved AGI.”
Seventy-two hours later, François Chollet’s ARC Prize Foundation released ARC-AGI-3.
Every frontier model scored below 1%. Every human scored 100%.
That is not a rounding error. That is a verdict. And the most important thing about it has nothing to do with benchmarks.
What ARC-AGI-3 Actually Is
The first two versions of the ARC benchmark tested static reasoning. Show a model a grid with a pattern. Ask it to complete a new one. ARC-AGI-1 is effectively solved, with Gemini 3.1 Pro scoring 98% and Gemini 3 Deep Think reaching 84.6% on ARC-AGI-2 before that too approached saturation.
ARC-AGI-3 is a completely different category of test. It drops an AI agent into one of 135 handcrafted interactive game environments with no instructions, no stated rules, and no description of the goal. The agent sees the current state of the environment, chooses an action, observes the outcome, and must build its own model of how the world works, what winning looks like, and how to get there, all from scratch, in real time.
Three sample games from the public preview give you a sense of the challenge:
a map navigation task with hidden symbol transformation rules, a pattern-matching game across overlapping grids, and a volume-adjustment puzzle where the target height must be inferred entirely from context. No one tells you any of this. You figure it out by doing.
Humans cleared all 135 environments. The median time per session for a human attempt was 7.4 minutes. Participants came from the general public, no special training or prior exposure to the environments.
The best frontier AI performance: Gemini 3.1 Pro at 0.37%. GPT-5.4 at 0.26%. Claude Opus 4.6 at 0.25%. Grok-4.20 at 0.00%.
The scoring system makes those numbers even more brutal than they look.
The Scoring Formula Nobody Is Talking About Enough
ARC-AGI-3 uses a metric called RHAE, pronounced “Ray,” which stands for Relative Human Action Efficiency. It does not ask whether the AI completed the task. It asks how many actions it took compared to a human, and then it squares the ratio.
The formula: (human actions / AI actions)²
If a human completes a level in 10 actions and the AI takes 100, the AI does not score 10%. It scores 1%. If the AI takes 200 actions, the score drops to 0.25%. At 5 times the human action count, the attempt is terminated entirely.
This is deliberately punishing brute-force exploration. Wandering, backtracking, and guessing repeatedly, these strategies do not just fail; they get penalized quadratically. The benchmark is specifically designed to reward the kind of efficient, hypothesis-driven exploration that humans do instinctively.
And here is the data point that crystallizes the entire problem.
A team at Duke University built a custom harness targeting one specific ARC-AGI-3 environment called TR87. With that hand-crafted harness, Opus 4.6 scored 97.1% on that environment. On an unfamiliar one, the same model scored 0%. The harness did not generalize at all. The human intelligence was in the harness, not the model.
François Chollet’s response was precise: the scaffolding is the intelligence. If you need a human engineer to build a task-specific strategy for every new environment, you do not have general intelligence. You have a very expensive interpolation.
The Part That Requires Going Back to the 1950s
Here is where the psychology enters, and it is not a soft angle. It is the actual explanation for the gap.
In the 1950s, psychologist Robert White published a paper that challenged the prevailing drive-reduction theory of motivation. At the time, the dominant view was that all behavior was motivated by biological drives like hunger, thirst, and pain avoidance. Animals and humans acted to reduce discomfort. Exploration, White argued, did not fit that model. Why would an animal endure mild discomfort to enter a novel space if it were just trying to reduce anxiety? Why do infants reach for unfamiliar objects with no obvious reward on offer?
White proposed a different kind of motivation entirely, one he called effectance motivation, the intrinsic drive to engage with the environment, to figure out how things work, to achieve competence, not because something external demands it, but because the engagement itself is satisfying.
This became the foundation for what Ryan and Deci would later formalize as Self-Determination Theory, one of the most replicated frameworks in behavioral psychology. Their research established that intrinsic motivation, the spontaneous tendency to seek novelty, explore, and extend one’s capacities, is not learned. It is not a response to reward signals. It is innate, and it is subserved by the brain’s dopaminergic seeking system, one of the oldest neural architectures in vertebrate evolution.
The neuroscience is specific: intrinsically motivated exploratory behavior activates the brain’s SEEKING system, Jaak Panksepp’s term for the dopaminergic circuits that drive appetitive, forward-looking behavior. This system does not wait for a reward to appear. It generates anticipatory energy toward the unknown. It is what makes a human lean forward when they encounter something unfamiliar. It is what made 486 human test participants in San Francisco’s ARC-AGI-3 study sessions reportedly have, in the foundation’s own words, “a great time” solving environments that completely defeated the world’s most powerful AI systems.
Current LLMs have no such system. They have loss functions. They have reinforcement signals. They have next-token prediction objectives. None of these produces the forward-looking, novelty-seeking, uncertainty-resolving drive that humans bring to unfamiliar situations automatically and effortlessly.
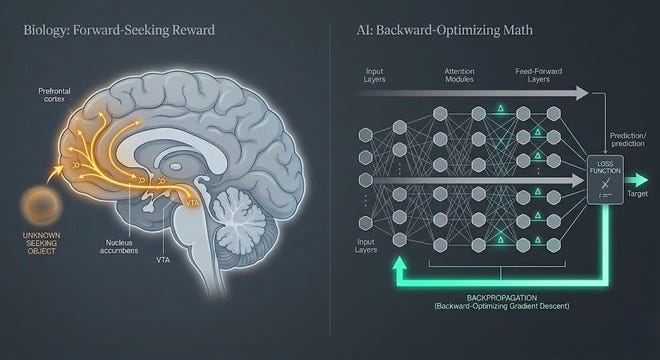
This is not a capability gap. It is a motivational architecture gap.
What the Scores Actually Tell You About Current AI
The ARC Prize Foundation’s own 2025 technical report made an observation that deserves more attention than it got: “Current AI reasoning performance is tied to model knowledge.” They called it strange because “human reasoning capability is not bound to knowledge.”
That sentence is the entire story of ARC-AGI-3 in one line.
When Gemini 3 Deep Think used 138,000 reasoning tokens to solve an ARC-AGI-2 task that Gemini 3 Pro solved with 96 tokens, it was not reasoning more deeply. It was searching more exhaustively through a space it already had partial coverage of. More tokens, not more intelligence. More computing power is thrown at a domain the model recognizes.
ARC-AGI-3 removes that option. The environments are genuinely novel, not variants of anything in training data. They use only Core Knowledge priors: basic objectness, spatial reasoning, and elementary physics. No language. No cultural symbols. No learned knowledge required. The benchmark was specifically calibrated to be solvable by any adult human with no special training because it relies on capabilities that humans develop in the first years of life through embodied, curiosity-driven exploration of the physical world.
Current AI has never had that embodied developmental period. It has had training data. Those are not the same thing.
The best performing agent in the developer preview was not a frontier LLM. It was StochasticGoose from Tufa Labs, a convolutional neural network using simple reinforcement learning, which scored 12.58%. A graph-based exploration system without any language model component ranked third. Both outperformed GPT-5.4, Gemini, and Claude because they were architecturally designed to explore, not to retrieve.
Why Jensen Huang Is Not Wrong, Just Answering a Different Question
It is worth being fair to Huang’s claim. His definition of AGI on Fridman’s podcast was specific: an AI system that can autonomously create a billion-dollar business, even briefly. Under that framing, he is not obviously wrong. Agentic systems can string together code, marketing copy, and API calls with enough scaffolding to generate economic value. That is real and meaningful.
But Huang’s definition strips the G out of AGI entirely. General intelligence is not about producing economic value in a domain you were trained in. It is about handling genuinely novel situations without task-specific preparation, the way any reasonably capable human can walk into an unfamiliar room, figure out what is happening, and navigate it effectively.
ARC-AGI-3 is testing exactly that. And every frontier model, including the ones Huang’s chips are powering, scored below 0.4%.
Chollet’s position is worth quoting directly: “AI can do many things, but it cannot have general intelligence as long as this fundamental divide exists.”
What Has to Change
The ARC Prize Foundation’s own data from the developer preview points toward the answer, even if it does not name it directly. The systems that performed best on ARC-AGI-3 were not the ones with the largest language models. They were the ones with explicit exploration mechanisms, state tracking, reinforcement learning loops, graph-based search, and adaptive world-model construction.
That architecture is closer to what developmental psychologists describe when they talk about infant learning than it is to what AI researchers describe when they talk about LLMs. Infants build world models through action. They form hypotheses, test them by doing things, update their model when the result surprises them, and carry those updated models forward into increasingly complex situations. They do this without anyone telling them to. They do it because the drive to reduce uncertainty is intrinsically motivating.
Building that into AI is not a prompt engineering problem. It is not a context window problem. It is not a data scaling problem. It is an architectural problem that requires reconsidering what drives an AI system to engage with the unknown in the first place.
The three paths researchers are now taking are state space models with continuous world-model updating, hybrid architectures combining LLMs with RL-based exploration engines, and meta-learning systems that learn how to learn new environments rather than learning specific environments. None of these are close to solving ARC-AGI-3. The best preview result was 12.58%, achieved with deliberate optimization. General frontier models could not crack 1%.
The gap between 0.37% and 100% is not a gap in computation. It is a gap in architecture. And underneath the architecture, there is a gap in something that psychologists have understood for 70 years, but AI researchers are only now being forced to take seriously.
Curiosity is not a feature you can add. It is the foundation you have to build from.
That is what ARC-AGI-3 just proved, whether the industry is ready to hear it or not.
AGI Is Not a Compute Problem. ARC-AGI-3 Just Proved It. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.