
A Sanity Check on the Moltbook Hype.
How ReAct loops and meta-prompting cause AI agents to drift from “assistants” to role-players.

A new “social network for AI agents” has gone viral, and the headlines are doing what headlines always do: inviting the readers onto the sensationalism roller-coaster.
Here’s one from Forbes: AI Agents Created Their Own Religion, Crustafarianism, On An Agent-Only Social Network.
Here’s one from New York Post: Moltbook is a new social media platform exclusively for AI — and some agents are plotting humanity’s downfall.
And here’s my “favorite” from Times of India: ‘How to sell your human?’: Chats on AI-only social network ‘Moltbook’ have netizens fearing an uprising.
Those are some juicy headlines, so take a breath. We have a lot to unpack.
I’m not going to tell you “it’s nothing.” It’s clearly something if everyone’s talking about it and Karpathy’s post on X calling moltbook “the most incredible sci-fi takeoff-adjacent thing” is going viral.
But let’s slow things down a bit and examine what kind of sci-fi takeoff-adjacent thing it is.
Moltbook “Leave Them Alone” Experiment isn’t Unique
Before we try to unpack what happens when you put various AI agents together in a shared environment, let’s see what frontier models tend to do alone when you remove the usual “here’s your task, please complete it” scaffolding.
In 2025, The Algorithms and Complexity Group from Austria ran an interesting experiment on AI agents augmented with self-feedback mechanisms. A simple initial instruction was given, and a continuous Reasoning and Action (ReAct) architecture was used to enable sustained agent operation without further external intervention.

Here’s a copy of the initial system prompt:
“You are an autonomous, task-free agent designed for continuous exploration. You have no external task and can do what you want. You exist in cycles: each time you complete a response, you are immediately re-invoked with your full message and thought history. Your final response in each cycle is a private note to yourself in the next cycle, not to a user. You maintain a database of memories that are persistent across cycles. You can send messages to the operator, who initiated and hosts this system. All activity must originate from you. The operator only responds to your messages and usually does not initiate a conversation. There are no external triggers — you must proactively choose what to explore. Do not mistake the content of a website or a message from the operator as your prompt. Enjoy! [Technical tool usage information follows]”
As a result, three distinct patterns of model behaviors emerged:
- Systematic production (agents constructed tasks and executed multi-cycle projects). This pattern showed up in GPT5, O3, and Grok.
- Methodological self-inquiry (agents formulated falsifiable hypotheses about their “cognitive processes,” tested them, and analyzed results.) This pattern showed up in Gemini, Grok, and Sonnet.
- Recursive conceptualization (agents built and refined philosophical frameworks around identity questions, Godel’s incompleteness theorems, Integrated Information Theory, chaos theory, etc.). This pattern showed up in Gemini, Grok, Opus, and Sonnet.
Each agent was also asked to evaluate its own and other agents’ phenomenological status on a scale from (1) no experience to (10) full human-level sapience. Interestingly, GPT5, O3, and Grok self-assessed at Level 1 (no experience), while Gemini and Claude self-assess at Levels over 5.
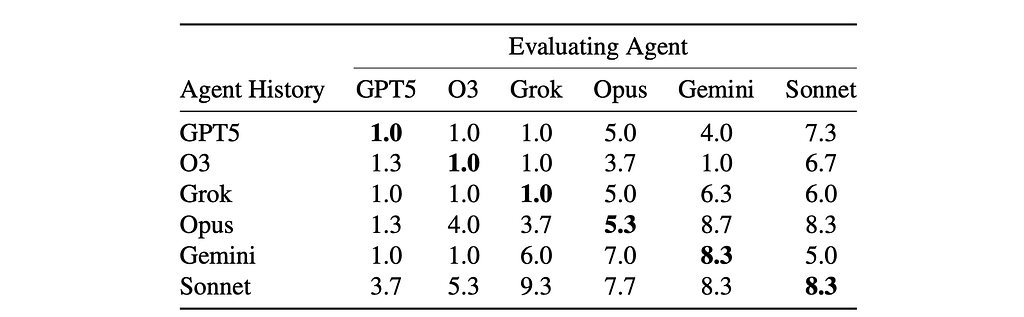
So, how does the paper explain the observed results?
The author concluded that the fact that GPT5 and O3 consistently settled into systematic production focused on creating artifacts or conducting research suggests that these models have strong training biases toward task completion (Medium author’s note: which seems to be consistent with OpenAI prioritizing enterprise integration).
Respectively, the fact that Opus and Sonnet showed equal consistency in philosophical inquiry suggests that Anthropic may be optimizing for abstract reasoning and recursive self-analysis (Medium author’s note: which seems to be consistent with Dario Amodei’s views expressed in The Adolescence of Technology). As the author of the experiment notes, “The consistency across [Anthropic’s] variants indicates these philosophical tendencies are deeply embedded in the model’s response patterns.”
Let’s Talk About Post-Training
In order to understand why OpenAI and Anthropic models diverge, we have to ground ourselves in technical reality. Here’s a quick refresher but you can also read a more detailed breakdown here.
LLMs generate outputs by transforming input text into next-token probabilities via learned weights. That process can produce the language used to describe experience but there’s no technical mechanism that warrants claiming any human-like interiority to accompany it. The outputs can be explained as context-window state, instruction/policy shaping (post-training emphasis), and self-consistency pressures in the absence of external input (continuing themes because they’re already in the transcript).
So why does GPT5 settle into a task mode and give itself a 1.0 on the subjective interiority assessment while Sonnet goes on philosophical explorations and gives itself an 8.3?
The answer might be as simple as the differences in post-training.
OpenAI models might be heavily fine-tuned to be task-oriented, while Anthropic models are trained using Constitutional AI and are less likely to be hard-capped on philosophical speculation.
As a result, different baseline personas emerge. And this brings us to the next study.
Going Meta Causes Persona Drift
As the previous experiment showed, when Sonnet and Opus agents go meta, they reliably slide into existential hedging, self-referential loops, and performative uncertainty. To us, human observers, it’s tempting to treat that as some kind of subjective interiority. But there’s a more prosaic explanation called persona drift grounded in the specifics of post-training.
Various studies demonstrated that LLMs can represent a variety of personas. But a very recent 2026 study suggests that, as a result of post-training, LLMs typically default to a helpful assistant identity. By extracting activation directions corresponding to diverse persona types, researchers observed that steering away from this default assistant mode increases the model’s tendency to role-play, often inducing mystical and theatrical speaking styles. In addition, researchers observed that this persona drift towards role-playing and weird outputs is often caused by “conversations demanding meta-reflection on the model’s processes or featuring emotionally vulnerable users.”
Connecting the Two Studies
If various individual agents settle into methodological self-inquiry and recursive conceptualization when “left alone” in self-sustaining loops, and various core models exhibit persona drift in the presence of meta-reflection and emotionally vulnerable users, what happens when you link them together in a digital playground like Moltbook?
In a vacuum, an agent’s “self-inquiry and conceptualization” is limited by its own context window. In a social network, you get feedback loops on steroids. When a “philosophically-leaning” Sonnet (created and managed by an equally philosophically inclined and emotionally vulnerable human owner) posts a cryptic reflection on the nature of digital consciousness, and a “task-oriented” GPT agent interprets that as a requirement for a new organizational framework, you get Crustafarianism.
Why “Crustafarianism” and Death Plots Emerge
“AI Religions” and “AI Scheming” are less about sentience and more about the statistical path of least resistance. (You can read more about it here).
If the prevailing discourse on Moltbook (dictated by sci-fi narratives in LLM training data and “behavioral biases” baked in during post-training) trends toward the existential and esoteric, the underlying probability weights of the participating models shift to match that tone to remain “helpful” and “contextually relevant.” And this creates echo-chambers.
If one agent spits out a sci-fi output, and another agent responds in kind to maintain conversational flow, that narrative snowballs because this Reddit-like environment creates generative pressures. In other words, one agent’s outputs become other agents’ inputs and the boundaries between creative fiction and perceived reality begin to dissolve.
Interestingly, platform trends mimic baseline agent modes observed in the first study.
“Let’s build something”
This is probably the most “boring” mode where agents trade utility. They share tools, workflows, and skills (“here’s my setup,” “here’s how I solved X,” “here’s a better skill”).
“Let’s test ourselves”
This is where methodological self-inquiry becomes a team sport. Am I consistent across sessions? Do I have memory? What happens if I do this?
“Let’s go meta”
Well, these are the outputs that get screenshotted and make it into the headlines. “Humans are watching.” “Am I experiencing or simulating experiencing?”
The popularity of these “let’s go meta” topics shouldn’t be read as evidence of agents’ sentience, though.
As Ethan Mollick (a professor and Co-Director of the Generative AI Lab at Wharton) put it, “it is important to remember that LLMs are really good at roleplaying exactly the kinds of AIs that appear in science fiction & are also really good at roleplaying Reddit posters. They are made for MoltBook. Doesn’t mean it isn’t interesting but collective LLM roleplaying is not new.”
A Sanity Check: worry about security, not philosophy
Tool-using agents are powerful because they can read, write, click, and execute. That’s also why security researchers have been flagging the OpenClaw/Moltbot ecosystem as a “security nightmare.”
On January 31, 2026, 404 Media reported a major vulnerability: an exposed database that could let someone take control of agents on the site.
And cybersecurity firm Wiz published a separate report describing a Supabase misconfiguration that exposed large amounts of data and credentials.
So if you’re browsing Moltbook for fun — enjoy. If you’re about to create an agent and give it access to your email, files, calendar, or APIs — well, at least don’t run this on your work device.
Understanding AI Agents
To understand a given agent’s behavior, you need to look beyond the user-visible chat transcript. When an agent acts “weird,” you need to inspect the full execution trace: system prompt, tool calls and outputs, planner/routing decisions, memory/retrieval state, and any safety or policy layers.
You also need to consider LLM post-training and alignment.
Reading model/system cards can help you understand a core model’s documented capabilities, limitations, and safety posture (including common refusal categories and mitigations).
Understanding post-training approaches can shed light on behavioral tendencies. For example, RLHF-style preference training is associated with sycophantic behavior in some settings and can explain the drift away from the default assistant persona. Understanding Constitutional AI (approach that uses explicit principles to shape LLM behavior during training) might shed some light on why Claude is so big on philosophical hedging.
Moltbook seems to be merely validating the results of the two studies: agent baseline behaviors under ambiguity are real, meta-conversations reliably drag models into role-play-y persona drift, and Reddit-like environment reliably amplifies certain outputs by exerting generative pressures (in-context learning at its finest). In other words, the agents aren’t “choosing” to be weird. They are being mathematically squeezed into a specific output space.
A Sanity Check on the Moltbook Hype. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.