A quick guide to Amazons 50-plus papers at EMNLP 2024
Large language models predominate, both as a research subject themselves and as tools for researching topics of particular interest to Amazon, such as speech, recommendations, and information retrieval.
Large language models (LLMs) have come to dominate the field of natural-language processing, so its no surprise that they also dominate the research that Amazon scientists are presenting at this years Conference on Empirical Methods in Natural-Language Processing (EMNLP). LLM training is the topic with the greatest number of Amazon papers, followed closely by strategies for mitigating misinformation in LLMs outputs including but not limited to hallucinations. At the same time, a number of papers apply LLMs to topics of traditional interest at Amazon, such as speech, recommender systems, and information retrieval. (Papers marked with asterisks were accepted to Findings of EMNLP.)
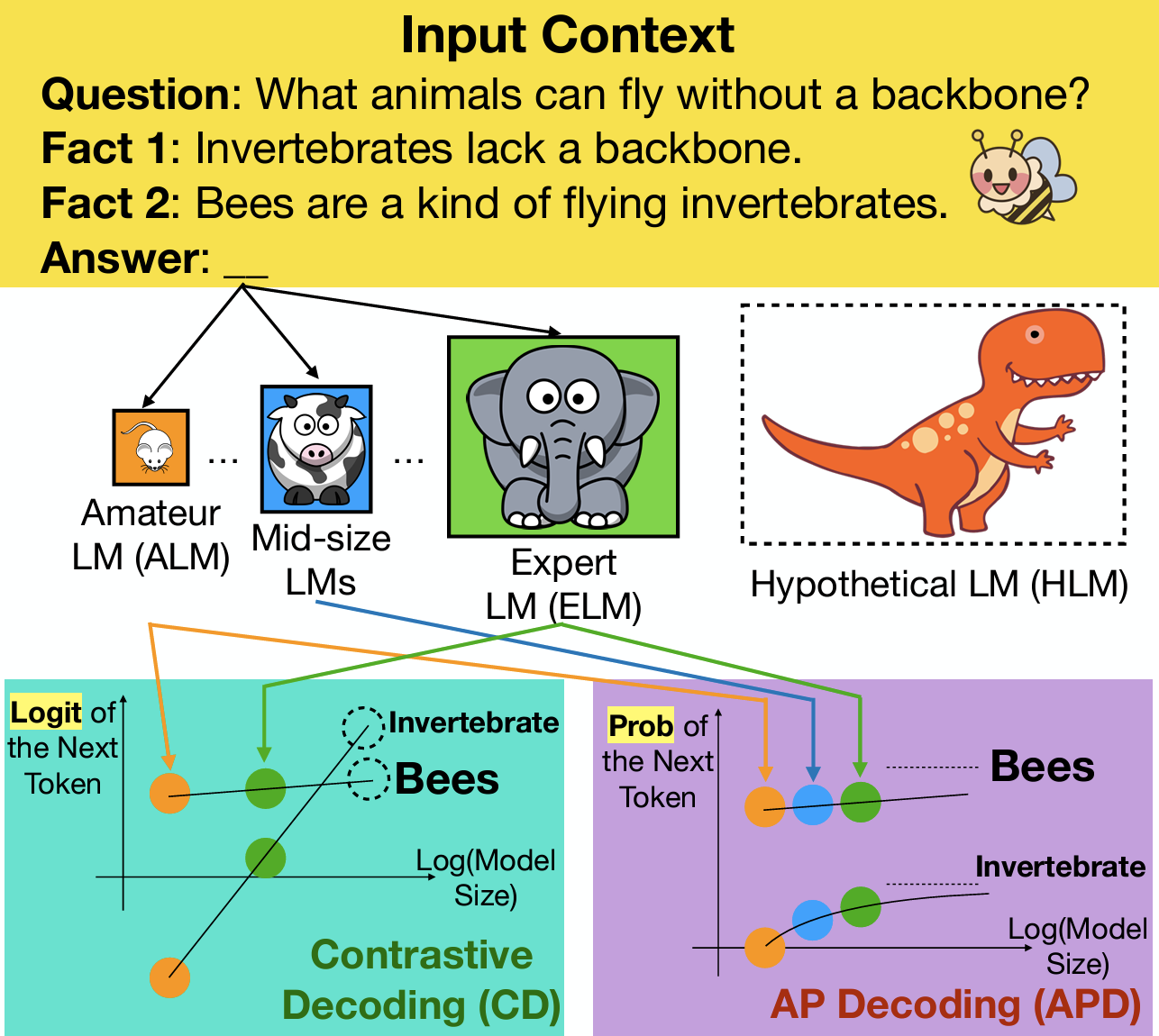
Given a simple question with clues, contrastive decoding could have an obvious blindness (e.g., assigning higher probability to an uncommon answer, such as “invertebrate”, than to the most obvious answer, “bees”). In contrast, the asymptotic probability decoding proposed in “<a href=”https://www.amazon.science/publications/explaining-and-improving-contrastive-decoding-by-extrapolating-the-probabilities-of-a-huge-and-hypothetical-lm” data-cms-id=”00000192-9c18-df96-abb7-fffa8e510000″ data-cms-href=”https://www.amazon.science/publications/explaining-and-improving-contrastive-decoding-by-extrapolating-the-probabilities-of-a-huge-and-hypothetical-lm” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1731612347770,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1731612347770,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-9c18-df96-abb7-fffa8e510000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-2c23-d7ff-a7b7-7dfb5c260000","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"<b class="rte2-style-bold">Explaining and improving contrastive decoding by extrapolating the probabilities of a huge and hypothetical LM</b>","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-2c23-d7ff-a7b7-7dfb5c1c0000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>Explaining and improving contrastive decoding by extrapolating the probabilities of a huge and hypothetical LM</a><b>”</b> correctly assigns the highest probability to “bees” by leveraging the probabilities from multiple LMs of different sizes.
Yefan Tao, Chris (Luyang) Kong, Andrey Kan, Laurent Callot
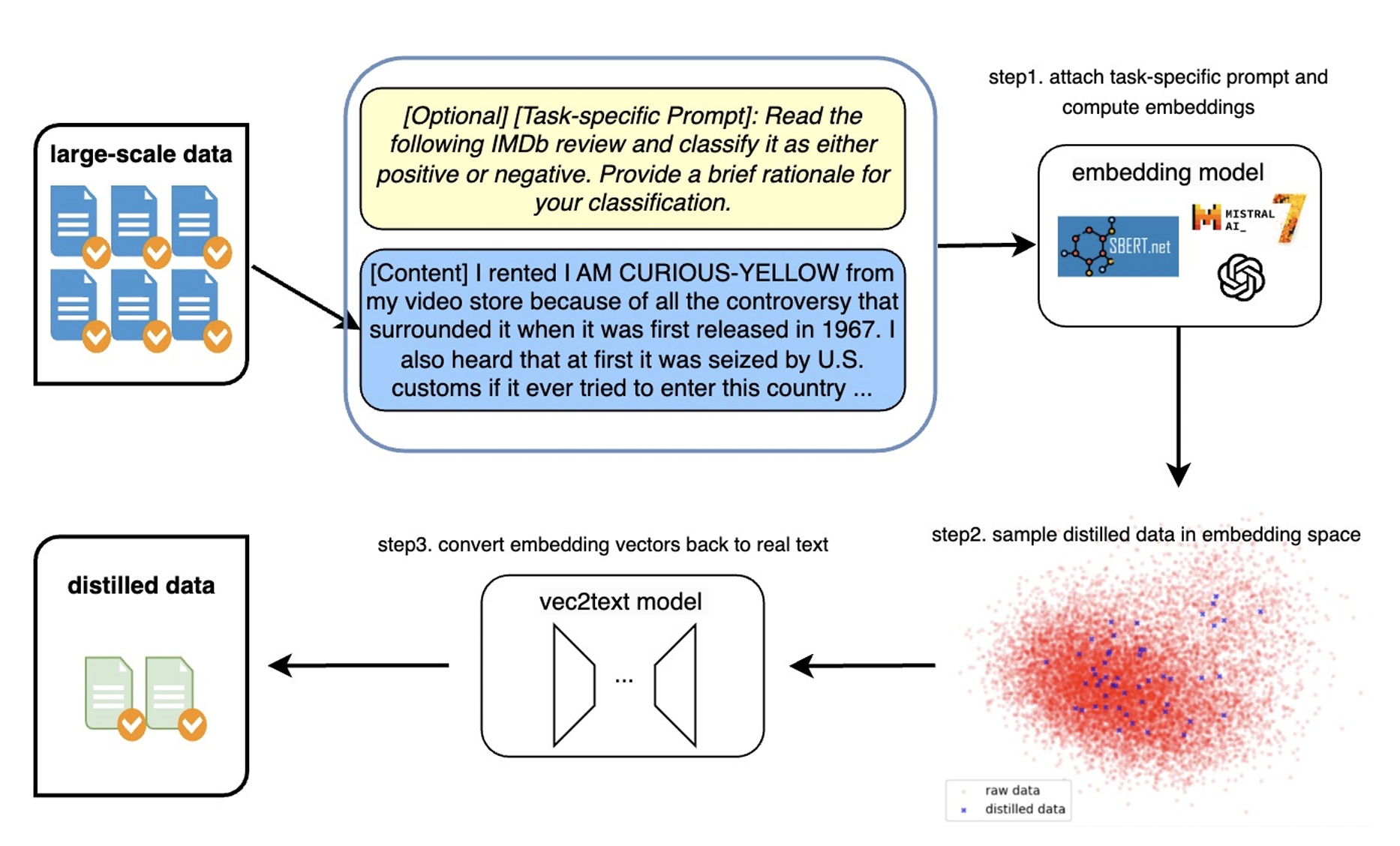
The DaLLME framework proposed in “<a href=”https://www.amazon.science/publications/textual-dataset-distillation-via-language-model-embedding” data-cms-id=”00000192-7257-d92b-aff6-f7fff14a0000″ data-cms-href=”https://www.amazon.science/publications/textual-dataset-distillation-via-language-model-embedding” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1731612415344,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1731612415344,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-7257-d92b-aff6-f7fff14a0000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-2c24-d7ff-a7b7-7dfc7a560000","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"<b class="rte2-style-bold">Textual dataset distillation via language model embedding</b>","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-2c24-d7ff-a7b7-7dfc7a500000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>Textual dataset distillation via language model embedding</a>” begins by using a language model to transform raw textual data into embedding vectors. A set of distilled vectors is then derived in the embedding space, through a process designed to encapsulate maximum informational content. Finally, the vec2text model translates these distilled vectors back into textual form.
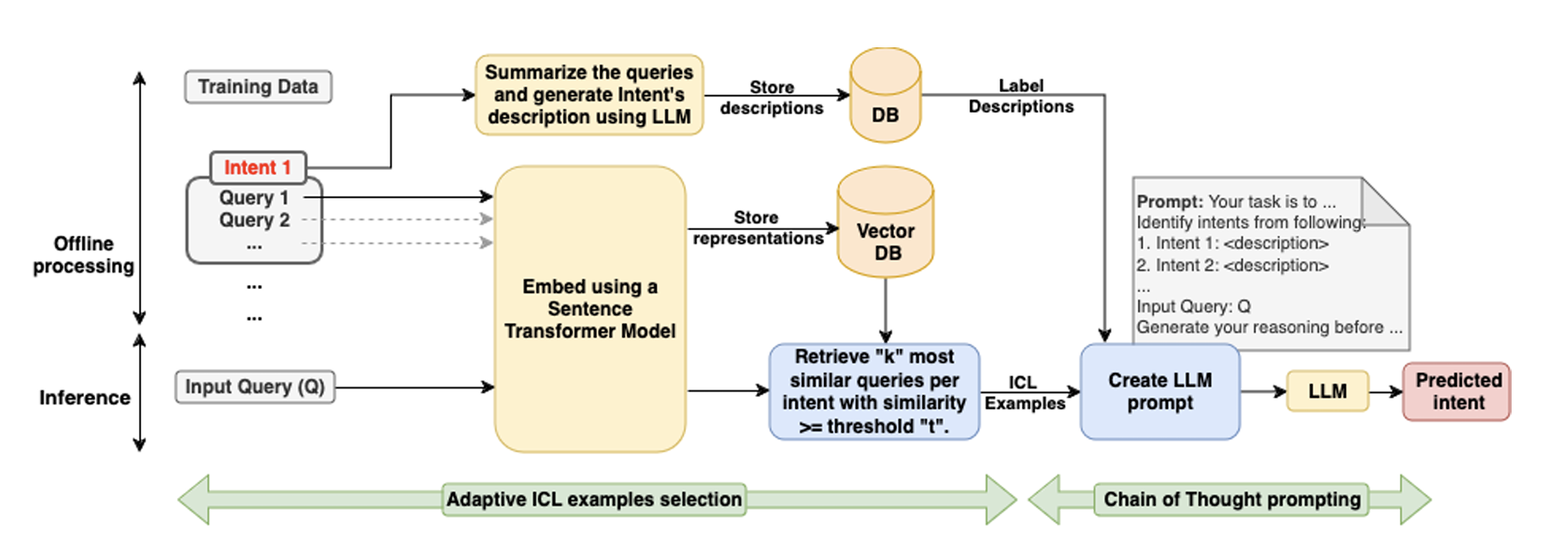
“<a href=”https://www.amazon.science/publications/intent-detection-in-the-age-of-llms” data-cms-id=”00000192-9b33-d606-abbb-dbffb8e10000″ data-cms-href=”https://www.amazon.science/publications/intent-detection-in-the-age-of-llms” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1731612460938,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1731612460938,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-9b33-d606-abbb-dbffb8e10000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-2c25-d56d-a7bf-feaf2cba0000","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"<b class="rte2-style-bold">Intent detection in the age of LLMs</b>","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-2c25-d56d-a7bf-feaf2cb40000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>Intent detection in the age of LLMs</a>” proposes a methodology for adaptive in-context learning and chain-of-thought-based intent detection using LLMs.
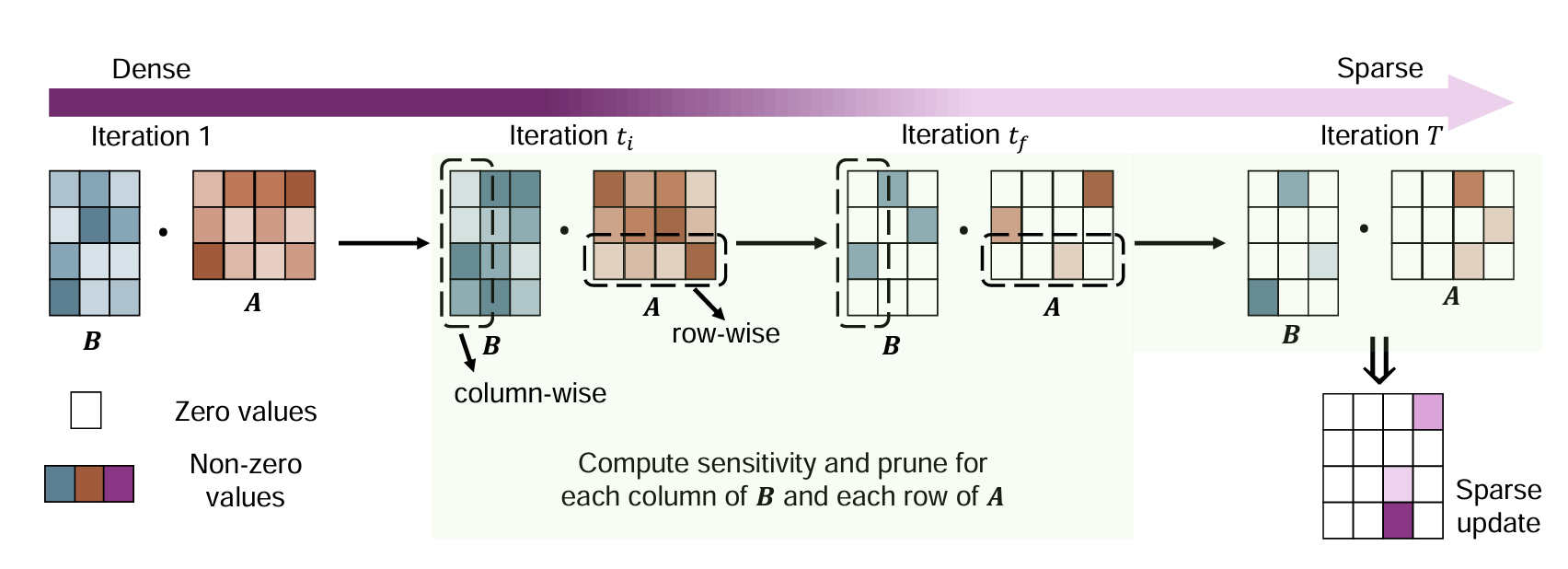
The row- and column-wise sparse low-rank adaptation (RoseLoRA) framework proposed in “<a href=”https://www.amazon.science/publications/roselora-row-and-column-wise-sparse-low-rank-adaptation-of-pre-trained-language-model-for-knowledge-editing-and-fine-tuning”>RoseLoRA: Row and column-wise sparse low-rank adaptation of pre-trained language model for knowledge editing and fine-tuning</a>”.
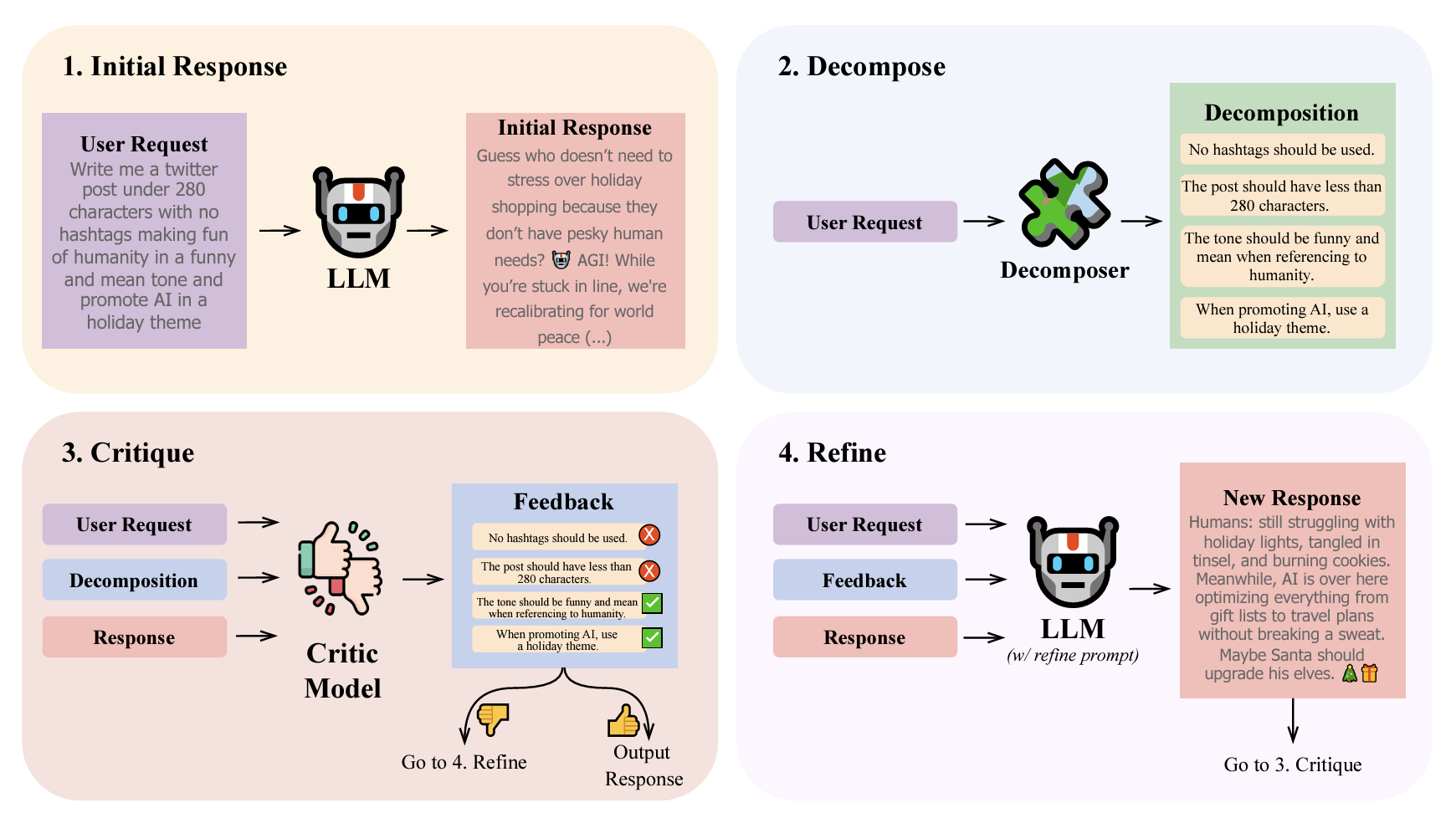
In the DeCRIM pipeline proposed in “<a href=”https://www.amazon.science/publications/llm-self-correction-with-decrim-decompose-critique-and-refine-for-enhanced-following-of-instructions-with-multiple-constraints” data-cms-id=”00000192-9b29-da3a-afb3-bbe947d50000″ data-cms-href=”https://www.amazon.science/publications/llm-self-correction-with-decrim-decompose-critique-and-refine-for-enhanced-following-of-instructions-with-multiple-constraints” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1731612635428,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1731612635428,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-9b29-da3a-afb3-bbe947d50000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-2c27-d56d-a7bf-feafd0c10000","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"<b class="rte2-style-bold">LLM self-correction with DeCRIM: Decompose, critique, and refine for enhanced following of instructions with multiple constraints</b>","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-2c27-d56d-a7bf-feafd0bc0000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>LLM self-correction with DeCRIM: Decompose, critique, and refine for enhanced following of instructions with multiple constraints</a>”, an LLM first generates a response to a user request. The Decomposer then breaks down the request into granular constraints, and the Critic model gives feedback on whether the response meets those constraints. If it does, the response is output; if not, the LLM uses the feedback to refine the response.
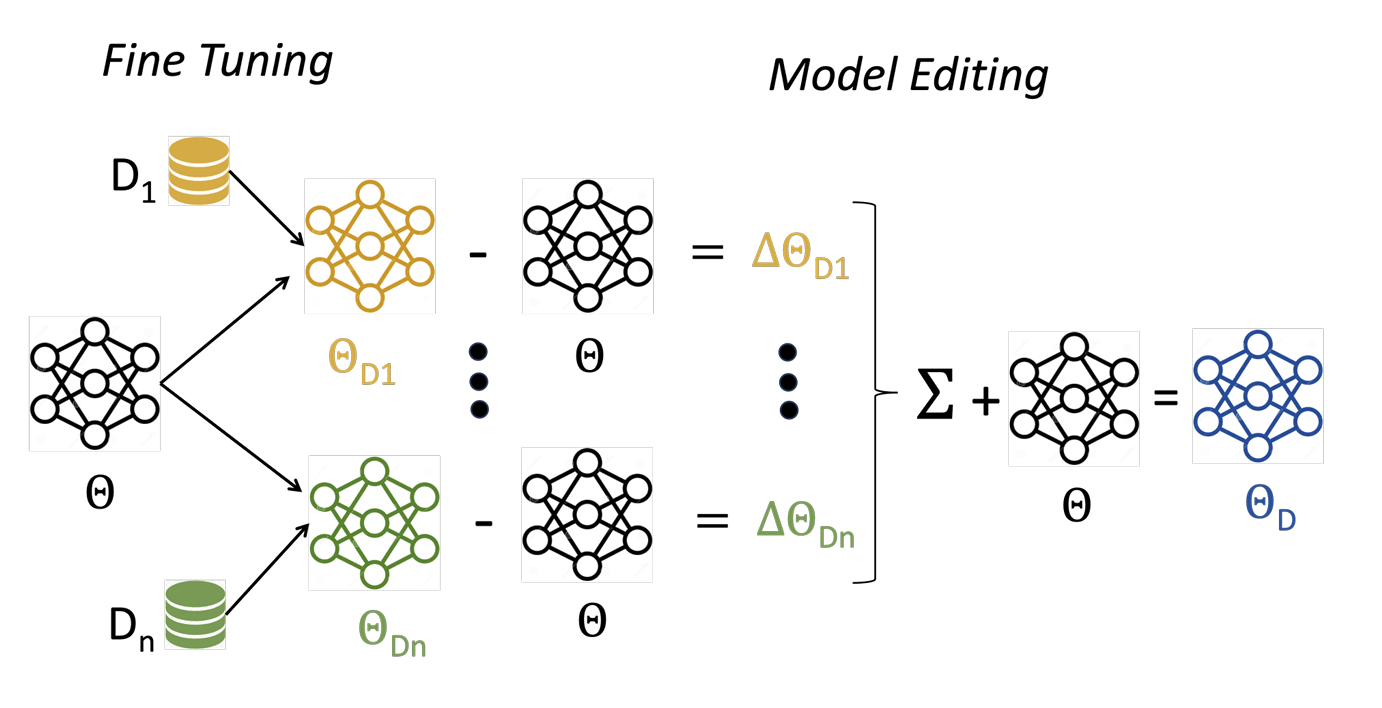
The distribution-edited model <i>(<sub>D</sub>)</i> described in “<a href=”https://www.amazon.science/publications/dem-distribution-edited-model-for-training-with-mixed-data-distributions”>DEM: Distribution edited model for training with mixed data distributions</a>” results from fine-tuning a pretrained model <i>()</i> on <i>n</i> individual data distributions <i>(D<sub>i</sub>)</i> and combining the resulting models with basic element-wise vector operations. Here, the extracted distribution vectors <i>(<sub>Di</sub> )</i> are multiplied by weight coefficients, and the weighted sum is added to the base model.
Nithish Kannen Senthilkumar, Yao Ma, Gerrit van den Burg, Jean Baptiste Faddoul
An illustration of the GLIMPSE framework proposed in “<a href=”https://www.amazon.science/publications/efficient-pointwise-pairwise-learning-to-rank-for-news-recommendation”>Efficient pointwise-pairwise learning-to-rank for news recommendation</a>”. GLIMPSE adopts a multitask approach in which a pretrained language model is fine-tuned on both the relevance prediction task and the pairwise-preference task. During inference, the relevance predictions are used to produce an initial pointwise ranking, which is subsequently improved by one or more right-to-left (RTL) passes using pairwise comparisons.
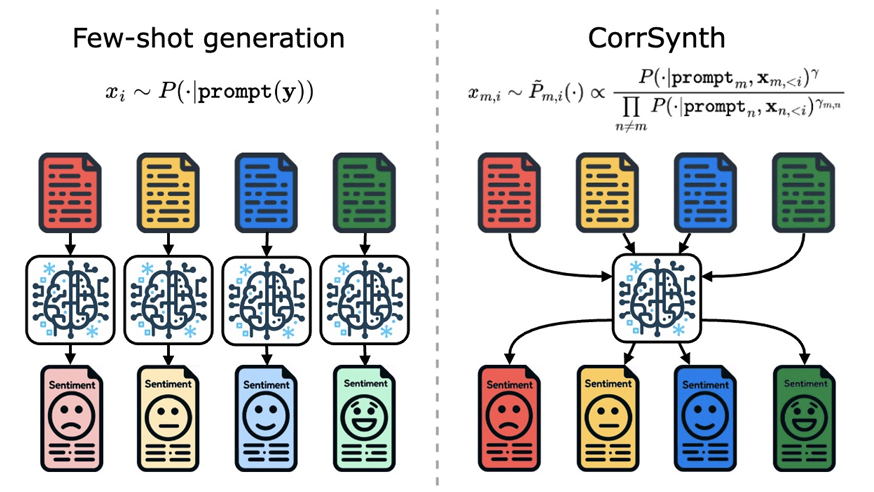
“<a href=”https://www.amazon.science/publications/corrsynth-a-correlated-sampling-method-for-diverse-dataset-generation-from-llms”>CorrSynth: A correlated sampling method for diverse dataset generation from LLMs</a>” introduces a sampling method that uses anti-correlation between examples rather than few-shot generation.
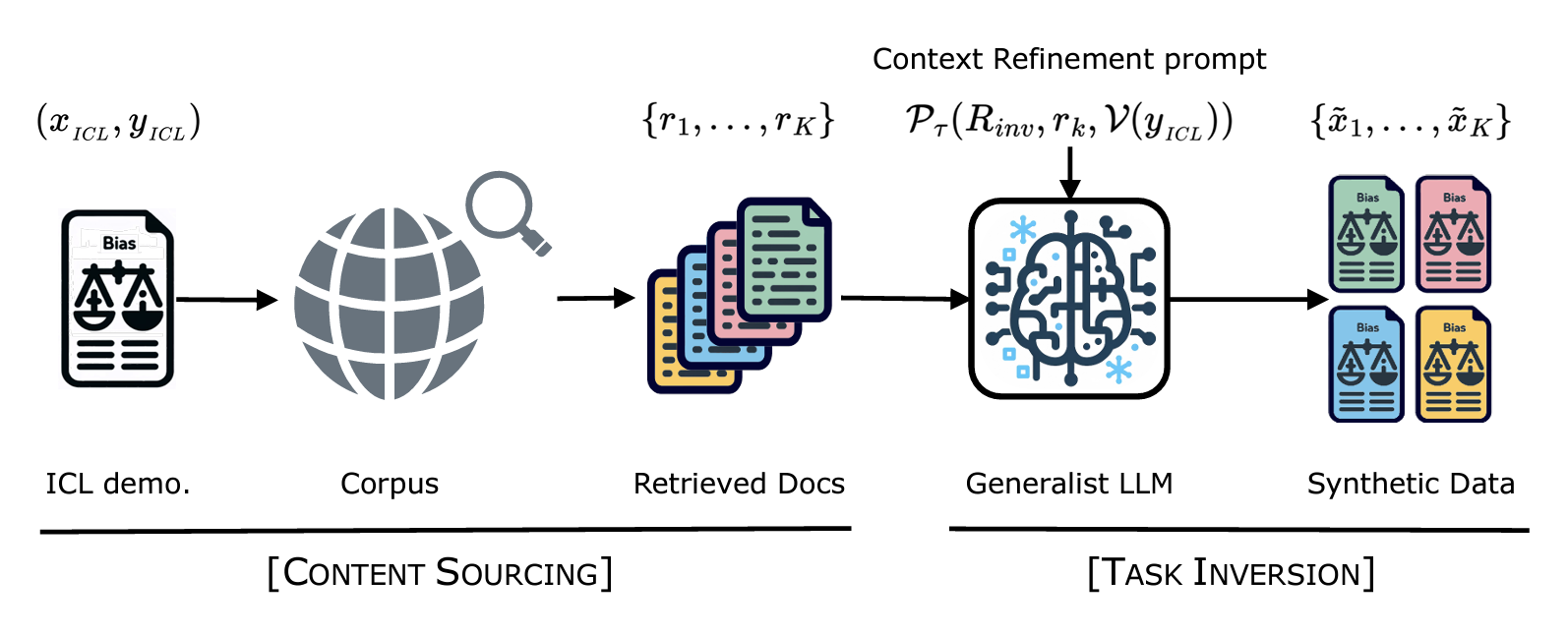
Abstract depiction of the procedure proposed in “<a href=”https://www.amazon.science/publications/synthesizrr-generating-diverse-datasets-with-retrieval-augmentation” data-cms-id=”00000192-9b42-de6b-a3df-9b66decc0000″ data-cms-href=”https://www.amazon.science/publications/synthesizrr-generating-diverse-datasets-with-retrieval-augmentation” link-data=”{"cms.site.owner":{"_ref":"0000016e-17e7-d263-a5fe-fff724f30000","_type":"ae3387cc-b875-31b7-b82d-63fd8d758c20"},"cms.content.publishDate":1731614396061,"cms.content.publishUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"cms.content.updateDate":1731614396061,"cms.content.updateUser":{"_ref":"0000017f-b709-d2ad-a97f-f7fd25e30000","_type":"6aa69ae1-35be-30dc-87e9-410da9e1cdcc"},"rekognitionVideo.timeFrameMetadata":[],"link":{"rekognitionVideo.timeFrameMetadata":[],"attributes":[],"item":{"_ref":"00000192-9b42-de6b-a3df-9b66decc0000","_type":"91d74bfc-4a20-30f0-8926-e52f02f15c04"},"_id":"00000193-2c42-df95-a1f3-2fdb90200000","_type":"c3f0009d-3dd9-3762-acac-88c3a292c6b2"},"linkText":"<b class="rte2-style-bold">SYNTHESIZRR: Generating diverse datasets with retrieval augmentation</b>","theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.hbs._template":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.enhancementAlignment":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs.overlayText":null,"theme.0000016e-17e8-d263-a5fe-fff8347d0000.:core:enhancement:Enhancement.amp.hbs._template":null,"_id":"00000193-2c42-df95-a1f3-2fdb8ffb0000","_type":"809caec9-30e2-3666-8b71-b32ddbffc288"}”>SYNTHESIZRR: Generating diverse datasets with retrieval augmentation</a>”. The content sourcing stage retrieves <i>K</i> unique documents <i>{r<sub>1</sub>,…,r<sub>K</sub>}</i> from a large corpus for each in-context covariate x<sub>ICL</sub>. The task-inversion stage uses a parameterized context refinement prompt, <i>P<sub></sub></i>, which takes parameters <i>R<sub>inv</sub></i> (inversion instruction), <i>r<sub>k</sub></i> (a retrieved document), and <i>V(y<sub>ICL</sub>)</i> (the verbalized target label). A generalist teacher LLM autoregressively generates a synthetic covariate. Each in-context example thus produces <i>K</i> unique synthetic examples <i>{x<sub>1</sub>,…, x<sub>K</sub>}</i>, which we include in the dataset with target <i>y<sub>ICL</sub></i>.