
Context Rot: Why Longer Windows Are Making Your AI Dumber, Not Smarter
Your million-token context window isn’t a superpower — it’s a liability you haven’t measured yet.
The promise that didn’t quite deliver
Two years ago, a 200,000-token context window felt like magic. Today it’s table stakes — some models now advertise windows in the millions of tokens. The pitch is seductive: stuff in your entire codebase, your whole knowledge base, every past conversation, and the model will just know everything.
But engineers running these systems in production are noticing something uncomfortable. Bigger context isn’t making outputs better. Past a certain point, it’s making them worse — vaguer, less precise, more prone to ignoring the one instruction that actually mattered. This phenomenon has a name now: context rot.
It’s one of the more counterintuitive failure modes in modern AI engineering, and it’s worth understanding precisely, because the fix isn’t “use a smaller window.” It’s a fundamentally different way of thinking about what context is for.
What context rot actually is
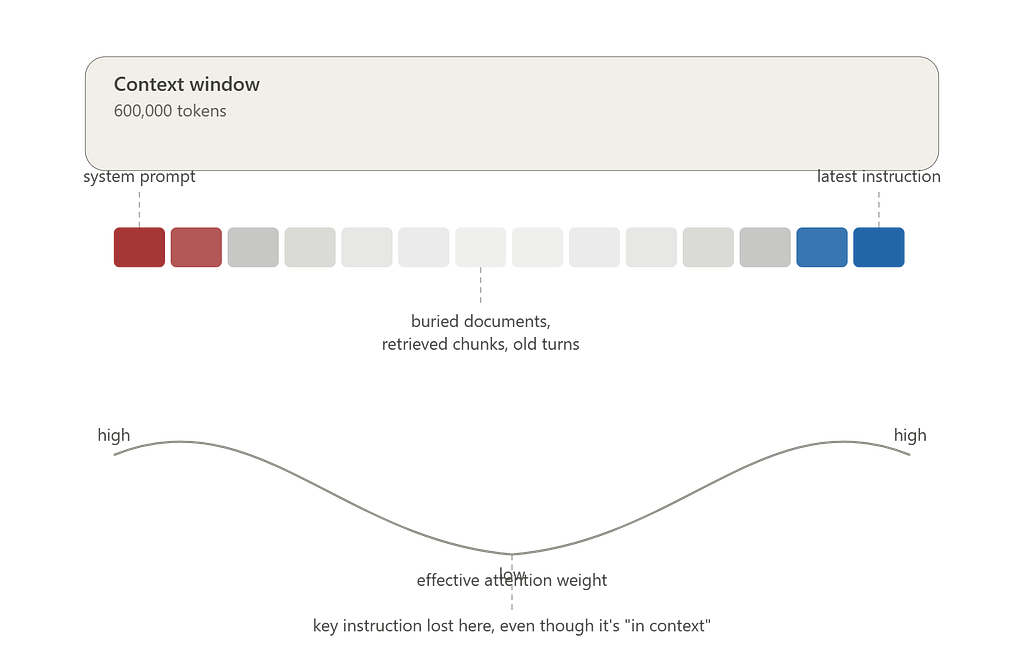
Context rot describes the degradation in a model’s effective reasoning quality as the amount of information in its context window grows — even when that window is technically far from full.
The key word is effective. A 1-million-token window doesn’t mean the model uses all million tokens equally well. Attention is not free, and it is not uniform. Every additional token a model has to weigh against every other token adds computational and representational burden. As context grows, the model’s ability to identify which tokens actually matter for the current task gets diluted.
This isn’t a hand-wavy intuition — it shows up in measurable ways:
- Instruction-following degrades. A directive given early in a long context gets less weight than one given near the end, regardless of importance.
- Retrieval becomes lossy. Models reliably find information placed at the start or end of context far better than information buried in the middle — a pattern researchers have called the “lost in the middle” effect.
- Irrelevant content actively interferes. It’s not just that extra tokens are ignored; they can actively pull the model’s attention away from the relevant signal, similar to noise drowning out a conversation.
- Latency and cost rise even when quality doesn’t, since processing scales with context length regardless of whether that context helped.
So you end up paying more, waiting longer, and getting answers that are subtly worse. That’s the trap.
Why this happens: a mechanical explanation
To understand context rot, it helps to understand what attention mechanisms are actually doing. In a transformer, every token attends to every other token to decide what’s relevant. As the number of tokens grows, the number of these pairwise relationships grows quadratically. The model has to spread its “attention budget” across a much larger space.
Think of it like a meeting. With three people in the room, everyone can track the full conversation and contribute meaningfully. With three hundred people in the room, even if everyone is technically “present” and the room is large enough to fit them, no individual statement carries the same weight. The signal-to-noise ratio collapses — not because the room got worse, but because relevance got diluted across far more competing inputs.
Long-context models are also typically trained on different data distributions than they’re tested on. Most training examples don’t look like “here are 80,000 tokens of loosely related documentation, find the one paragraph that answers this question.” Models get good at long-context retrieval benchmarks because those benchmarks get optimized for — but real-world long-context use is messier, more ambiguous, and less structured than synthetic benchmarks suggest.
Where engineers are feeling this in practice
If you’re building agentic systems, RAG pipelines, or anything with multi-turn memory, context rot shows up in specific, recognizable ways:
Agent memory bloat. An agent that accumulates its entire conversation and tool-call history into context will, after enough turns, start losing track of its original goal. The instructions from turn one get buried under fifty turns of tool outputs and intermediate reasoning.
Naive RAG over-retrieval. A common mistake is assuming “more retrieved chunks = more context = better answer.” In practice, dumping fifteen marginally relevant chunks into a prompt often produces a worse answer than three highly relevant ones, because the model has to do the disambiguation work you should have done at retrieval time.
System prompt erosion. Long conversations bury carefully crafted system instructions under accumulated chat history, and the model’s adherence to those original instructions visibly weakens as the conversation extends.
Codebase dumping. Feeding an entire repository into context, rather than the relevant files, tends to produce code suggestions that are technically plausible but miss the actual architectural patterns the codebase actually uses — because the truly relevant precedent is buried among hundreds of irrelevant files.
The fix isn’t smaller context — it’s curated context
The instinct might be to roll back to short contexts. That’s the wrong lesson. The actual discipline being demanded here is context engineering — treating what goes into the window with the same rigor you’d treat function arguments in a well-designed API.
A few principles that hold up well in practice:
1. Relevance over volume. Retrieve and include the minimum set of information that answers the task, not the maximum set that might be relevant. This is harder than it sounds — it requires good retrieval ranking, not just retrieval recall.
2. Position matters — use it deliberately. Since models weight the start and end of context more heavily, put your most critical instructions and the most decision-relevant information there. Don’t bury the directive in the middle of a wall of supporting material.
3. Summarize, don’t accumulate. For long-running agents, periodically compress conversation history into a structured summary rather than carrying the full raw transcript forward indefinitely. This is the difference between an agent that “remembers what matters” and one that’s dragging dead weight.
4. Separate memory from context. Long-term facts an agent needs don’t all belong in the live context window. Externalize them — into a vector store, a structured memory module, a scratchpad file — and pull them in selectively, on demand, rather than keeping everything live at all times.
5. Treat context window size as a budget, not a target. Just because a model supports a million tokens doesn’t mean filling it is the goal. The right question is always “what’s the smallest, highest-signal context that solves this task,” not “how much can I fit.”
The deeper shift this represents
Context rot is forcing a maturity step in how AI systems get built. The first generation of LLM applications treated context length as a brute-force lever — bigger window, fewer engineering decisions, just throw everything in and let the model figure it out.
The systems that are actually reliable in production don’t work that way. They look more like well-designed information architectures: retrieval that’s precise rather than exhaustive, memory that’s structured rather than raw, and prompts that respect the model’s actual attention dynamics rather than assuming infinite, uniform comprehension.
Longer context windows are a genuinely useful capability. But capability isn’t the same as default behavior. The engineering skill that’s emerging — and the one that’s going to separate competent AI engineers from the rest — isn’t “how do I use the full window.” It’s knowing when not to.
Context Rot: Why Longer Windows Are Making Your AI Dumber, Not Smarter was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.