
Mastering the ML Lifecycle
If you are building machine learning models or deploying complex AI agents today, your biggest enemy isn’t the math — it’s the chaos.
In the early days of data science, managing code, datasets, hyperparameter sweeps, and weights felt like trying to organize a library where everyone throws books wherever they want. Tracking who trained what, with which data, and why a model suddenly failed in production was a logistical nightmare.
Enter MLflow. Originally created by Databricks, MLflow has matured into the planet’s most widely adopted open-source MLOps and LLMOps lifecycle platform. Moving into its MLflow 3.x architecture era, it has evolved from a simple experiment tracker into a unified engineering canvas for production-grade traditional machine learning, deep learning, and multi-agent AI ecosystems.
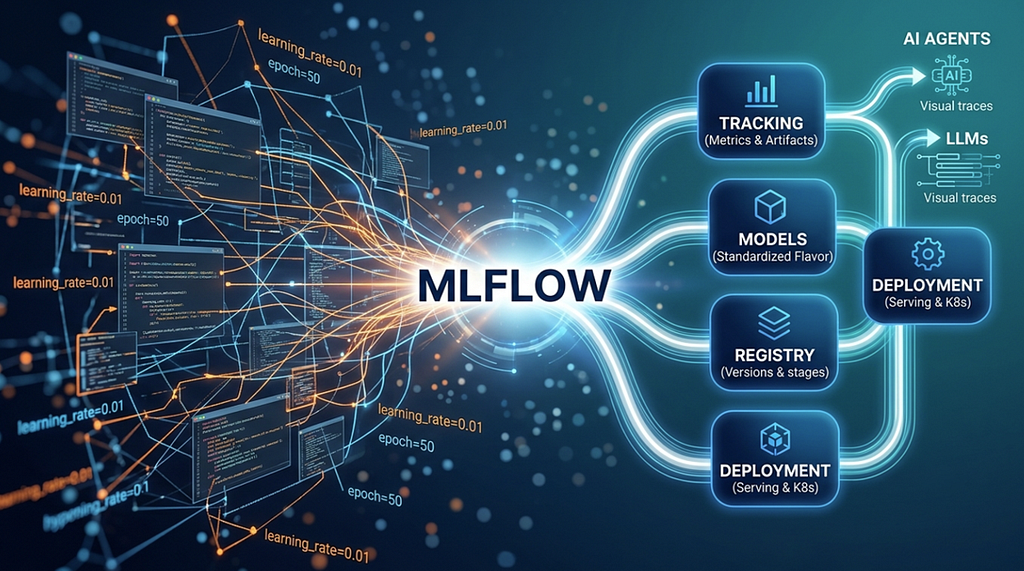
1. The Core Architecture: The Four Foundational Pillars
MLflow’s core philosophy is platform agnosticism. Whether you code in Python, Java, or R, and whether you deploy to AWS, Google Cloud, Azure, or on-premise Kubernetes, MLflow structures your workflow through four primary components:
┌──────────────────────────────┐
│ YOUR ML/AI CODE │
└──────────────┬───────────────┘
│
┌───────────────────────┼───────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ TRACKING │ │ MODELS │ │ REGISTRY │
│ Parameters, │ │ Flavors, │ │ Centralized │
│ Metrics, Diffs │ │ Environments, │ │ Versioning & │
│ & Artifacts │ │ Metadata │ │ Stage Control │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
└───────────────────────┼───────────────────────┘
│
▼
┌─────────────────┐
│ DEPLOYMENT │
│ Docker, K8s, │
│ Real-Time APIs │
└─────────────────┘
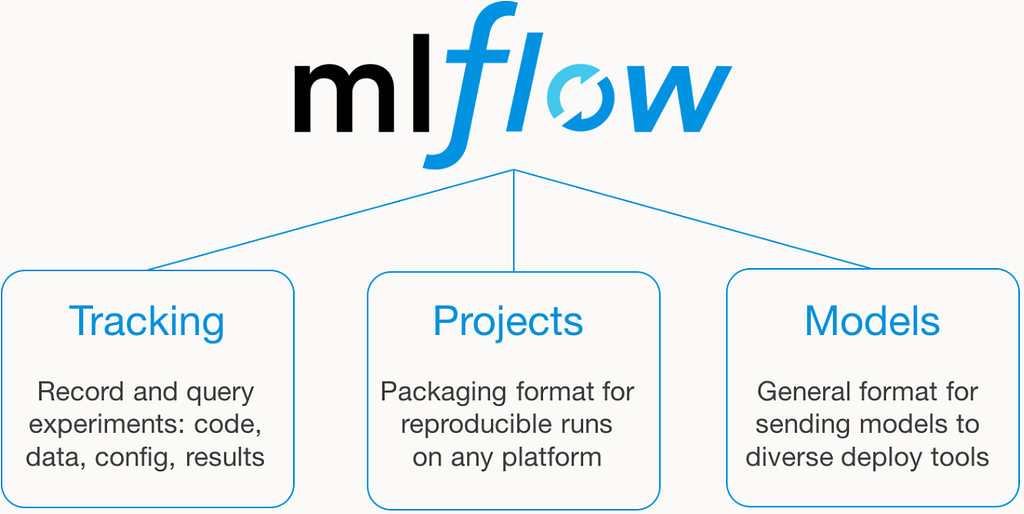
MLflow Tracking
Tracking acts as your flight data recorder. By dropping a single line of code into your script (mlflow.autolog()), MLflow automatically hooks into libraries like Scikit-learn, PyTorch, XGBoost, or Hugging Face. It seamlessly captures:
- Parameters: Learning rate, batch size, network architecture dimensions.
- Metrics: Training loss, validation accuracy, F1-scores across epochs.
- Artifacts: Confusion matrix plots, training logs, data schemas, and the saved weights themselves.
MLflow Models
An MLflow Model is a standardized packaging format. It abstracts the saved file structure using “flavors”. For example, if you save a model as a mlflow.pytorch flavor, it can be loaded back natively into PyTorch for further training, or seamlessly wrapped as a generic python_function (pyfunc) for downstream deployment pipelines without changing a line of production code.
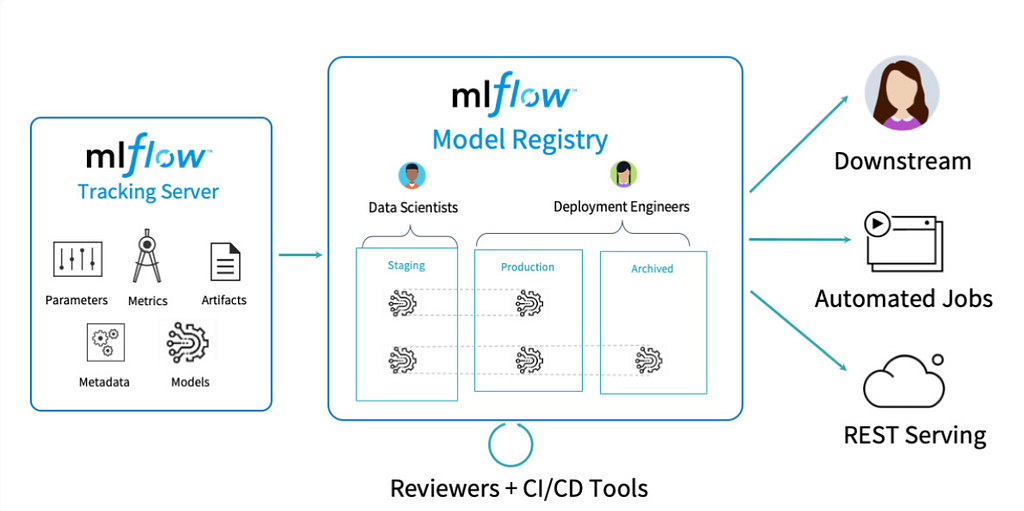
MLflow Model Registry
The Registry provides a central, organization-wide repository for model governance. It handles team-based approval workflows, automated version increments, and explicit stage categorization (e.g., Staging, Production, Archived). In the latest architecture updates, models have graduated to “first-class citizens,” removing the legacy constraint where a model registry entry had to be tied directly to an active experiment run.
MLflow Deployment
Once a model is registered, MLflow simplifies serving. With native commands, you can turn a packaged model into a highly scalable, production-ready FastAPI REST endpoint, containerize it instantly using Docker, or launch it directly onto orchestration clusters via Kubernetes.
2. The 2026 Shift: Enter LLMOps & Autonomous Agents
The industry has rapidly advanced from traditional static tabular data tracking toward complex language model pipelines, multi-agent frameworks, and real-time retrieval-augmented generation (RAG) loops. MLflow has adapted aggressively to meet these needs, shifting the definition of observability.
The LLMOps Pipeline: When deploying an AI agent today, tracking a single output metric is no longer enough. You need to see the entire line of reasoning — how the user prompt was formatted, what semantic fragments were pulled from a vector database, what tool calls were executed, and how the final agentic response was stitched together.
[ User Input Prompt ]
│
▼
┌─────────────────────┐
│ AGENT RUNTIME │ <─── Trace Span 1
└──────────┬──────────┘
│
┌─────────────────────┴─────────────────────┐
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Vector DB Query │ <── Trace Span 2 │ LLM Generation │ <── Trace Span 3
└─────────────────┘ └─────────────────┘
To manage this complex environment, the toolset has evolved with critical production features:
- Production Tracing over OpenTelemetry: MLflow embeds native, low-latency, end-to-end tracing across language model application layers. It supports one-line automatic tracing for dominant agent execution frameworks like LangChain, LangGraph, OpenClaw, and Claude Code.
- Multimodal Trace Attachments: Modern production environments process more than just plain text. MLflow’s trace dashboards provide click-to-expand image modals, audio playback controls, and multi-part chat token visualization directly within execution spans — allowing developers to see exactly what their visual or voice agents saw.
- AI Gateway with Built-in Guardrails: Instead of forcing developer teams to manage dozens of direct API keys for external models (OpenAI, Anthropic, Gemini, Bedrock), MLflow acts as a unified central reverse proxy. The gateway handles rate-limiting, secure credential rotation, traffic splitting for A/B testing, and pre-/post-LLM execution Guardrails to catch toxic or unsafe inputs before they hit your compute runtime.
3. High-Scale Infrastructure & Governance
For engineering teams self-hosting MLflow across enterprise architectures, managing resource constraints is paramount. The platform balances performance and data volume with native cloud-native tooling:
Role-Based Access Control (RBAC)
Sharing a self-hosted tracking server used to mean managing access manually per resource. MLflow features a complete web-driven Admin UI providing deep RBAC mapping. Workspace administrators can define reusable, granular permission bundles covering specific models, experiments, and gateway endpoints without manipulating complex backend REST endpoints.
Policy-Driven Trace Archival
In high-concurrency production spaces, logging thousands of traces per second will quickly bloat metadata SQL backends (such as PostgreSQL). To protect database health, MLflow implements background auto-archival policies. It keeps the active working window clean while automatically migrating older historical trace data out of transaction databases into cost-efficient long-term object storage (like AWS S3 or Google Cloud Storage) — keeping all traces completely readable and searchable inside the main UI on demand.
Why MLflow Dominates the Ecosystem
The ultimate reason MLflow remains an undisputed standard for machine learning teams is simple: it respects developer freedom.
It does not lock you into a single proprietary cloud vendor, forced infrastructure layer, or specific library architecture. It is a reliable open-source standard built to provide absolute structural clarity, compliance, and reproducible order across your entire machine learning stack — whether you’re optimization-tuning a lightweight Scikit-learn regression model or orchestrating an interconnected swarm of autonomous AI agents.
Reference:
1. https://mlflow.org/genai/
2. https://www.databricks.com/blog/2020/04/15/databricks-extends-mlflow-model-registry-with-enterprise-features.html
Mastering the ML Lifecycle was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.