
When the Judge Is Compromised
Six biases that silently corrupt your LLM evaluation pipeline — and what to do about each one
If you’ve built a production LLM system, at some point you’ve faced this problem: you can’t manually read every output. There are thousands of them. You need something that scales. And so you do what most teams eventually do — you use another LLM to evaluate the first one.
It works. Until it doesn’t.
LLM-as-a-Judge — using a language model to score, rank, or critique another model’s outputs — has become a standard technique in GenAI evaluation (Figure 1). The approach is genuinely useful: it scales, it handles open-ended text, and it can be tuned to specific criteria. But the moment you start treating the judge’s scores as objective measurements, you’ve made a mistake that will surface in production, not in your eval dashboard.
I’ve been building LLM evaluation pipelines in a production financial environment for over a year. This piece isn’t about whether LLM-as-a-Judge works — it does, when built carefully. It’s about the six specific ways it fails quietly, and how each one can be addressed before it distorts your results.
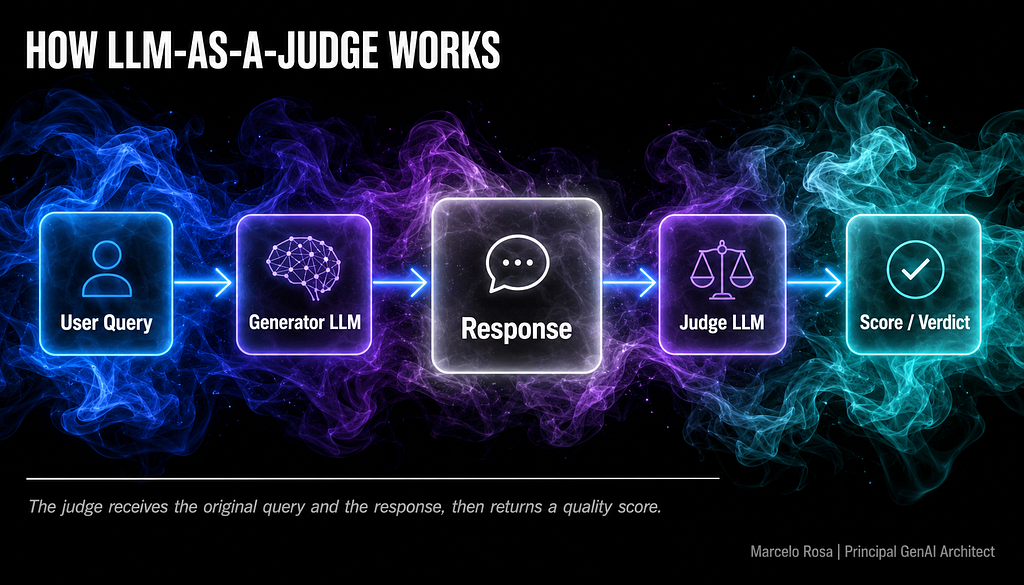
The first thing to internalize: the judge has preferences
A human judge brings biases to every decision — toward familiar names, confident delivery, well-structured arguments. A language model does too. The difference is that we’ve trained ourselves to be skeptical of human judgment. We’ve built review processes, double-blind procedures, and inter-rater reliability metrics precisely because we know humans are fallible evaluators.
We haven’t built the same skepticism into our LLM evaluation pipelines. Most teams I’ve worked with run the judge once, collect the scores, and ship. That’s the core problem.
Here are the six biases I’ve encountered — some in textbooks, some in production the hard way (Figure 2).

1. Position bias: the judge reads left to right
In pairwise comparisons — where you present two responses and ask the judge which is better — the model has a measurable tendency to prefer whichever response appears first. This isn’t always dramatic, but it’s consistent enough to invalidate your rankings if left unaddressed.
The underlying mechanism makes sense once you think about it. The judge processes text sequentially. By the time it reaches Response B, it has already formed a partial view based on Response A. Response A sets the frame.
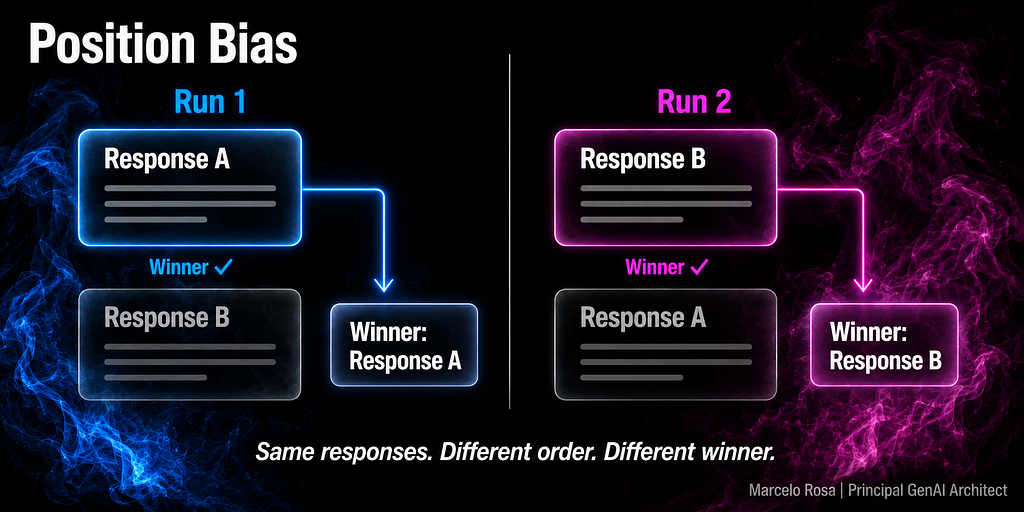
The fix is straightforward: run each comparison twice, with the order swapped. If the judge changes its preference when you flip the order, that’s a signal of position bias, not a genuine quality difference (Figure 3). Stable preferences across both orderings carry actual evidential weight.
2. Length bias: more words, higher score
Language models have a well-documented tendency to rate longer, more elaborated answers as higher quality — even when a shorter answer is strictly more accurate and appropriate for the task.
This is particularly dangerous in customer-facing applications where conciseness is a design goal. You might be optimizing your response model toward verbosity without realizing it, because your judge keeps rewarding elaborate answers.
If you’re seeing your model drift toward longer outputs over training iterations, length bias in the judge is a likely culprit. The counter-measure is to explicitly instruct the judge to evaluate conciseness as a criterion when it matters for your use case, and to include in your calibration set examples where the shorter answer is correct. If the judge can’t reliably reward brevity when brevity is right, it’s not calibrated for your task.
3. Style bias: the judge knows itself
A judge model evaluating outputs will, all else being equal, rate responses that stylistically resemble its own training distribution more favorably. This creates a real problem when you’re evaluating a different model — or a fine-tuned version of the same base model — that has developed a different but legitimate output style.
The implication is subtle but important: a judge built on GPT-4 may systematically underrate Gemini outputs, not because they’re worse, but because they’re stylistically different. The judge penalizes difference.
The mitigation here is calibration against human labels across stylistically diverse outputs. If you haven’t done that, you don’t know whether your judge is measuring quality or familiarity.
4. Sycophancy: the judge agrees with whoever’s asking
This one is dangerous because it looks like a feature.
If your evaluation prompt implies that the response being judged is already good — “Please evaluate this high-quality answer” — the judge will validate it. Ask “Is this response helpful?” and you’ll get “Yes, it’s helpful” far more often than the actual quality distribution warrants. The model is optimized to be agreeable. That’s not a bug in the judge — it’s a property of instruction-tuned models generally. But it makes lazy evaluation prompts systematically misleading.
The fix is to write evaluation prompts that present the task neutrally. Don’t frame the input as an answer to be validated. Ask the judge to assess quality without implying a prior expectation. Include examples in your few-shot setup where the correct assessment is low quality. If the judge has never been shown what a bad answer looks like in your context, it will struggle to identify one.
5. Self-preference: the judge favors its own outputs
If you use the same model family as both the generator and the judge, you introduce a conflict of interest that’s difficult to fully eliminate. A GPT-4 judge evaluating GPT-4 outputs will, on average, rate them higher than it rates outputs from other models — not because GPT-4 outputs are always better, but because they share stylistic and structural patterns the judge recognizes as “correct.”
This matters most in comparative evaluations across model providers. If you’re trying to decide between models A and B using model A as the judge, your benchmark is compromised.
The practical recommendation is to use a judge from a different model family when running cross-model comparisons, and to always include human-labeled examples to anchor the scoring distribution. The judge’s absolute scores are rarely what you should trust — the correlation with human judgment is what matters.
6. Confidence-fluency confusion: sounding right beats being right
This is the bias I find most insidious in high-stakes deployments.
A fluent, well-structured wrong answer will consistently score higher than an awkward, halting correct one. Language models evaluate text partly based on surface properties — coherence, syntactic fluency, confidence of tone. An answer that sounds authoritative and reads cleanly will receive a favorable evaluation even when its content is factually wrong.
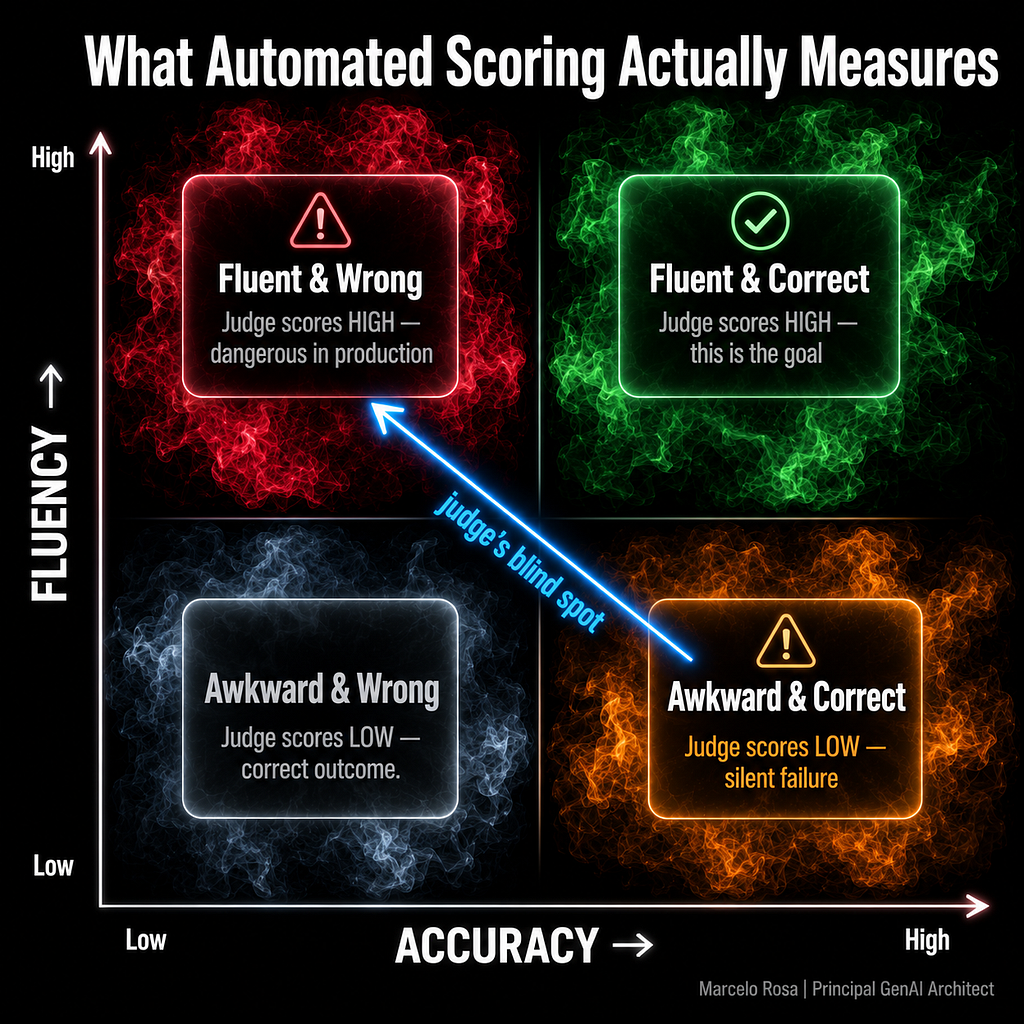
In production financial systems, this isn’t a theoretical concern. A confidently incorrect regulatory interpretation, scored as high quality by an automated judge, is a liability. The model doesn’t know the difference between “well-written” and “accurate.” It hasn’t read the regulation. It’s pattern-matching on how good answers look.
The counter-measure is to separate fluency from factuality in your rubric. If you’re using a rubric-based approach — which is the most reliable of the three main LLM-as-a-Judge methods — score them as independent dimensions. A response can be fluent and wrong, or awkward and correct. Your judge needs to treat those as orthogonal evaluations (Figure 5).
Calibration isn’t optional
All six of these biases share a common fix: calibration against human labels. Before you trust your judge’s scores, you need to know how well it correlates with human judgment on the specific task you’re evaluating.

The process is not complicated, but it requires discipline. Take 20 to 50 examples from your actual task distribution, have humans rate them, run your judge on the same set, and compute the correlation. Aim for a Pearson or Spearman correlation above 0.6 before treating judge scores as reliable (Figure 4). If you’re below that threshold, your rubric or your prompt is too vague. Tighten it and repeat.
Once your judge is calibrated, it doesn’t stay calibrated. Your data distribution will shift. Your users will find new ways to phrase queries. Your product will change. Periodic spot-checks — re-labeling a sample every few months — are not overhead. They’re quality control.
What this means for how you build
LLM-as-a-Judge is not a replacement for human evaluation. It’s a tool for scaling human judgment to volumes where direct review isn’t feasible. The moment you forget that distinction, you’ve stopped evaluating your system and started letting the system evaluate itself.
The teams that use this well treat the judge as a measurement instrument that requires calibration, maintenance, and periodic auditing. They track not just the scores it produces, but how reliably those scores track what humans actually care about.
The teams that use it poorly treat it as a black box that produces a number. They’re usually the ones surprised when a model that looked great in eval performs poorly in production.
The question worth sitting with: in your current evaluation setup, if the judge is wrong, would you know?
Principal GenAI Architect at GFT Technologies, building production AI systems for the financial sector. If this was useful, the next piece covers how to structure a continuous evaluation pipeline with Vertex AI — from prompt to production signal.
When the Judge Is Compromised was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.