
I Built an AI Pilot That Plans Like a Robot and Dodges Like a Human
A hybrid A* + Deep Reinforcement Learning system in Unity, an SR-71, 5 million training steps, and the architectural insight that made it work.
When a fighter pilot flies a routine sortie, they don’t improvise — they follow the plan. When a missile lock alarm goes off, they don’t follow the plan — they improvise.
Classical AI is great at the first thing. Reinforcement learning is great at the second. So why does almost everyone try to use one of them for both?
That question started this project.
In 2020, DARPA’s AlphaDogfight trials concluded with a deep reinforcement learning agent decisively beating an experienced human F-16 pilot in simulated dogfights. The headline was that the future of air combat is AI. The footnote, which got less attention, was that the winning agent was not a pure end-to-end RL system. It was a hybrid — different controllers handing off to each other depending on the situation.
I wanted to understand that pattern, so I built a small version of it from scratch. An SR-71 agent in Unity. A maze of obstacles to navigate. A radar-guided missile launcher that wakes up the moment the agent enters its detection range. And two different brains: a classical path planner for the boring parts and a deep RL policy for the chaos.
This is what I built, how it works, and why I think the hybrid architecture is the most under-appreciated idea in applied AI right now.
Repo: github.com/Alpsource/Mastering-Fighter-Jet-Survival-Tactics

The Insight: Two Kinds of Problem, Two Kinds of Brain
Most aerial navigation problems are actually two problems wearing the same costume.
The first is route planning — getting from point A to point B around known obstacles. This is a deterministic, well-defined problem with a clean optimal answer. It has been solved beautifully since the 1960s. A*, RRT, Dijkstra. Classical search algorithms run in milliseconds, give you provably optimal paths, and are entirely predictable. They don’t surprise you. They don’t hallucinate. They don’t need training data.
The second is threat evasion — when something is actively trying to kill you, the world becomes non-stationary, the dynamics are partially observable, and there is no clean optimal answer to compute. This is exactly the kind of problem deep reinforcement learning was invented for. Train a policy on millions of randomized scenarios, let it discover evasion patterns no human would think to specify, and deploy.
If you build a system that uses RL for both problems, you waste enormous capacity training the agent to do something A* already does perfectly. If you build a system that uses A* for both, your jet flies straight into the missile.
The interesting move is to use both and switch.

The Setup
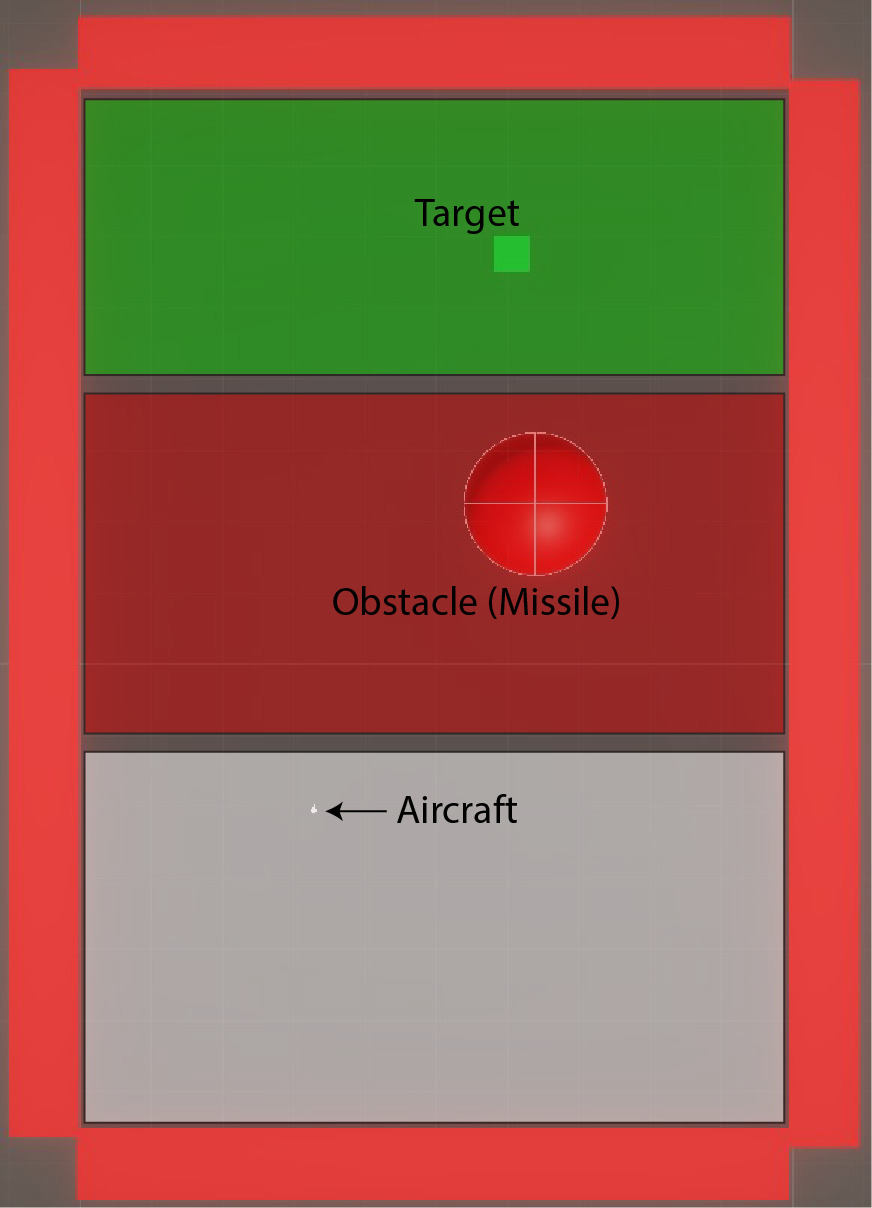
The environment is a top-down 3D scene in Unity 2022.3 with ML-Agents. Three zones:
- Bottom: the aircraft spawn region (randomized X position so the agent can’t memorize a single trajectory)
- Middle: a missile launcher with a configurable detection radius, visualized as a white wireframe sphere
- Top: the target zone — a green platform that gives the agent +100 reward on contact
Purple walls form a procedural maze that the aircraft must navigate. Wall collisions cost the agent a penalty proportional to how far away it still is from the target — so flying into a wall near the goal is less catastrophic than flying into one at the start.
The aircraft is a Lockheed SR-71 mesh, because if you’re building a fighter jet survival simulator, you might as well pick the most beautiful aircraft ever flown.
A* Plans the Path
A* is a 65-year-old algorithm and it still feels like magic.
I projected the 3D scene onto a 2D occupancy grid — each cell stores a 0 (free space) or a 1 (obstacle). The PathFinder runs A* on this grid using standard Euclidean distance as the heuristic and returns the next waypoint to head toward. The grid is rebuilt whenever obstacles move, so the path stays current even if the environment shifts.
The aircraft doesn’t teleport between waypoints — it flies to each one using physics forces, with a PID controller on the yaw axis correcting heading error every FixedUpdate. The PID is intentionally simple (Kp=0.05, Ki=0, Kd=0.002) and tuned manually, because once you have a stable inner loop, you can iterate on everything outside it.

This is the “boring” mode. The aircraft flies a clean path, hits its waypoints, and gets to the target — as long as nothing tries to kill it.
DQN Learns to Dodge
When the missile launcher’s sphere-cast detects the aircraft within its activation radius, a single line of C# fires:
SwitchBehavior(BehaviorType.DQN);
The ML-Agents BehaviorType flips to InferenceOnlyThe trained ONNX policy takes over, and A* shuts up.

The RL agent’s job is narrower than the A* planner’s: it doesn’t care about the global goal, just about not dying in the next few seconds. The observation space reflects this:
- The agent’s local position (3 dims)
- The agent’s rotation as Euler angles (3 dims)
- The target’s local position (3 dims) — so the agent still knows roughly where to go
- The missile’s local position (3 dims) — the thing trying to kill it
- Distance to target (1 dim)
- Distance to threat (1 dim)
14 dimensions total. Compact, hand-engineered, no images or LIDAR — just the geometric truth of the situation. The action space is two continuous values: a lateral movement delta and a forward movement delta, with the forward component clamped to be strictly positive so the agent can’t learn to fly backwards out of trouble.
The reward structure is intentionally minimal:
Event Reward Reaching target +100 Wall collision −1 − dist/10 Timeout (>200s) −1 − dist/100
No explicit reward for evading missiles. No shaped reward for distance to threat. The agent learns evasion as an emergent consequence of “don’t crash, don’t time out, reach the green platform” — because in the presence of an active missile launcher, all three of those goals require not getting hit.
This was a deliberate choice. The first version of this project had an explicit goal +r for staying far from the missile, and the agent learned to stand still at maximum distance and never reach the target. Reward shaping is a trap. Letting the agent discover the strategy is harder to train but produces better behavior.
Five Million Steps and 24 Brains in Parallel
Training RL agents one episode at a time is painful. RL needs samples — millions of them — and Unity is not a particularly fast simulator. The fix is parallelism.
I instantiated 24 independent copies of the entire environment inside a single Unity scene, each with its own agent, missile launcher, target, and walls. ML-Agents handles the bookkeeping: all 24 environments report observations and receive actions through the same trainer, but they run independently, so when one resets, the others keep going.
This is the picture that made me happy:

Training ran for 5 million steps using PPO via the ML-Agents trainer. The reward curves tell the whole story of what the agent learned:
- Cumulative reward climbs from around 20 to roughly 100 — meaning the agent reliably reaches the target.
- Episode length drops sharply after the first million steps and stabilizes around 20, meaning the agent stopped wandering and started executing efficient routes.
- Value loss drops dramatically from ~650 to ~75 — meaning the agent’s internal model of expected future reward became dramatically more accurate.
- Policy loss oscillates in a tight band — exactly what you want during PPO training, indicating the policy is being updated but never destabilizing.

What Surprised Me
A few things I didn’t expect.
The hybrid architecture is dramatically more sample-efficient than pure RL. I tried an end-to-end variant where DQN handles both navigation and evasion. After 5M steps, it was still occasionally flying into walls. The hybrid version reached competence in roughly 1.5M steps — because the A* component never has to be learned. It’s already correct, by construction. RL only has to learn the thing RL is uniquely good at.
The PID controller mattered more than the policy. Before I added the yaw-axis PID, the aircraft oscillated wildly around its target heading, the RL policy received noisy proprioceptive observations, and training never converged. Stabilizing the inner-loop dynamics with classical control turned a “doesn’t train” problem into a “trains in 5M steps” problem. This is another version of the same lesson — use classical methods where classical methods are sufficient.
The agent discovered swerving on its own. I never told them about pursuit curves, missile lead, or evasive maneuvers. With nothing but +100 for reaching the target and small penalties for crashing or timing out, it learned to break left or right at the last moment before the missile’s impact estimate caught up. The first time I watched a successful evasion in real time, I had to rewind the recording — it looked too deliberate to be unplanned.
Why This Pattern Generalizes
The big idea here is older than this project, but it’s worth restating: the future of applied AI is not end-to-end deep learning replacing everything. It’s hybrid systems where each component is the right tool for its layer of the problem.

Tesla’s FSD has a classical planner sitting on top of neural perception. Boston Dynamics’ robots use model-predictive control on top of learned terrain estimators. Waymo’s driving stack mixes optimization, search, and learned models throughout. None of these systems are “pure RL” or “pure deep learning.” They all look more like this fighter jet project than like the end-to-end demos that get the most attention online.
A* is older than the silicon I trained the DQN on. It’s still the right algorithm for routine path planning. RL is the right algorithm for situations for which no one can specify a closed-form policy. Putting both in the same agent — with a clean handoff mechanism between them — is not a hack. It’s the architecture.
If you’re building autonomous systems, the question is rarely “deep learning or classical?” It’s “which subproblems are routine enough for classical, and which ones are chaotic enough to need learning?” The hybrid answer is almost always better than the pure-learning one, and almost always cheaper to train.
What’s in the Repo
Everything you’d need to reproduce this:
- Full Unity 2022.3 project with the SR-71 mesh, the maze, the missile launcher, and the 24-environment training scene
- C# source for the agent (AircraftAgent.cs), the threat detection logic (RocketLauncherBehavior.cs), the PID controller, and the stats tracker
- The trained ONNX model — drop it in, hit play, watch the agent fly
- The ML-Agents YAML config for retraining from scratch
- A companion research paper with the full methodology and results breakdown
github.com/Alpsource/Mastering-Fighter-Jet-Survival-Tactics
If you want to extend it, the obvious next steps are multiple missile launchers, moving threats, partial observability (radar fog), and stacking a second RL agent on the missile side to make the whole thing adversarial. I have plans for at least the first three.
This is the kind of project I write about. Previous posts include implementing I-JEPA from scratch and a Masked Autoencoder build. More builds like this one are coming. If you’re working on autonomous systems, robotics, or the question of when to learn versus when to engineer, you might find them useful.
I Built an AI Pilot That Plans Like a Robot and Dodges Like a Human was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.