
Currently experimenting with exploration policies for deep RL on Super Mario Bros – Agent beats all levels I threw at it
 |
I’ve been playing with deep reinforcement learning for a while. I originally started with a simple DQN, added all improvements from the Rainbow paper, and finally changed C51 for a quantile regression (and plan to swap it for an Implicit Quantile Network). After implementing C51 (which was my first time with distributional RL) I started playing with policies that take advantage of the learned distributions : By independently taking Finding an optimal value for I later found out about DLTV which made the agent discover new behaviors, but performed worse than previous experiments overall. Inspired by it, I tried something I did not find in previous works and got the best results out of all my previous experiments : At each time step, compute an For anyone reading this, I have a few questions :
I actually track a moving average and standard deviation of the exploration score, which lets me shift/rescale its values to a target average and standard deviation, and divide N by the shifted/rescaled value. I initially started with a target average of 1 and standard deviation of 1 as well (which gave good results), then tried randomizing these parameters at the start of each episode as well. This led to a lot more diversity in the policies and even better results. Since this worked so well, I additionally randomized the noise strength in the NoisyNet layers. Overall, this made the agent a lot more robust to deviating from what it considers to be the optimal trajectory, and allowed it to learn complex behaviors previous iterations were never able to learn (e.g. taking a few steps back to gain momentum, waiting for good cycles, or dodging hammer bros) For anyone interested, I made a live stream of the training in progress with graphs and some more details on the experiments I’m running. The current training run was started 8 days ago, and the agent is able to finish all stages (it’s not finishing them all every try though) Edit : formatting submitted by /u/pcouy |
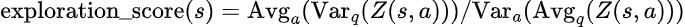{kind=link}