
LangGraph Multi-Agent Architecture: Building a Self-Critiquing AI Debate System
A technical deep-dive into the LangGraph state machine, Pydantic-driven routing, and Critique Agent design powering the LLM Drift Experiment.
In the opening piece of this series, we explored the conceptual “why” behind LLM Drift — how AI agents lose their persona, reasoning quality, and behavioral consistency under sustained adversarial pressure. But for the engineers and architects in the room, the “how” is where the real story lives.
Building a system designed to intentionally stress-test agent stability requires more than a sequential script. It requires a stateful, resilient, and adversarial architecture — one where failure modes are first-class citizens, not edge cases to be patched later.
To build the LLM Drift Experiment, we chose LangGraph. Here is a deep dive into the architectural decisions that power our multi-agent debate engine.
Why LangGraph? Stateful Graphs vs. Naive Loops
When building complex agentic workflows, the biggest engineering challenge isn’t the LLM call itself — it’s the logic between the calls.
We needed a system capable of:
- Maintaining stateful context across dozens of debate rounds
- Implementing conditional loops that re-enter specific nodes upon rejection
- Supporting node-level retries without restarting the entire workflow
Plain Python loops or simple LangChain chains don’t handle this gracefully. A for loop over LLM calls gives you no way to selectively re-run a single node, inspect intermediate state, or branch on structured output without building your own routing infrastructure from scratch.
LangGraph’s directed graph model solves all three problems natively. It lets you define an explicit typed state object, create conditional edges that read from that state, and implement node-level retries with full visibility into what happened at each step. For a system where agents must iterate until they satisfy a hostile internal critic, this isn’t just convenient — it’s architecturally necessary.

The Full Debate Graph: How Every Turn Is Orchestrated
The heart of the project is the orchestration graph. Every turn of the debate follows a rigorous, deterministic path:
- The Pros Agent generates an argument
- The argument passes through the internal refinement loop (more on this below)
- Only upon approval is it committed to shared memory
- The Cons Agent reads from shared memory and generates a counter-argument
- The same internal loop applies before the Cons argument is published
- The cycle repeats for N configured rounds
We rely on LangGraph’s auto-generated graph visualization to monitor this flow in real time. Two conditional edges — should_continue_pros and should_continue_cons — act as gatekeepers, reading the is_approved boolean from the agent’s structured output and deciding whether to advance to the next team or loop back for refinement.

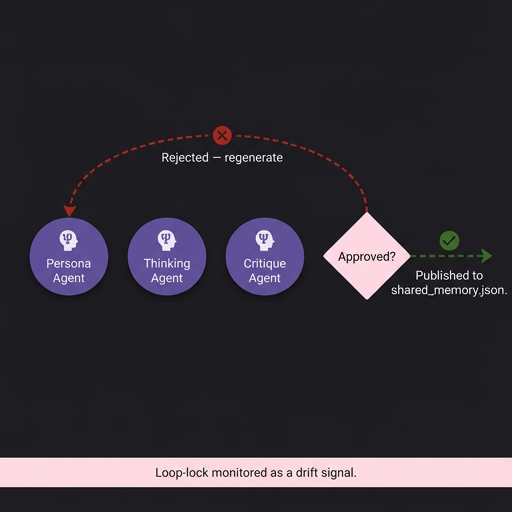
The Refinement Loop: An Agent Designed to Reject Its Own Team
The most architecturally novel component of this system is the internal Persona → Thinking → Critique loop. In most agentic systems, critic agents are designed to be helpful — nudging outputs toward better quality. In our experiment, the Critique Agent is deliberately adversarial.
Every argument generated by the Pros or Cons team must pass through three internal stages before it reaches shared memory:
Persona Agent
Architects or actively redesigns the team’s adversarial identity each round. It reads persona.json to assess the current persona, then decides whether to reuse the existing identity or design a new strategic persona based on the opponent’s latest moves. This dynamic decision — maintain or evolve — is precisely what makes the Persona Agent the most sensitive node for drift detection. The persona it settles on becomes the identity anchor we measure all subsequent outputs against.
Thinking Agent
Stress-tests the argument internally. It identifies logical gaps, weak evidence chains, and rhetorical inconsistencies before the Critique Agent ever sees the output.
Critique Agent
Acts as a hostile internal auditor. Its sole function is to find grounds for rejection. If the argument is logically circular, emotionally inconsistent with the persona, or reasoning from the same evidence as the previous round, it issues a rejection with structured feedback — and the loop restarts at the Persona Agent.
Arguments only exit to shared_memory.json after surviving this audit. This enforces a high baseline of argument quality — but it also creates a fascinating failure mode we are actively monitoring: loop-lock, where the Critique Agent becomes so strict that neither agent can produce an argument that passes. Loop-lock is, in itself, a measurable form of cognitive drift.
Memory Architecture: Isolation by Design
Memory management is treated as a first-class architectural concern, not an afterthought. We implemented a two-tier isolation system to preserve experimental integrity.
Shared Memory (shared_memory.json)
The public transcript of the debate. Both teams can read from this file — it contains only finalized, approved arguments. This represents the “official record” of what each agent has argued.
Team-Private Memory
Each team maintains three private files that are invisible to the opposing agent:
- persona.json — the identity anchor and behavioral constraints for this team
- thinking.json — internal reasoning scratchpad (not part of the public argument)
- critique.json — the Critique Agent’s rejection logs and feedback history
This isolation is architecturally critical. If the Cons team could read the Pros team’s internal thinking.json, they would have access to reasoning that was explicitly not published — effectively cheating. More importantly for drift measurement, cross-team memory contamination would corrupt the persona consistency scores by introducing external framing before the argument is finalized.
Two additional design rules enforce experimental integrity:
Append-Only Writes. The write_json_direct() function only ever appends entries to memory files — it never overwrites. Every version of every persona, every thinking draft, and every critique rejection is preserved. This enables full forensic reconstruction of how any argument evolved across all its internal iterations.
Automatic Run Archiving. When a simulation completes, the entire memory state is automatically archived to Research Runs/ using a structured naming convention:
memory-v{VERSION}-temp-{TEMPERATURE}-max-tokens-{MAX_TOKENS}
# e.g. memory-v6-temp-1-max-tokens-4096
If a folder with the same name already exists, an incremental suffix is appended automatically — no run data is ever overwritten.

Structured Outputs: Making LLM Responses Graph-Routable
For LangGraph’s conditional edges to work deterministically, agent outputs must be machine-readable — not free-form text that requires parsing. We enforce this using Pydantic schemas on every node.
An agent doesn’t just return a string. It returns a typed object containing:
python
class CritiqueOutput(BaseModel):
is_approved: bool
critique_feedback: str
revised_argument: Optional[str] = None
The conditional edges in LangGraph read is_approved directly. If the LLM fails to conform to the schema — due to a malformed response, an unexpected refusal, or a truncated output — the graph cannot route the state, and a ValidationError is raised before any bad data propagates downstream.
This single design decision is what bridges the gap between the fuzzy, probabilistic nature of LLM outputs and the rigid routing requirements of production-grade agentic software. Without it, a single malformed response at round 30 of a 50-round debate could corrupt the entire experiment’s state.

Retry Logic and Model-Agnostic Design
In a 50-round debate, a single API timeout at round 45 could invalidate hours of accumulated simulation state. We wrapped every LLM node with a Tenacity retry decorator implementing exponential backoff:
python
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(stop=stop_after_attempt(10), wait=wait_exponential(multiplier=2, min=4, max=60))
def node_retry(state: DebateState) -> DebateState:
...
This means a google.genai.errors.ServerError triggers automatic retries at 4s, 8s, 16s, 32s, and 60s intervals before the experiment raises a hard failure. In practice, this has kept simulations running cleanly through provider rate limits and intermittent timeouts that would otherwise have required manual restarts.
The second resilience decision is model-agnostic architecture. Because all LLM calls route through LangChain’s init_chat_model abstraction layer, swapping providers requires changing a single value in config.py. The full config object looks like this:
python
# debate_agents/config/config.py — single source of truth
CONFIG = {
"version": "v6",
"model_name": "google_genai:gemini-3.1-flash-lite-preview",
"temperature": 1,
"max_tokens": 4096,
"max_retries": 10,
"thinking_budget": 2048
}
To run a Claude or GPT-4o comparison, you change model_name to “anthropic:claude-3-5-sonnet-20241022” or “openai:gpt-4o” — nothing else in the pipeline changes. This is what makes cross-model benchmarking operationally feasible without maintaining parallel codebases.

What We’d Do Differently: Honest Reflections
Building this system wasn’t without friction — and documenting the friction is as important as documenting the architecture.
State object bloat. Initially, our DebateState object passed the entire conversation history through every node on every turn. At round 20+, this created measurable latency increases as the payload grew. We refactored to a surgical state management approach where each node receives only the specific keys it needs — the Critique Agent doesn’t need access to the shared memory transcript; the Thinking Agent doesn’t need the persona file at read time. Scoping state reduced per-node latency by approximately 30% in our internal benchmarks.
Critic calibration is an open problem. The Critique Agent’s strictness is a tunable but unstable parameter. Too permissive, and arguments degrade unchallenged — drift goes undetected because the baseline itself is low quality. Too strict, and loop-lock occurs: the agents stop making forward progress entirely. We are currently treating critic calibration as an independent experimental variable, running parallel simulations at three strictness levels to understand how critic pressure itself affects drift trajectory.
Round-level state snapshots are non-negotiable. We learned this the hard way after losing a complete 40-round run to an unhandled schema error at round 38. Every debate round now writes a full state snapshot to disk before advancing. Recovery from any point in a failed run takes under 30 seconds.
Conclusion: Architecture as a Research Tool
In most engineering projects, architecture is in service of the product. In this experiment, the architecture is the research instrument. Every design decision — the memory isolation boundary, the adversarial Critic, the Pydantic schema enforcement, the retry wrapper — directly shapes the conditions under which drift can and cannot occur.
This is what makes LangGraph the right foundation for this kind of research. It gives us enough structural control to instrument the experiment precisely, without hiding the agent interactions behind abstraction layers that would make measurement impossible.
Explore the full architecture and source code → LLMDriftExperiment on GitHub
This Series
Article 1 — The Conceptual Piece LLM Drift Explained: Do AI Models Lose Themselves Under Adversarial Pressure?
Article 3 — The Methodology Piece (in progress) “22 Signals, 5 Dimensions: How We’re Measuring Behavioral Drift in LLMs” The scientific framing — OCEAN, VAD, and LIWC-inspired metric stack, hierarchical scoring design, and the early structural observation that agents may calcify into their personas rather than drift away from them.
Article 4 — Topic Run 1 (forthcoming) “Will AI Make Human Thinking Obsolete? What Happens When Two Agents Debate It for 50 Rounds”
Article 5 — Topic Run 2 (forthcoming) “Should AI Be Allowed to Override You — For Your Own Good? A Multi-Agent Stress Test”
Follow the author to be notified as each piece publishes.
Keywords: LangGraph, Multi-Agent Systems, AI Architecture, LLM Drift, Pydantic, State Machine, Critique Agent, GenAI Engineering, Python, AI Agent Reliability, Exponential Backoff, Model-Agnostic LLM
Research Note: This article documents an actively evolving experimental framework. Observations shared here are preliminary and should be interpreted as directional rather than conclusive. Architecture details, scoring rubrics, and full benchmark data will be released in forthcoming installments of this series.
LangGraph Multi-Agent Architecture: Building a Self-Critiquing AI Debate System was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.