
I built a geopolitical news dashboard that runs entirely on my laptop using Qwen3.5:4b
Building a Geopolitical Intelligence Dashboard for £0/month Using Ollama /Qwen 3.5:4B
No cloud APIs, no subscriptions. Just Python, Dash, and a 4-billion-parameter model doing the analysis: “qwen3.5:4b”
I work in finance in London. Every morning I scan headlines trying to understand what’s happening with Iran and the US — oil prices, sanctions, military posture, the Strait of Hormuz. It’s noisy, slow, and spread across a dozen tabs.
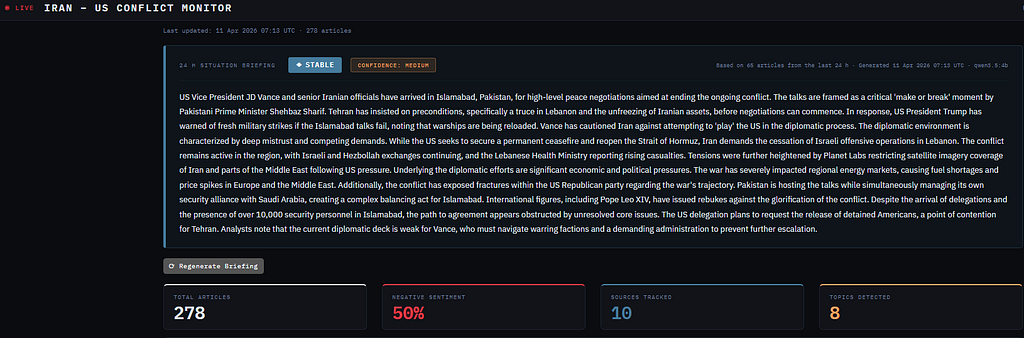
So I spent a weekend building a dashboard that does it for me. It pulls live news from 25 public RSS feeds, processes and classifies every article, and — here’s the part I’m most proud of — generates a 300-word factual briefing with an escalation verdict using a model running entirely on my own machine. No OpenAI. No Anthropic API. No data leaving my laptop.
The local LLM piece
The model doing the analysis is Qwen3.5:4b, a 4-billion-parameter model from Alibaba’s Qwen team, running locally via Ollama. I already had it set up for an email classifier project, so dropping it into this pipeline took about ten minutes.
Ollama exposes a local REST API at http://localhost:11434. You run ollama serve, pull a model, and then call it like any other HTTP endpoint — no accounts, no keys, no rate limits.
The briefing prompt feeds the last 24 hours of headlines and summaries into the model and asks for two things: a factual summary under 300 words, and a verdict — ESCALATING, DE-ESCALATING, or STABLE — with a confidence rating. The output comes back as JSON.
POST http://localhost:11434/api/chat { “model”: “qwen3.5:4b”, “stream”: false, “think”: false, “options”: { “temperature”: 0.1, “num_ctx”: 4096 }, “messages”: [ { “role”: “system”, “content”: “You are a neutral geopolitical analyst…” }, { “role”: “user”, “content”: “Here are today’s headlines. Summarise…” } ] }
The “think”: false flag is important. Qwen3.5 is a reasoning model — by default it emits a long internal monologue inside <think> tags before answering. That monologue can easily consume the entire token budget, leaving nothing for the actual response. Disabling it makes the model answer directly and cuts latency from ~40 seconds to ~11 seconds on my machine.
How the pipeline works

The topic classification and sentiment scoring are deliberately rule-based — simple keyword dictionaries. That keeps them fast, transparent, and predictable. I only reach for the LLM where it actually adds value: synthesising dozens of articles into a coherent narrative.
Why local matters here
This dashboard handles real-time geopolitical intelligence. Even if I trusted a cloud provider with that data, there’s a more practical reason to run locally: cost at scale. The briefing function calls the model once per refresh. If I were sending 40 articles to GPT-4o every 30 minutes, the bill would add up fast. With Ollama it’s free, forever, regardless of how often I run it.

There’s also a privacy angle. I’m analysing news, not personal data — so it’s less of a concern here. But the pattern is the same one I use for my email classifier, which does handle sensitive information. Keeping the model local means the data stays local.
The dashboard
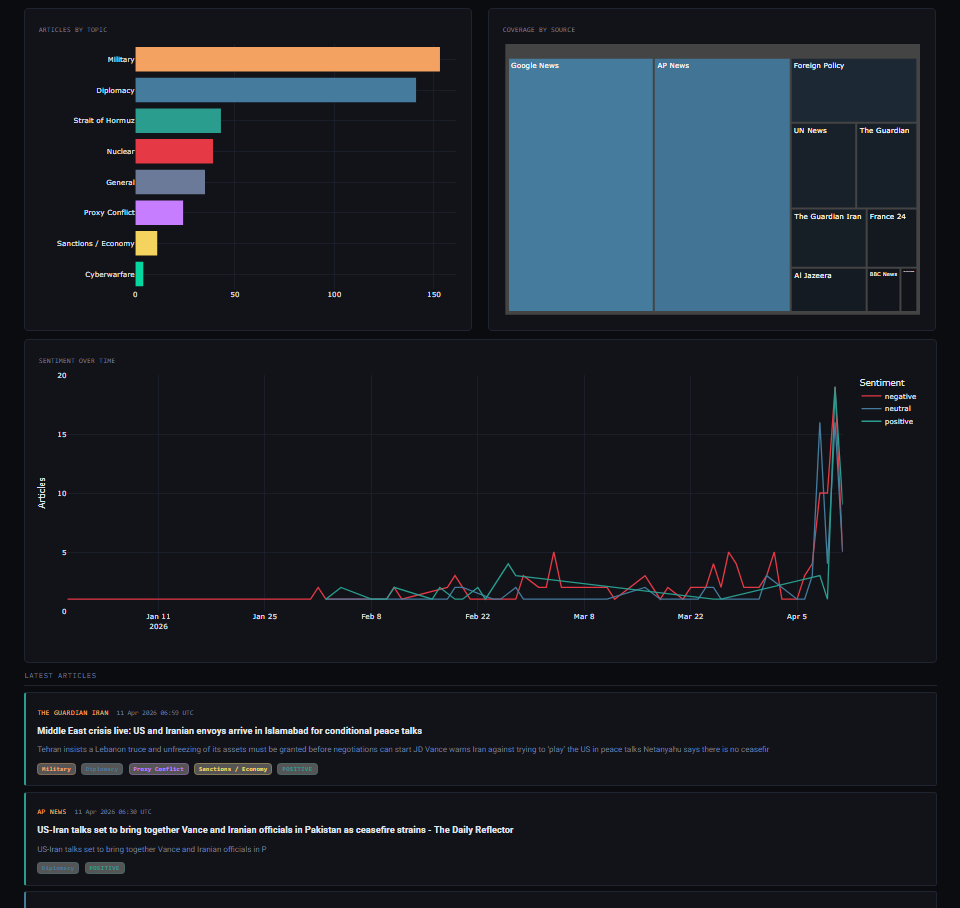
The front end is built with Dash and Plotly — a Python-native framework that lets you build interactive web apps without writing any JavaScript. The layout has a briefing panel at the top showing the verdict and summary, then stat cards, five charts (timeline, sentiment breakdown, topics, source treemap, sentiment over time), and a filterable article feed below.
It also sends a daily email digest — same briefing, same stats, same article table — via Gmail SMTP. No attachments, no chart images to render. Just clean HTML that looks good in any email client.
The tricky parts
Getting Qwen to return JSON reliably
Small models are bad at following strict output format instructions. Qwen3.5:4b sometimes wraps its JSON in markdown fences, sometimes adds a preamble, sometimes lets the reasoning trace eat the whole response. The fix: strip <think> blocks first, then use a regex to extract the first {…} block regardless of what surrounds it, then parse. If no JSON is found, surface the raw output so you can debug rather than getting a silent failure.
RSS feeds are inconsistent
Some feeds return full article text, some return only titles, some return malformed HTML in the summary field. The near-duplicate fingerprinting — sorting the words of each headline and hashing them — helps a lot when the same wire story gets picked up by six different feeds with slightly different wording.
Sentiment is approximate
The rule-based sentiment scoring is fast and explainable, but it’s crude. “Ceasefire talks collapse” scores as negative because “ceasefire” is a positive word and “collapse” a negative one — and the negative wins by one point. Good enough for a trend line. Not good enough to trust any individual label.
I built a geopolitical news dashboard that runs entirely on my laptop using Qwen3.5:4b was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.