
What is an AI Agent — and Why Should Data Engineers Care?
AI agents are the most talked-about technology in data engineering right now. Here is a plain-English breakdown of what they actually are, how the agentic loop works, and why this changes the data engineer’s job in ways that matter.
You cannot scroll through a data engineering newsletter, LinkedIn feed, or conference agenda right now without running into the phrase AI agent. It is everywhere. And like most things that are everywhere, it has also become hard to pin down — stretched across enough use cases that it has started to lose meaning.
So let’s slow down and actually define it. What is an AI agent? How is it different from a chatbot? And why should data engineers — people who build pipelines, manage warehouses, and wrangle SQL — care about any of this?
By the end of this article, you will have a clear mental model of how agents work, a concrete sense of where they are already showing up in data engineering workflows, and a simple code example that shows the agentic loop in action.
Start here — what an AI agent is not
The fastest way to understand AI agents is to contrast them with what most people have already used: a chatbot.
When you ask ChatGPT a question, it reads your message, generates a response, and stops. It does not go off and do things. It does not check a database, run a query, call an API, or take any action in the world. It just produces text. That is a language model doing what language models do — predicting the next token.
An AI agent is different. An agent uses a language model as its brain, but it also has tools it can call, a goal it is working toward, and a loop that keeps running until the goal is achieved. It does not just answer — it acts.
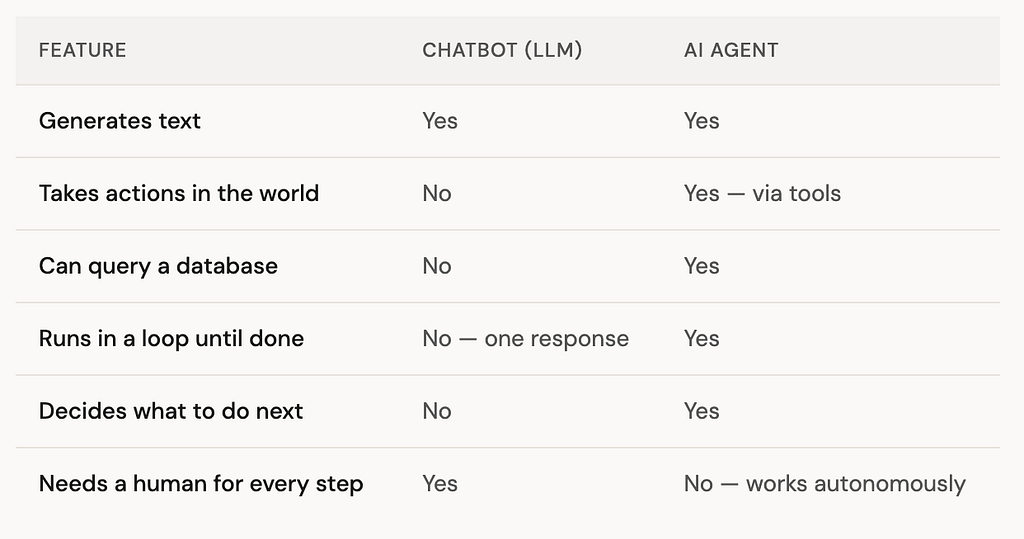
The key word in that table is autonomous. An agent receives a goal, figures out what steps to take, executes them using tools, observes the results, and decides what to do next — all without a human prompting each step. That is the fundamental shift.
The four parts of an AI agent
Every AI agent — regardless of how simple or complex it is — has the same four components:
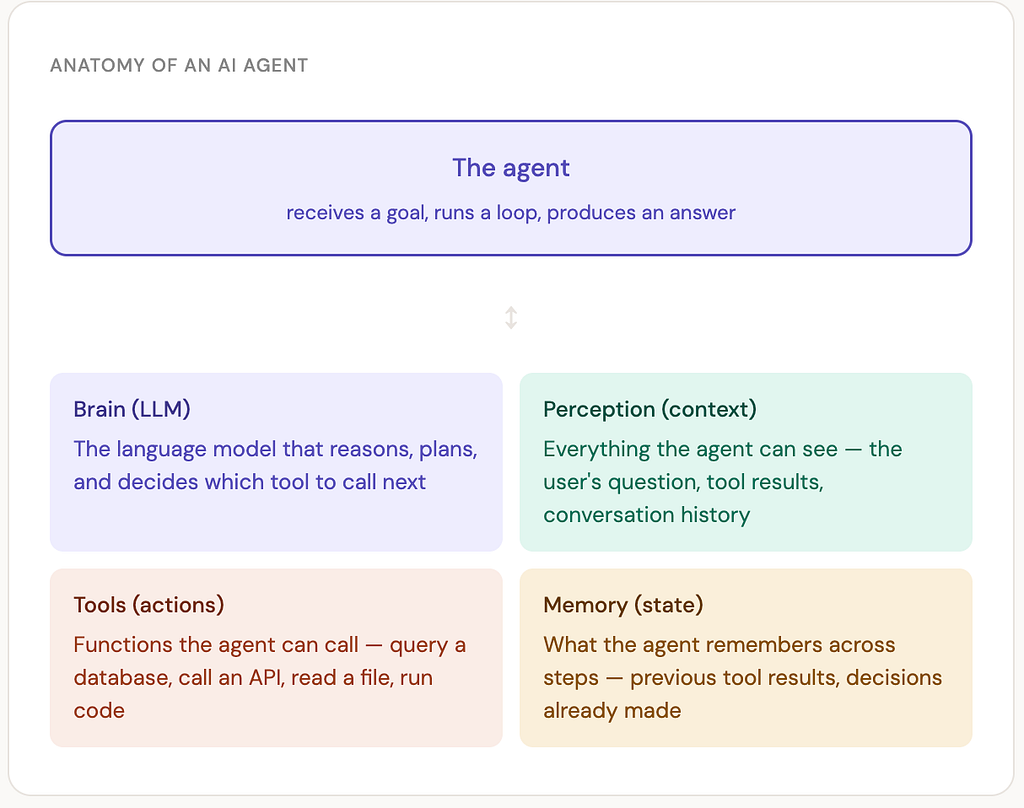
The brain without tools is just a chatbot. The tools without a brain are just functions. What makes an agent an agent is the combination: an LLM that can decide which tools to call and act on the results.
The agentic loop — how it actually works
Here is the core mechanism that makes agents different from anything that came before. It is called the agentic loop, and once you see it, you will recognise it everywhere.

This loop is the beating heart of every AI agent. A simple agent might run it twice. A complex one might loop twenty times, calling different tools at each step, building up context before finally producing an answer.
A concrete example — a data agent in 30 lines
Here is a stripped-down version of the agentic loop in Python. This is the core pattern behind every “talk to your data” agent — including ones I have built myself. The details of the LLM call will vary, but the shape is always the same:
import json
# The tools our agent can call
def list_tables():
return "tables: orders, customers, products"
def query_sql(sql: str):
# In reality this runs against a real database
return f"Results for: {sql}"
TOOLS = {"list_tables": list_tables, "query_sql": query_sql}
def run_agent(user_question: str):
messages = [{"role": "user", "content": user_question}]
# The agentic loop — keep going until the LLM says it's done
for _ in range(10): # max 10 iterations as a safety limit
response = call_llm(messages, tools=TOOLS)
# If the model wants to call a tool — do it
if response.finish_reason == "tool_calls":
for tool_call in response.tool_calls:
tool_fn = TOOLS[tool_call.name]
tool_args = json.loads(tool_call.arguments)
result = tool_fn(**tool_args)
# Add the result back to the conversation
messages.append({
"role": "tool",
"content": str(result)
})
# If the model is done — return the answer
elif response.finish_reason == "stop":
return response.content
return "Agent reached iteration limit."
What this loop does:
The agent keeps calling the LLM, executing whatever tools it asks for, and feeding the results back into the conversation — until the LLM decides it has enough information to answer. Most questions need 2–3 iterations. The LLM calls list_tables first to see the schema, then calls query_sql with the right SQL, then synthesises the result into a plain-English answer.
That is the same pattern behind every “chat with your database” product you have seen — and it is simpler than most people expect.
Why data engineers specifically need to understand this
So far this might sound like something for AI researchers or ML engineers. Here is why it is squarely a data engineering concern.
Your pipelines are becoming agent infrastructure
AI agents do not materialise data from thin air. They call tools. And those tools hit databases, query warehouses, and read from the pipelines that data engineers build and maintain. When an agent writes broken SQL because a column name changed, or returns wrong answers because a pipeline is stale, that is a data engineering problem.
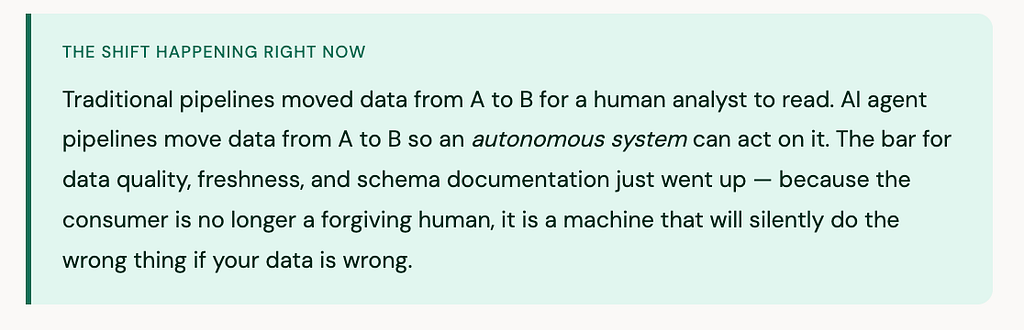
Agents need tools — and data engineers build those tools
Every agent needs to be connected to something useful. The most common data engineering tool in agent systems right now is exactly what it sounds like: a function that takes a SQL query and runs it against a database. Data engineers are naturally positioned to build, secure, and maintain these tool layers — wrapping database access, enforcing read-only constraints, handling pagination, and managing connection pooling.
Schema documentation is no longer optional
When a human analyst encounters an unfamiliar table, they ask a colleague. When an AI agent encounters one, it either hallucinates what the columns mean or fails. Good schema documentation — table descriptions, column definitions, relationships — is now directly load-bearing for how well your agents perform. The data teams that invested in dbt documentation are already ahead here.
The most interesting agent use cases are data use cases
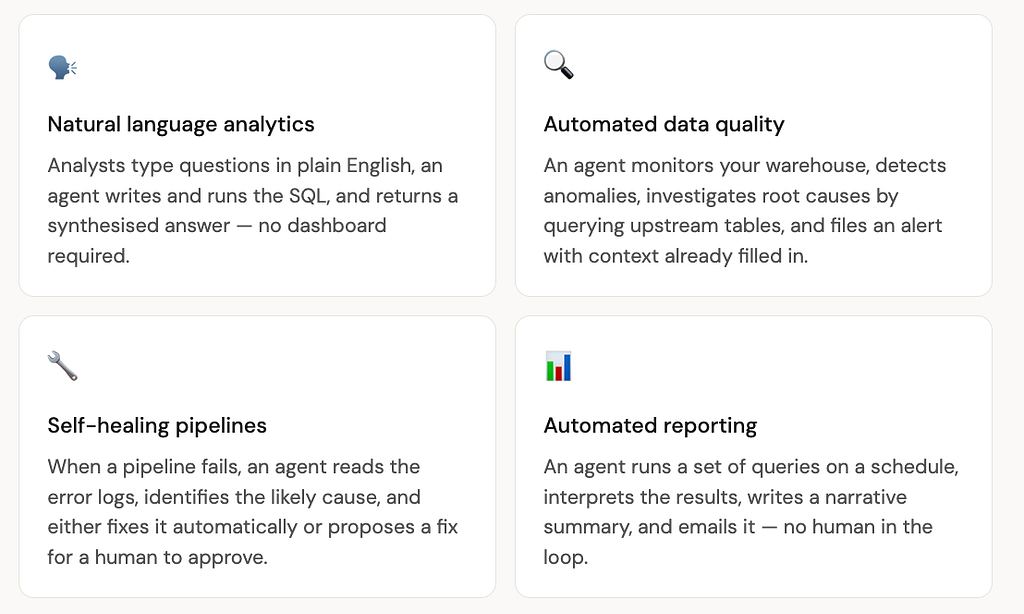
Every one of these use cases runs on top of data infrastructure that a data engineer built. The agent is the interface. The pipeline is the foundation.
“Data engineers are not being replaced by AI agents. They are becoming the people who make AI agents work — and that is a much more interesting job.”
What you should do with this right now
You do not need to become an AI researcher to benefit from understanding agents. Here are three practical things worth doing this month.
First, read up on how tool calling works in the LLM API you are most likely to use — OpenAI, Claude, or Gemini all support it. The pattern is the same across all of them, and understanding it at the API level demystifies most of what agent frameworks do under the hood.
Second, look at your existing dbt models and ask: if an AI agent tried to query this data, would it understand what the columns mean? If your documentation is thin, now is a good time to improve it — AI can help you write it, as we covered in the dbt article.
Third, consider building a small agent yourself. The agentic loop above is ~30 lines of Python. Connecting it to a real database with two tools — one that lists tables and one that runs SQL — is a weekend project. And doing it once teaches you more about agents than reading ten articles about them.
The honest picture — where agents are today
Agents are genuinely powerful, but it is worth being clear-eyed about where they are right now. They work well for well-scoped tasks with clear success criteria — answering a question about a database, running a defined workflow, generating a report. They are much less reliable for open-ended, high-stakes, or multi-step tasks where mistakes compound.
The hype cycle around agents in 2025 ran ahead of reality. Many production deployments were disappointing. But the underlying technology is maturing fast, and the pattern — an LLM with tools, running in a loop — is sound. The data engineering community is well positioned to build the reliable infrastructure layer that makes agents actually work in practice.
In the next article, I will go deeper into a real agent I built — a system that lets you ask natural language questions about Formula 1 racing history and get answers backed by a real PostgreSQL database with 75 years of race data. That project brought every concept in this article to life in a way that reading about it never quite does.
Key takeaways
- An AI agent is an LLM with tools, running in a loop — it does not just answer, it acts.
- The agentic loop is: receive goal → think → call a tool → observe the result → repeat until done.
- Data engineers are directly impacted because agents consume the pipelines, warehouses, and databases they build.
- Good schema documentation, data quality, and fresh pipelines are now directly load-bearing for how well AI agents perform.
- The most common data agent pattern — list tables, write SQL, run it, return an answer — is about 30 lines of Python at its core.
- Agents are promising but still maturing. Reliable data infrastructure is what makes them actually work.

What is an AI Agent — and Why Should Data Engineers Care? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.