
LLM Static Embeddings Explained: When Words Become Numbers and Meaning Still Survives!
How language becomes geometry — without losing meaning
In the last post, we built the first foundation:
Text → Tokens → Numbers → (lots of math) → Tokens → Text
We said:
- tokens are the pieces
- embeddings are the numbers
That is the right starting point. But if you sat with that idea for even a minute, a deeper question naturally appears:
Once words become numbers, why does meaning not disappear?
If the word cat becomes something like:
[0.21, -0.84, 0.67, …]
then how can those numbers still somehow preserve that:
- cat is closer to dog than to engine
- doctor belongs near hospital, patient, and medicine
- battery drain is more related to power issue than to birthday party
This is where embeddings become truly fascinating.
Because the challenge is not merely converting language into numbers. That part is easy. We could assign every word a unique, non-colliding ID and stop there.
- cat → 1842
- dog → 932
- engine → 77
But that would only preserve identity, not meaning.And that is the whole point. The hard part is not giving words numbers. The hard part is giving them numbers in a way that preserves relationship. That is the real story of embeddings.
Labels are easy. Representations are hard.
A label tells you which thing something is. A representation tells you what structure of that thing is preserved. That difference matters more than it first appears.
A passport number identifies a person. It does not represent their profession, personality, habits, or relationships. A seat number identifies a chair. It does not tell you whether it is near the aisle, closer to the stage, or more comfortable than another seat. In the same way, a token ID identifies a word, but it does not capture how that word relates to other words. That is why raw IDs are not enough for language.
Language is not just a pile of separate labels. It is a web of relationships. A word rarely means much in isolation. It lives in a neighborhood of association, contrast, co-occurrence, and role. That is the first important shift:
A useful language representation must preserve relationships, not merely names.
One-hot encoding gave identity, but not similarity
One early way to represent words was one-hot encoding.
Imagine a tiny vocabulary:
- cat
- dog
- car
- engine
- milk
Then each word gets a vector where one position is 1 and everything else is 0:
- cat → [1, 0, 0, 0, 0]
- dog → [0, 1, 0, 0, 0]
- car → [0, 0, 1, 0, 0]
- engine → [0, 0, 0, 1, 0]
- milk → [0, 0, 0, 0, 1]
This is better than a raw ID in one sense: it gives a structured input vector. But it still fails in a crucial way. To a one-hot representation:
- cat and dog are just as different as
- cat and engine
That is clearly wrong from a language point of view. Humans immediately feel that cat and dog share something. They are both animals, pets, familiar living things. But one-hot vectors cannot express that.
So one-hot encoding solves identity. It does not solve relatedness. And language lives in relatedness.
Why one number is not enough
At this point, someone might say:
“Fine. Instead of one-hot vectors, let us just assign each word one number.”
But one number is still too poor. Why? Because words do not vary along just one axis. Take the word apple. It can relate to:
- fruit
- food
- sweetness
- health
- orchard
- iPhone
- technology
- brand
That is not one dimension. That is many.
Take doctor:
- hospital
- patient
- diagnosis
- medicine
- clinic
- care
- profession
- authority
Again, many dimensions of relation. So if language is rich and multi-relational, the representation must also have room for many hidden properties at once. That is why embeddings are not one number.
They are lists of numbers.
A word becomes a point in a high-dimensional space. And once words become points, geometry enters the story. Now words can be:
- close
- far
- grouped
- aligned
- compared
That is the quiet brilliance of embeddings. They do not preserve meaning by storing dictionary definitions. They preserve meaning by preserving structure.
Meaning often lives in context
This is the central idea underneath embeddings:
Words that occur in similar contexts often carry similar meanings.
That intuition existed long before modern LLMs. It is often captured in the famous line:
“You shall know a word by the company it keeps.”
That sentence contains the seed of the whole embedding story. Think about these tiny sentences:
- The cat drinks milk
- The dog drinks water
- The cat chases the mouse
- The dog chases the ball
Now imagine a machine seeing these again and again. What does it notice?
It notices that cat and dog often appear in similar neighborhoods:
- after “the”
- near “drinks”
- near “chases”
They are not identical. But they play similar roles. That is the beginning of semantic structure. So when we ask:
“How do numbers keep meaning?”
the answer is not:
“Because numbers themselves are inherently meaningful.”
The answer is:
“Because the numbers are learned from patterns of context.”
That changes everything.
The real breakthrough: not arbitrary numbers, but relative positions
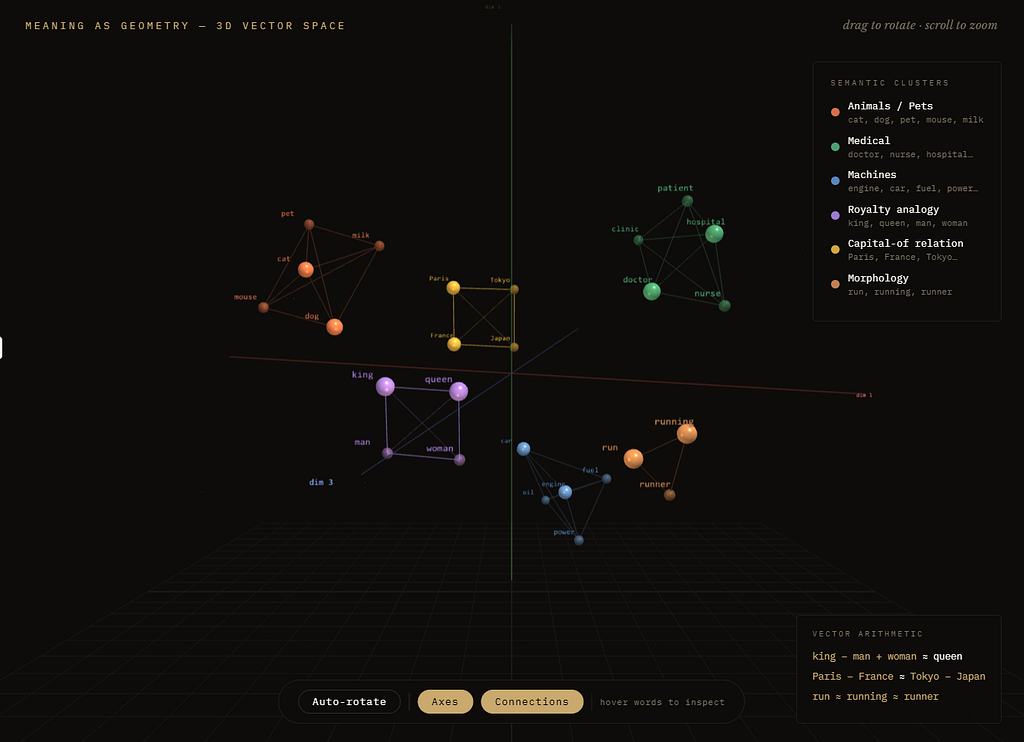
This is one of the most important points in the entire topic. The vector for cat does not mean much when looked at in isolation.
cat = [0.21, -0.84, 0.67, …]
A human cannot stare at that vector and say, “Ah yes, clearly this means furry domestic animal.” That is not how embeddings work. An embedding becomes meaningful mostly through its position relative to other embeddings. Its significance lies in questions like:
- Is cat near dog?
- Is doctor near hospital?
- Is engine far from milk?
- Does the relation between king and queen resemble the relation between man and woman?
So meaning is not sitting inside one vector like a tiny dictionary entry. It emerges from the geometry of the space. That is the real shift:
A random number can label a word.
An embedding can relate a word.
And language becomes useful to a model only when those relations are preserved.

A small philosophical pause
This is where the subject becomes quietly philosophical, but it stays grounded.
A map is not the city.
A musical score is not the performance.
A formula is not the physical world.
And an embedding is not the word itself. But a good representation preserves what matters for the task. A metro map is useful not because it perfectly preserves geographic shape, but because it preserves connectivity.
Similarly, an embedding is useful not because it is a literal definition, but because it preserves enough relational structure for computation to work. That is the deeper integrity of embeddings:
representation is not about copying the thing exactly;
it is about preserving the structure that matters.
Once you see that, embeddings stop looking like arbitrary numerical tricks.
They start looking like careful engineering of representational structure.
A short history: before embeddings became famous
The story did not begin with Word2Vec.
Long before modern deep learning, researchers were already trying to answer a hard question:
Can meaning be approximated from usage?
One early approach was to build count-based representations. For a word like cat, you might count how often it appeared near words like:
- milk
- pet
- animal
- fur
- mouse
And for engine, you might count how often it appeared near:
- car
- fuel
- machine
- power
- oil
If two words had similar context counts, they were treated as similar. This was an important step. It recognized that meaning can be approached statistically, through patterns of use.
Then came methods like Latent Semantic Analysis (LSA), which compressed large sparse count tables into smaller dense spaces. That was already a major conceptual move. Instead of keeping only raw counts, these methods tried to uncover deeper latent structure beneath the counts. In a way, this was already the embedding mindset beginning to form:
meaning may not live only in surface symbols;
it may live in a compressed latent structure.
These methods were useful. But the next step made the whole field feel much more alive.
Word2Vec: the moment embeddings became exciting
Word2Vec became famous because it gave a beautifully simple answer to the question:
Where do embedding numbers come from?
Its answer was:
Learn them through prediction.
More specifically:
Learn them by predicting nearby words.
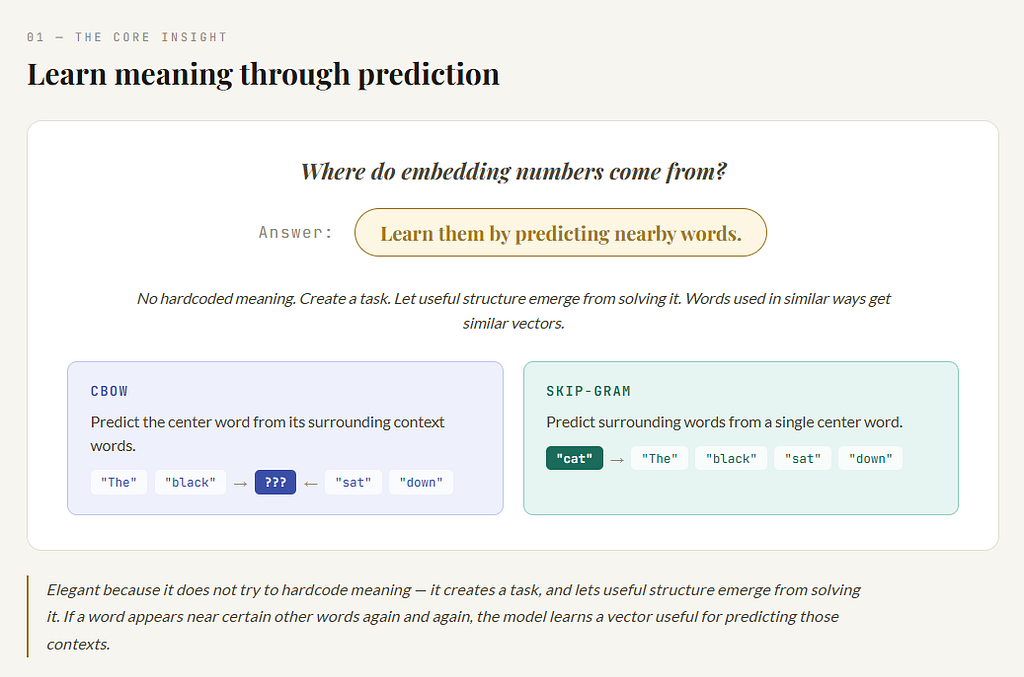
That is elegant because it does not try to hardcode meaning. It creates a task, and lets useful structure emerge from solving it. If a word appears near certain other words again and again, the model learns a vector that is useful for predicting those contexts. Over time, words used in similar ways get similar vectors. That is the heart of Word2Vec.
It came in two famous forms:
- CBOW: predict the center word from surrounding words
- Skip-gram: predict surrounding words from the center word
We will go into Word2Vec properly in the next post. For now, the key insight is enough:
A word’s embedding becomes whatever numeric profile helps the model handle the contexts that word belongs to.
That is why semantic structure begins to appear.
Why Word2Vec felt almost magical
When people first visualized trained word vectors, they saw something remarkable. Words were not scattered randomly. They formed neighborhoods.
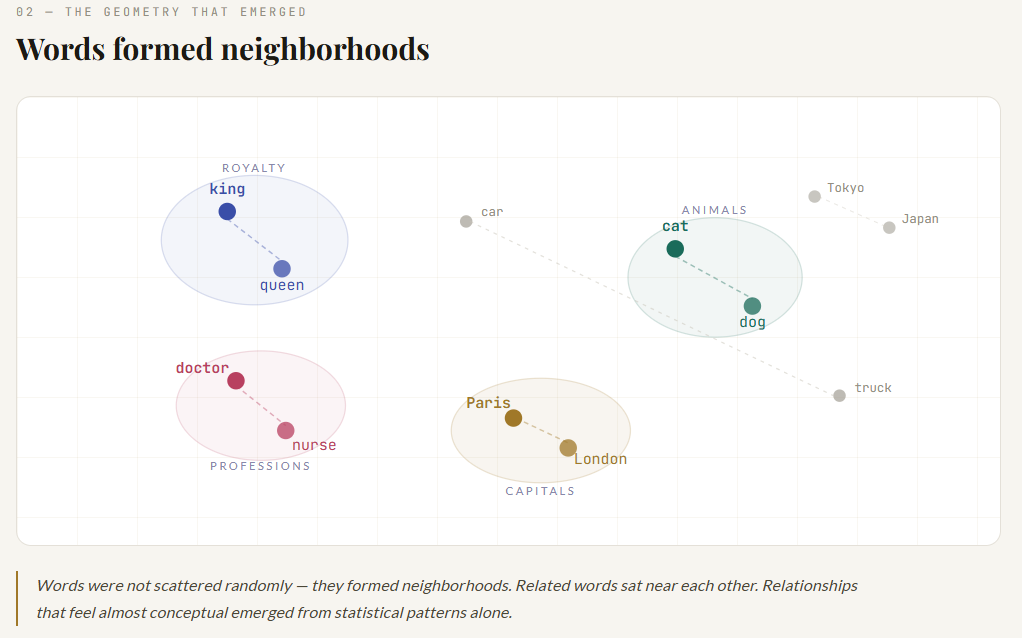
- cat near dog
- doctor near nurse
- car near truck
- Paris related to France in a way similar to how Tokyo related to Japan
And sometimes even vector arithmetic seemed to reveal structure:
king — man + woman ≈ queen
This was not magic in the mystical sense.
It was magic in the scientific sense:
a simple predictive objective had produced organized semantic geometry.

That was a major turning point in NLP. It showed that if you train a model to compress language into useful vectors, then relationships that feel almost conceptual can emerge from statistical patterns.
Not perfect understanding.
Not human meaning in full depth.
But real, useful structure.
And that was enough to change the field.
Other important embedding variants
Word2Vec was not the only chapter. It opened a family tree.
GloVe combined the embedding idea with broader co-occurrence statistics from the entire corpus.
A simple way to think of it is:
- Word2Vec learns a lot from local predictive neighborhoods
- GloVe also leverages global corpus-level relationships
Different route, similar aim: learn a dense space where words with meaningful relations sit near each other.
Then came FastText, which added another important insight:
words have internal parts
Instead of treating each word as one indivisible symbol, FastText also learned from subword pieces. That made it much better at handling:
- rare words
- misspellings
- morphology
- word families
So run, running, and runner could share useful structure.
This mattered because real language is messy. Vocabulary is never complete, and the internal shape of words often carries meaning. Word2Vec, GloVe, and FastText are often grouped as static embeddings.
Why static?
Because each word gets one main vector. So bank gets one representation, whether the sentence is:
- “I sat by the river bank”
- “I deposited money in the bank”
That is powerful, but limited. And that limitation led to the next revolution.

Then came contextual embeddings
This was the next big realization:
meaning is often not a property of the word alone, but of the word in context
Static embeddings gave one vector per word type. But human language is full of ambiguity.
- bank can be financial or geographical
- bat can be an animal or sports equipment
- light can mean illumination or low weight
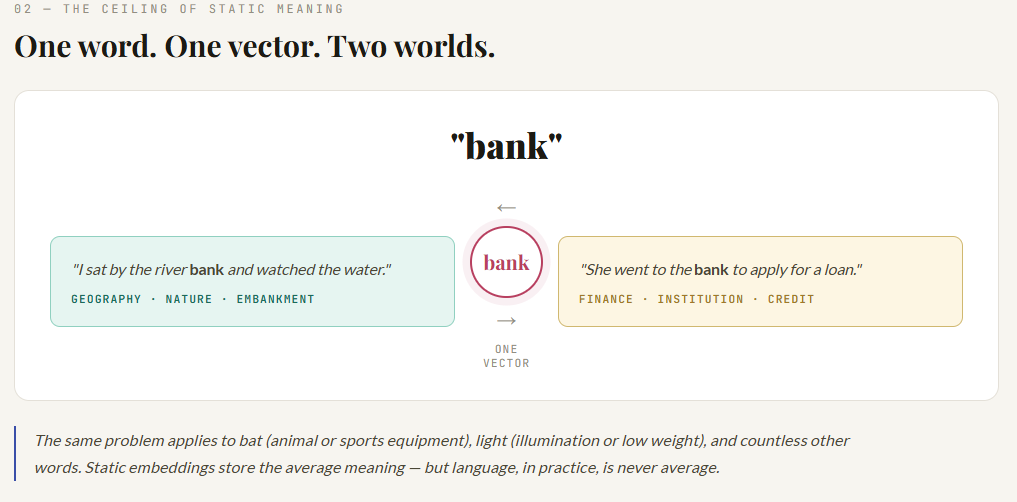
So later models moved toward contextual embeddings. Now the model could represent bank differently depending on the sentence. This is where systems like ELMo, BERT, and then Transformers changed the game.
The shift was profound:
do not just store a fixed vector for the word
compute a meaning for the word here, in this sentence, among these neighbors

That is why modern models feel far more flexible. They do not just map a word to a fixed point. They let context reshape representation dynamically.
A beautiful bridge: content-addressable memory
This idea deserves a light mention here because it helps explain why embeddings feel so powerful. Traditional computer memory is usually exact-address based:
- go to a location
- retrieve exactly what is stored there
But embeddings make a different style of access possible.

Once words, sentences, or documents live in a vector space, you can retrieve by similarity, not just by exact symbol.
A query about phone heating after update can find something about battery overheating after software patch even if the wording does not match exactly. In that limited but powerful sense, embeddings move computation a little closer to content-addressable memory or associative retrieval:
not “fetch item 1842”
but “find what is most like this”
That does not replace ordinary memory. But it is one reason embeddings are so foundational in modern AI. They make knowledge searchable by resemblance.
Embeddings did not stop at words
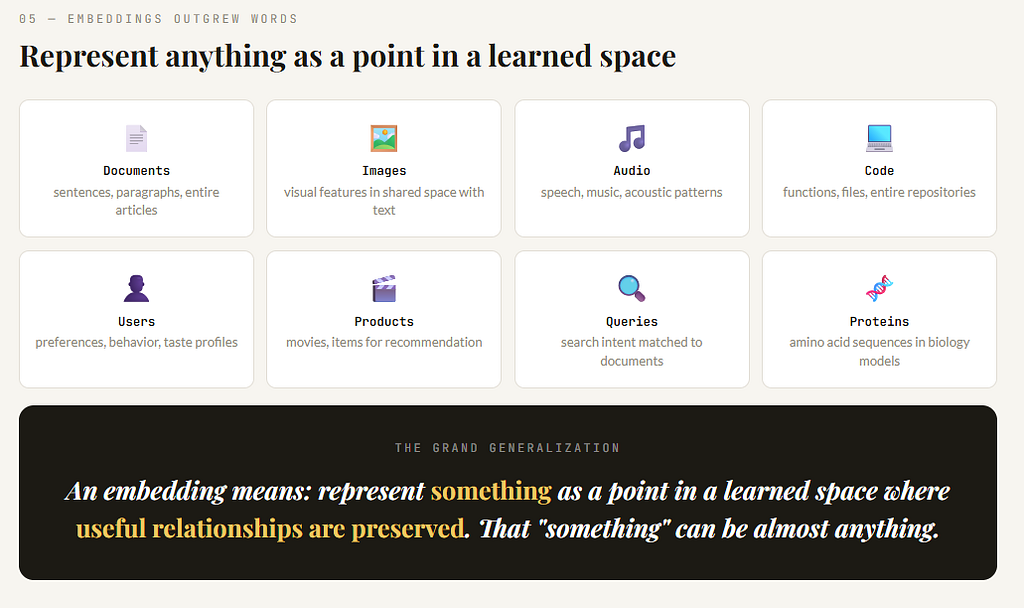
Once this representational idea proved powerful, it expanded far beyond words. Today we embed:
- sentences
- paragraphs
- documents
- images
- audio
- code
- users
- products
- proteins
This is worth pausing on.
An embedding is now a much broader idea than “word vector.”
It means:
represent something as a point in a learned space where useful relationships are preserved
That “something” can be almost anything.
A recommendation system can embed movies and users.
A search engine can embed documents and queries.
A code model can embed functions and files.
A biology model can embed protein sequences.
So embeddings became one of the great general ideas in machine learning.
Why embeddings matter so much today
If you are building modern AI systems, embeddings are not just historical background. They are active infrastructure. When you do semantic search or RAG, the core pattern is:
- embed your documents
- embed the query
- retrieve what is nearby in vector space
That works because closeness in the learned space often corresponds to closeness in meaning, relevance, or function. So when a system retrieves a chunk about payment failure after update for a question phrased as checkout broke after new release, it is using the same deep idea that powered early embeddings:
useful similarity can be computed geometrically
That is why embeddings remain central even in the age of giant LLMs.
So how does meaning survive?
Now we can answer the original question more honestly.
When words become numbers, how do meaning and relationships survive?
They survive because the numbers are not arbitrary. They are learned in a space shaped by context, co-occurrence, prediction, and relation.
Words that behave similarly get drawn into similar regions.
Words that differ strongly get pushed apart.
Relations can show up as patterns in direction, distance, and neighborhood.
So embeddings do not preserve meaning by hiding a tiny dictionary inside each vector. They preserve meaning by preserving relational structure. That is the core truth.
The vector for cat does not matter because [0.21, -0.84, 0.67, …] is inherently meaningful by itself. It matters because of where cat sits relative to dog, pet, mouse, milk, and everything else.
Meaning survives because structure survives.And once structure survives, computation can begin to act intelligently over language.
The calm takeaway
A raw token ID gives identity.
A one-hot vector gives structure, but no similarity.
Early statistical methods noticed that context reveals meaning.
LSA compressed that idea into latent spaces.
Word2Vec made embeddings exciting by learning them through prediction.
GloVe and FastText extended the idea.
Contextual models later made representation dynamic instead of fixed.
Across all these stages, one principle remained constant:
useful representations preserve useful relationships
That is the real integrity of embeddings. So the next time you hear that an AI model “turns words into vectors,” do not imagine something arbitrary or lifeless. Imagine this instead:
Language has been placed into a learned geometric space where relationships can survive computation.
That was one of the great turning points in modern AI. And in many ways, we are still living inside that idea.
But the story doesn’t end there. Then came the next breakthrough: meaning was no longer treated as fixed, because in contextual models a word’s representation changes with its surroundings, so “bank” in a river sentence and “bank” in a finance sentence become different embeddings.
We will learn about the need for dynamic/ context aware embeddings in the next post.
One-line memory hook
Words can become numbers without losing meaning when the numbers are learned in a space that preserves relationships.
LLM Static Embeddings Explained: When Words Become Numbers and Meaning Still Survives! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.