
On-Prem vs. Proxy Solutions for Secure LLM Usage: A Practical Guide for Enterprises
Understanding the two architectures shaping enterprise AI security, when to use each, and how a hybrid model balances compliance with capability.

Large language models have moved from experimental pilots to core business infrastructure faster than most organizations anticipated. With that shift has come a set of questions that were easy to defer during the pilot phase but are now unavoidable in production: Where is the model running? Who has access to the data going into it? How is that data governed?
These questions do not have a single universal answer. The right approach depends on the type of data an organization handles, the regulatory environment it operates in, and the resources it can commit to infrastructure. What has become clear, though, is that the deployment architecture — not the model itself — is increasingly the defining factor in whether an enterprise AI program is secure, compliant, and sustainable.
This article explains the two primary architectural approaches available to enterprises today: on-premise LLM deployment and proxy/gateway solutions. It covers what each one is, the trade-offs involved, and the conditions under which each approach makes sense. It also looks at the hybrid model that is emerging as the most practical path for organizations in regulated industries.
Why Deployment Architecture Has Become the Central AI Security Question
For much of 2023 and 2024, the enterprise AI conversation was focused almost entirely on model capability. Which model performed best on which benchmark. How large a context window was needed. Whether fine-tuning was worth the investment. These were reasonable priorities at a time when the technology itself was the main uncertainty.
By 2026, that calculus has shifted. Open-source models — Llama-4, Mistral Small 3.1, Qwen-2.5, and others — have matured to the point where they are viable for the majority of business use cases. Capability, for most applications, is no longer the primary constraint.
What has become the constraint is governance: the ability to demonstrate that sensitive data is handled appropriately, that access is controlled, and that the organization can account for what its AI systems have processed. This is not a theoretical concern. It is a concrete regulatory requirement in most major jurisdictions.
The EU AI Act introduced risk-based obligations for AI systems deployed in Europe. The Digital Operational Resilience Act (DORA) requires financial institutions to document and manage their AI-related operational dependencies. India’s Digital Personal Data Protection Act (DPDP) has codified data localization requirements that affect where processing can legally occur. In this environment, the question of where an LLM runs is inseparable from the question of whether an organization is compliant.
A detailed look at how these requirements are playing out across data-intensive industries is available in this analysis of cloud vs. on-premise AI compliance published by Questa AI. While framed around the BPO sector, the compliance dynamics it describes are broadly applicable to any organization processing sensitive third-party data at scale.
Option 1: On-Premise LLM Deployment
What it is
On-premise deployment means running the language model entirely within infrastructure the organization owns or directly controls. The model weights are stored on internal hardware, the inference engine runs on internal compute, and requests never leave the organization’s network perimeter.
How it works technically
A typical on-premise LLM stack consists of several components:
Hardware layer — GPU servers capable of running large models in a reasonable inference window. For most enterprise-grade open-source models (30B–70B parameters), NVIDIA A100 GPUs with 80GB VRAM are the practical minimum. Models above 70B parameters generally require H100 or H200 hardware.
Inference engine — Software that serves the model and handles incoming requests. Common choices include vLLM (optimized for throughput at scale), Ollama (developer-friendly, easier setup), and llama.cpp (CPU-capable, lower hardware ceiling).
Model selection — For on-premise deployments, the most widely deployed models are Llama-4 Scout and Maverick, Mistral Small 3.1, and Qwen-2.5–72B. Each covers most standard enterprise text tasks without requiring frontier-model infrastructure.
Access and security layer — Role-based access controls, network segmentation, encryption at rest and in transit, and audit logging.
When on-premise is the appropriate choice
Defense and intelligence contractors operating under air-gap requirements where network connectivity to external APIs is prohibited by contract or law
Organizations processing data governed by strict localization requirements where regulation specifies hardware within a defined physical or jurisdictional boundary
Government agencies where sovereign data classification rules apply
Organizations with very high LLM query volumes (2M+ tokens/day) where infrastructure costs become economically competitive with API costs over 12–18 months
Trade-offs to understand
On-premise deployment offers the strongest data control guarantee available: data that never leaves your network cannot be exposed through an external API breach. A production-ready deployment typically requires 3–6 months from decision to live environment, with upfront infrastructure investment generally ranging from $80,000 to $250,000+ depending on scale. Ongoing maintenance — model updates, security patching, capacity management — falls entirely on internal teams.
Option 2: LLM Proxy and Gateway Solutions
What it is
An LLM proxy (also called an LLM gateway) does not change where the model runs. Instead, it controls what reaches the model. The gateway sits between all users and applications on one side and the external LLM API on the other. Every request passes through this layer, where security and compliance policies are applied automatically before the request is forwarded to the model.
Core concept: Instead of securing the model itself, you secure the channel into it.
What a production-grade gateway handles
PII detection and redaction — Before a request reaches the external model, the gateway scans it for personally identifiable information — names, account numbers, addresses, health identifiers — and replaces them with anonymized tokens. The model processes clean data; the original values remain within the organization’s perimeter.
Access control and authentication — Enables organizations to define who is permitted to use which models, for which applications, with what constraints. Enforced centrally rather than in every application separately.
Prompt injection defense — Detects and blocks malicious inputs that attempt to override model instructions or extract system prompts before they reach the model.
Audit logging — Creates a complete, queryable record of every request and response — timestamped, attributed to a user or application, and stored for compliance review.
Rate limiting and cost controls — Per-team, per-application, or per-user token budgets prevent runaway costs and limit the potential impact of compromised credentials.
Model-agnostic routing — Switching models or providers becomes a configuration change rather than a re-engineering project.
When a gateway/proxy is the appropriate choice
For organizations that do not have an air-gap requirement but do have a data governance problem, a well-configured LLM gateway addresses the most common risk category in enterprise AI: uncontrolled data ingestion through employee usage. Deployment timelines are measured in weeks rather than months. The infrastructure investment is primarily software setup and configuration. The organization retains access to frontier model capabilities that self-hosted models cannot yet consistently match for complex tasks.
Limitations to be aware of
A proxy/gateway solution does not satisfy requirements that mandate data never leave the organization’s perimeter. If the regulatory requirement is about where processing physically occurs — not just whether it is governed — then a gateway alone is not sufficient.
The Hybrid Model: Local Redaction Combined With Cloud Inference
The architecture that has emerged as the practical standard for regulated industries is neither purely on-premise nor purely cloud. It combines a local data processing component with cloud model inference in a way that satisfies data residency obligations without sacrificing model capability.
How the architecture works
Stage 1 — Local redaction. An agent running on internal infrastructure scans incoming data and anonymizes it before it leaves the organization’s perimeter. Identifiers are replaced with tokens. The original values remain on internal systems.
Stage 2 — Secure gateway routing. The anonymized request is routed through a centralized LLM gateway with access controls, logging, and policy enforcement in place. No application reaches the model directly.
Stage 3 — Cloud model inference. The sanitized request reaches the cloud LLM. The model processes clean, anonymized data and returns a high-quality response. It does not see the original sensitive values.
Stage 4 — Response logging. The response is filtered, logged, and delivered. The complete request-response pair is stored for compliance purposes.
Why this architecture is gaining adoption
This pattern resolves the core tension in enterprise AI governance: organizations want access to frontier model capabilities, but their regulatory obligations require that certain data never be transmitted outside their control. By separating the identification of sensitive data (done locally) from the processing of anonymized data (done in the cloud), the hybrid model satisfies both requirements simultaneously.
A detailed walkthrough of this architecture and the full deployment decision framework is covered in this:- On-Prem or Proxy Solutions for Secure LLM Usage: What Enterprises Need to Know in 2026
Choosing Between the Three Approaches
The following framework is intended as a starting point for evaluation, not a definitive prescription. Every organization’s regulatory environment and infrastructure constraints are different.
Architecture Comparison
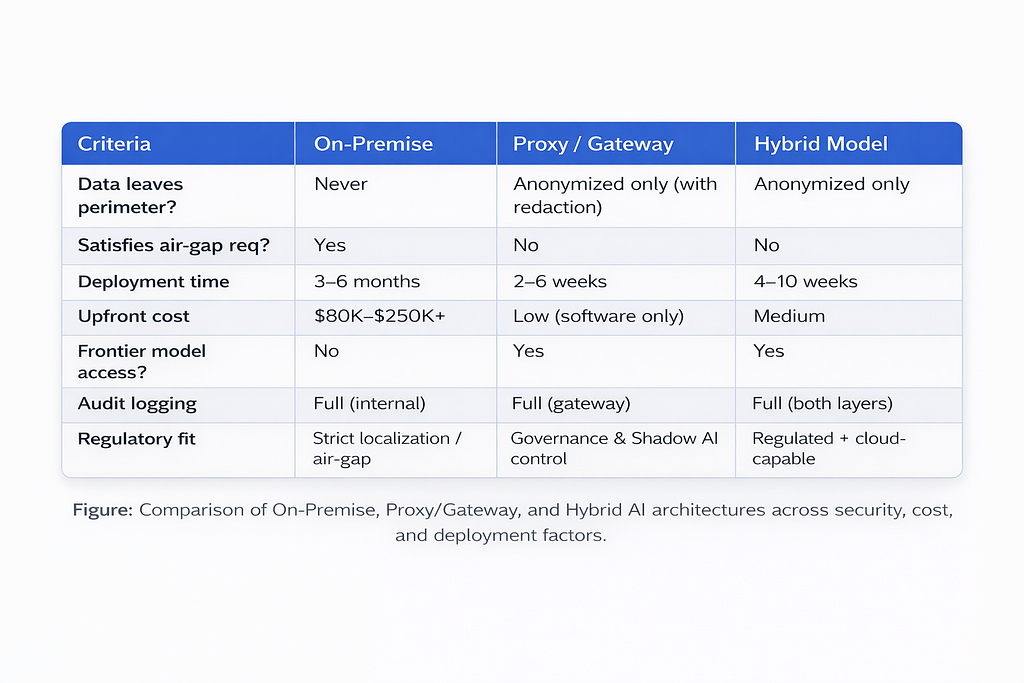
Decision Guide
Choose on-premise deployment when data cannot leave a defined physical or network perimeter under any regulatory or contractual condition; when air-gap requirements apply; or when LLM query volume is high enough that infrastructure costs become economically competitive with ongoing API costs.
Choose a gateway/proxy solution when the primary risk is uncontrolled employee usage and the absence of audit trails; when deployment speed is a constraint; when budget favors operational over capital expenditure; or when frontier model quality is required and self-hosted models are not yet sufficient.
Choose the hybrid architecture when the organization processes regulated data but operates under frameworks that permit cloud processing of anonymized inputs; when data residency laws require local processing of identifiable information before any external transfer; or when long-term architectural flexibility is a priority.
Key Considerations Before Making a Decision
Regulatory scope first. Before evaluating any technical options, map the specific regulatory frameworks that apply to your data types and jurisdictions. The right architecture follows from that map, not from vendor capabilities or cost comparisons.
Audit trail as a baseline requirement. Regardless of which architecture is chosen, the ability to produce a complete record of what data your AI systems processed, when, and by whom is a baseline expectation under most current compliance frameworks.
Model quality trade-offs are real but narrowing. Self-hosted open-source models have improved significantly, but for complex reasoning tasks, document analysis requiring large context windows, and multimodal applications, frontier cloud models still have a material quality advantage. This gap is narrowing.
Total cost of ownership includes maintenance. On-premise deployments carry ongoing costs that are easy to underestimate: hardware refresh cycles, model update pipelines, security patching, DevOps capacity. These should be factored into any cost comparison with cloud alternatives.
Summary
The deployment architecture decision for enterprise LLMs has moved from a secondary technical consideration to a primary compliance question. Organizations operating in regulated industries — financial services, healthcare, government contracting, legal, and others handling sensitive personal data — need a deliberate architecture decision, supported by mapped regulatory requirements and technical controls, not a default inherited from the AI vendor onboarding process.
The three options available — on-premise, gateway/proxy, and hybrid — are all viable for the right use cases. The key is matching the architecture to the actual regulatory and operational requirements, rather than to convenience or initial cost alone.
Further Reading
Cloud vs. On-Premise AI Compliance in BPOs Industry — Questa AI — A detailed breakdown of how cloud and on-premise architectures perform against current compliance frameworks in data-intensive industries.
On-Prem or Proxy Solutions for Secure LLM Usage — A practitioner-focused decision framework covering infrastructure specifics and the full evaluation criteria for each deployment model.
These questions do not have a single universal answer. The right approach depends on the type of data an organization handles, the regulatory environment it operates in, and the resources it can commit to infrastructure. What has become clear, though, is that the deployment architecture — not the model itself — is increasingly the defining factor in whether an enterprise AI program is secure, compliant, and sustainable.
This article explains the two primary architectural approaches available to enterprises today: on-premise LLM deployment and proxy/gateway solutions. It covers what each one is, the trade-offs involved, and the conditions under which each approach makes sense. It also looks at the hybrid model that is emerging as the most practical path for organizations in regulated industries.
On-Prem vs. Proxy Solutions for Secure LLM Usage: A Practical Guide for Enterprises was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.