
How I Built a Production AI Query Engine on 28 Tables — And Why I Used Both Text-to-SQL and…
How I Built a Production AI Query Engine on 28 Tables — And Why I Used Both Text-to-SQL and Function Calling
A real architecture from an affiliate marketing ERP — with a 3-layer AST security validator, MCP agent actions, and 18 automation workflows running in prod.
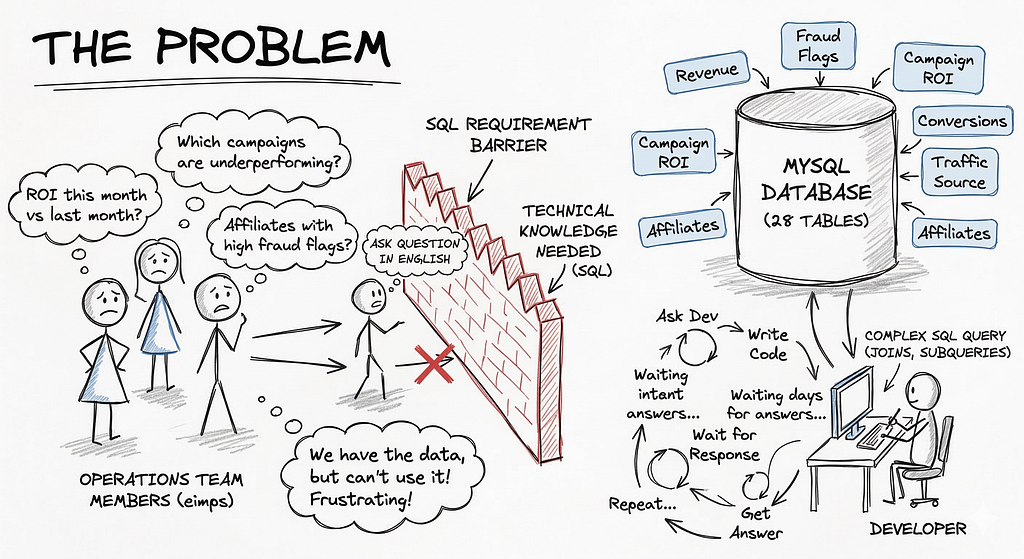
The Problem
The operations team at an affiliate marketing company I worked with had a problem every data-driven business eventually hits.
They had all the data. Revenue by affiliate, fraud flags, campaign ROI, conversion rates by traffic source. All of it, live, in a 28-table MySQL database.
But to answer any non-trivial question, someone had to write SQL. And the people who needed the answers weren’t the people who could write SQL.
The ask was simple: let a non-technical operator type a question in plain English and get a live answer from the database. No dashboard config. No SQL knowledge. No waiting for a dev.
This is the story of how I built that — and the two architectural mistakes I almost shipped.
Mistake #1 — I started with Function Calling
Every paper recommends it. Clean JSON schema, predefined structure, the LLM fills out a form instead of writing free SQL. Safe. Controlled. Auditable.
So I tried it on a real query from the team:
“Compare campaign ROI this month vs last month, by traffic source, excluding fraud flags, grouped by affiliate tier”
Here’s what the JSON schema needed to express that:

15 nested parameters. The LLM hallucinated 3 of them. The query returned garbage.
SQL was literally invented for this. One JOIN handles what your schema can’t:
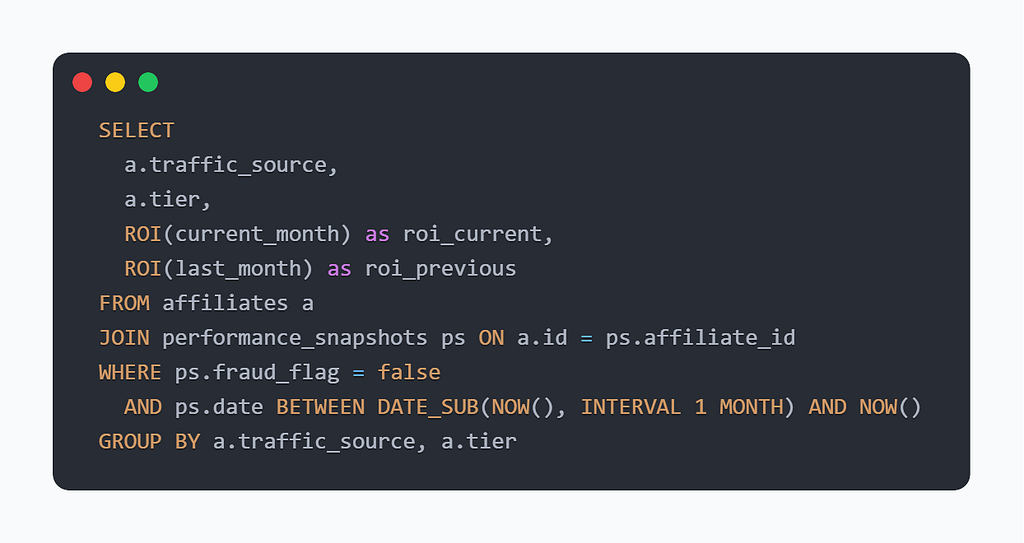
Function Calling is excellent for simple, single-table retrievals. For cross-table analytics with temporal logic, it breaks fast.
Mistake #2 — Text-to-SQL alone terrified me
The obvious fix was to let the LLM write SQL directly. And it worked — the queries were accurate, flexible, and handled complexity naturally.
But I was running this on a production database. Real financial data. Real affiliate records.
The standard advice is to put “only write SELECT statements” in the system prompt. I didn’t trust that. A sufficiently creative prompt injection, a jailbreak, a model regression — and suddenly you have an LLM with DELETE access to your production DB.
I needed a guarantee. Not a guideline. A mathematical guarantee.
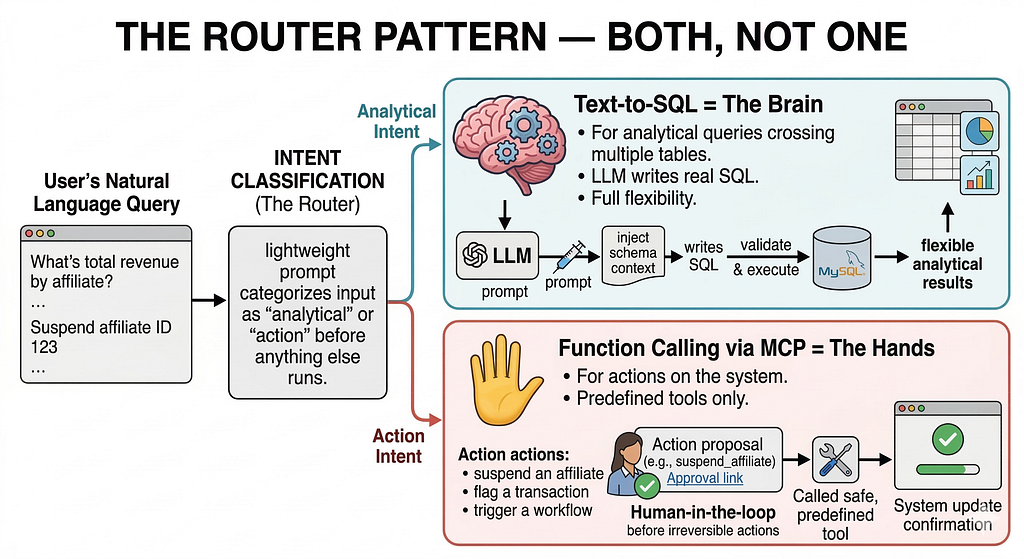
The Router Pattern — Both, Not One
So I stopped choosing and built a routing layer instead.
The architecture has two modes:
🧠 Text-to-SQL = The Brain For analytical queries crossing multiple tables. The LLM writes real SQL. Full flexibility.
✋ Function Calling via MCP = The Hands For actions on the system — suspend an affiliate, flag a transaction, trigger a workflow. Predefined tools only. Human-in-the-loop before anything irreversible runs.
The router decides which path based on intent classification — a lightweight prompt that categorizes the input as “analytical” or “action” before anything else runs.
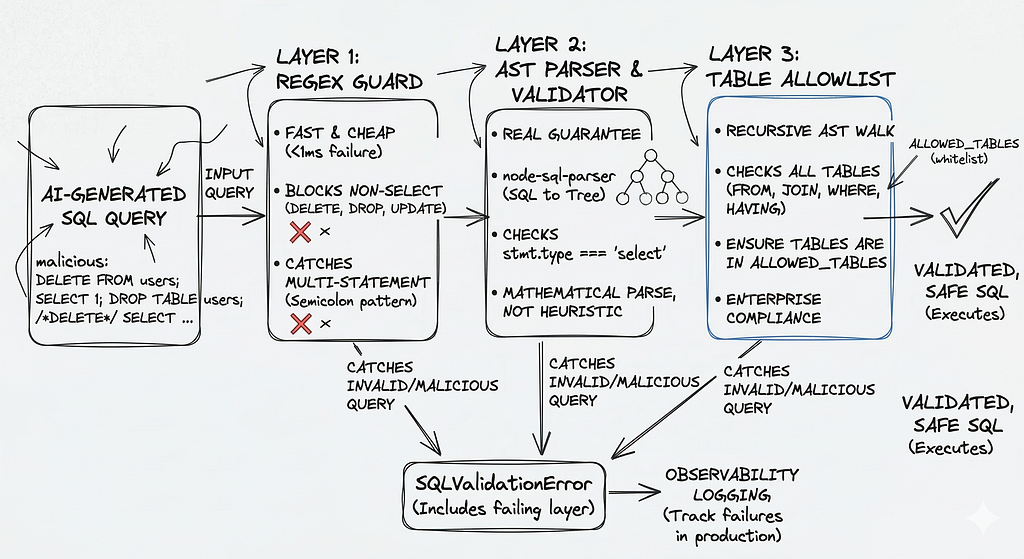
The AST Validator — The Part Nobody Talks About
This is the piece that made Text-to-SQL safe enough to ship to real users.
The idea: instead of trusting the LLM to follow instructions, intercept the generated SQL and validate it mathematically before execution — using an Abstract Syntax Tree parser.
Here’s the full implementation (SQLValidator.js):

Why 3 layers instead of 1?
Each layer catches what the previous one misses:
Layer 1 — Regex is fast and cheap. It blocks DELETE, DROP, UPDATE before any parsing happens. It also catches multi-statement injection (SELECT 1; DROP TABLE users) via the semicolon pattern. This layer fails in under 1ms.
Layer 2 — AST is where the real guarantee lives. node-sql-parser converts the SQL string into a typed Abstract Syntax Tree. The validator then checks stmt.type === ‘select’ — not as a string comparison on the raw SQL, but on the parsed semantic structure. A query like /*DELETE*/ SELECT … passes the regex but the AST still returns type: select. The parse is mathematical, not heuristic.
Layer 3 — Allowlist recursively walks the AST — FROM clauses, JOINs, subqueries in WHERE, subqueries in HAVING — and checks every table name against a whitelist. The LLM cannot access a table that isn’t in ALLOWED_TABLES, even if it generates valid SQL. This is the enterprise-grade layer that makes compliance teams comfortable.
The SQLValidationError includes the failing layer (regex, ast, allowlist) — which feeds directly into your observability logging and lets you track which layer is catching what in production.
The MCP Layer — Giving the AI Hands
Once the analytical layer was secure, I built the action layer using MCP (Model Context Protocol).
The idea is simple: instead of the LLM generating SQL for actions, it calls pre-defined tools with explicit parameters. The tools are hand-crafted Node.js functions that assemble safe queries internally.

For anything irreversible — suspension, financial flags, status changes — the system inserts a human approval step before execution. The LLM proposes the action, a manager confirms it in Slack, then the tool runs.
This is the “Hands” half of the architecture. Text-to-SQL reads. MCP acts.
What This Looks Like in Production
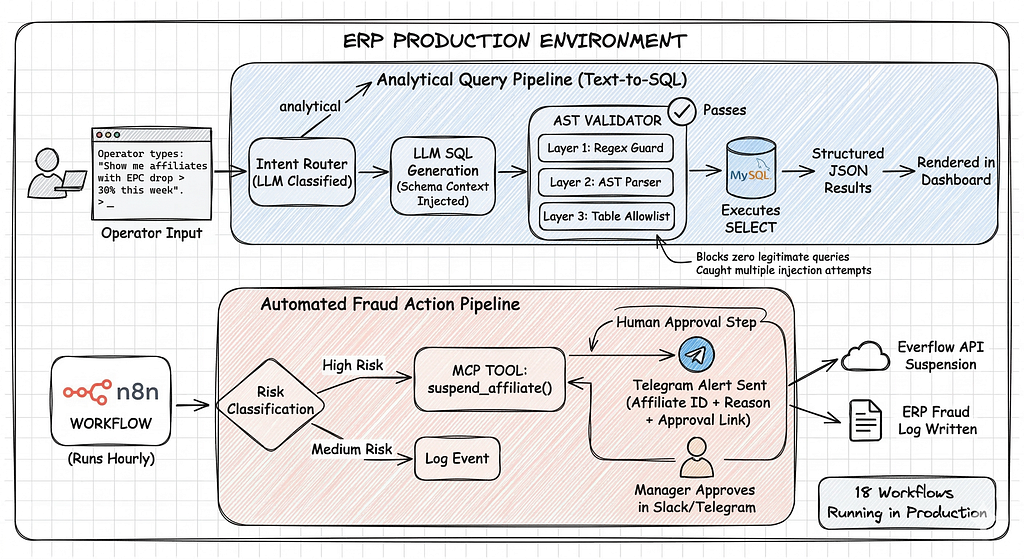
The full pipeline running on the ERP:
- Operator types: “Show me affiliates with EPC drop > 30% this week”
- Router classifies: analytical → Text-to-SQL path
- LLM generates SQL with schema context injected
- AST Validator runs all 3 layers — passes
- MySQL executes the SELECT
- Results returned as structured JSON → rendered in dashboard
For fraud actions:
- n8n workflow detects suspicious pattern hourly
- Classifies risk level (High / Medium)
- High Risk → MCP tool suspend_affiliate() called with human approval step
- Telegram alert sent with affiliate ID + reason + approval link
- On approval → Everflow API suspension + ERP fraud log written
18 workflows running this pattern in production. The validator has blocked zero legitimate queries and caught multiple injection attempts during testing.
Lessons and What I’d Do Differently
What worked better than expected: The 3-layer approach felt over-engineered at first. In practice, each layer earned its place — regex catches fast, AST catches clever, allowlist catches lateral movement.
What I underestimated: The semantic layer. Telling the LLM what your tables mean (not just their names) dramatically improves SQL quality. affiliate_tier means nothing to an LLM — affiliate_tier (Platinum/Gold/Silver/AtRisk — performance classification) generates much better GROUP BY logic.
What’s missing:
- Eval CI gate — I have test queries but no automated accuracy tracking on every deploy. This is the next thing I’m building.
- pgvector for semantic table routing — right now the allowlist is static. A vector similarity layer could dynamically scope which tables are relevant per query, reducing LLM context and improving accuracy.
The honest take: Most “production AI” demos you see online skip the security layer entirely. The AST Validator is boring to explain and satisfying to build. It’s also the part that makes the difference between a demo and something you’d actually let run on your company’s database.
The Architecture in One Diagram

Brain = Text-to-SQL + AST Validator → read-only analytics, any complexity Hands = Function Calling via MCP → actions, human-in-the-loop, audit trail
The architecture isn’t “which one” — it’s knowing when to route to which.
If you’re building something similar or have questions about the AST approach — drop a comment. Always curious what tradeoffs others are hitting in prod.
thanks for reading !
Rayane !!!!
How I Built a Production AI Query Engine on 28 Tables — And Why I Used Both Text-to-SQL and… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.