
LumberChunker: Long-Form Narrative Document Segmentation
LumberChunker lets an LLM decide where a long story should be split, creating more natural chunks that help Retrieval Augmented Generation (RAG) systems retrieve the right information.
Introduction
Long-form narrative documents usually have an explicit structure, such as chapters or sections, but these units are often too broad for retrieval tasks. At a lower level, important semantic shifts happen inside these larger segments without any visible structural break. When we split text only by formatting cues, like paragraphs or fixed token windows, passages that belong to the same narrative unit may be separated, while unrelated content can be grouped together. This misalignment between structure and meaning produces chunks that contain incomplete or mixed context, which reduces retrieval quality and affects downstream RAG performance. For this reason, segmentation should aim to create chunks that are semantically independent, rather than relying only on document structure.
So how do we preserve the story’s flow and still keep chunking practical?
In many cases, a reader can easily recognize where the narrative begins to shift—for example, when the text moves to a different scene, introduces a new entity, or changes its objective. The difficulty is that most automated chunking methods do not consider this semantic signal and instead rely only on surface structure. As a result, they may produce segmentations that look reasonable from a formatting perspective but break the underlying narrative coherence.
To make this concrete, consider the short passage below and decide the optimal chunking boundary!
Text
Segmentation Quiz
Choose the best way to segment this passage into
semantic chunks
best segmentation
The LumberChunker Method
In the example above, Option C provides the most coherent segmentation. The boundary aligns with the point where the narrative becomes semantically independent from the preceding context.
Our goal is to make this type of segmentation decision practical at scale. The challenge is that human-quality boundary detection requires understanding narrative context, which is expensive to apply across thousands of paragraphs in long-form documents.
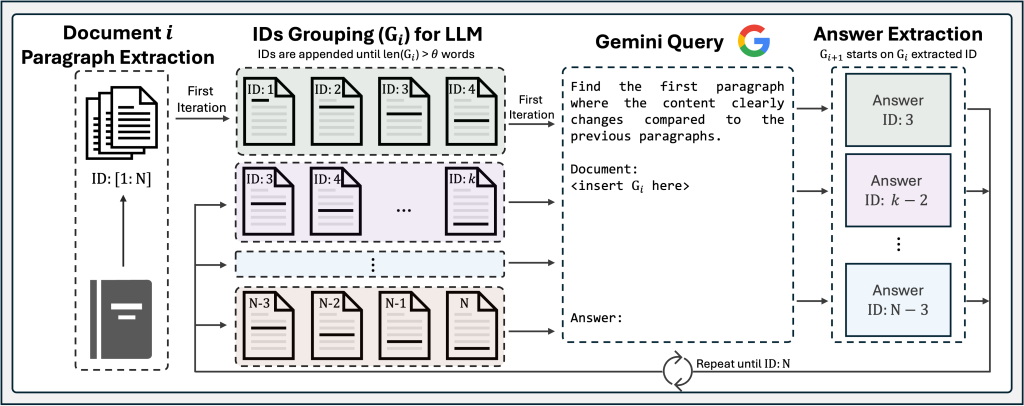
LumberChunker approaches this by treating segmentation as a boundary-finding problem: given a short sequence of consecutive paragraphs, we ask a language model to identify the earliest point where the content clearly shifts. This formulation allows segments to vary in length while remaining aligned with the underlying narrative structure. In practice, LumberChunker consists of these steps:
1) Document Paragraph Extraction
Cleanly split the book into paragraphs and assign stable IDs (ID:1, ID:2, …). This preserves the document’s natural discourse units and gives us safe candidate boundaries.
Example: From a novel, we extract:
ID:1“The morning sun filtered through the dusty windows…”ID:2“She walked slowly to the door, hesitating…”ID:3“Meanwhile, across town, Detective Morrison reviewed the case files…”ID:4“The previous night’s events had left him puzzled…”Each paragraph gets a unique ID for tracking boundaries.
2) IDs Grouping for LLM
Build a group G_i by appending paragraphs until the group’s length reaches a token budget θ. This provides enough context for the model to judge when a topic/scene actually shifts.
Example: With
θ = 550tokens, we build, per example:
G_1= [ID:1,ID:2,ID:3,ID:4,ID:5,ID:6]This window, by spanning multiple paragraphs, increases the chance that at least one meaningful narrative shift is present within the context.
3) LLM Query
Prompt the model with the paragraphs in G_i and ask it to return the first paragraph where content clearly changes relative to what came before. Use that returned ID as the chunk boundary; start the next group at that paragraph and repeat to the end of the book.
Example: Given G_1 = [p1, p2, p3, p4, p5, p6], the LLM responds: p3
Answer Extraction:
We extract p3 as the boundary. This creates:
- Chunk 1: [
p1,p2] - Next group (
G_2) starts atp3
GutenQA: A Benchmark for Long-Form Narrative Retrieval
To evaluate our chunking approach, we introduce GutenQA, a benchmark of 100 carefully cleaned public-domain books paired with 3,000 needle-in-a-haystack type of questions. This allows us to measure retrieval quality directly and then observe how better retrieval leads to more accurate answers in a RAG system.



Key Findings
Retrieval: LumberChunker leads 
LumberChunker leads across both DCG@k and Recall@k. By k=20, it reaches DCG ≈ 62.1% and Recall ≈ 77.9%, showing that better segmentation improves not only which passages appear first, but also how reliably the right context is retrieved.
Retrieval Performance Comparison
- DCG @ k
- Recall@k
| 1 | 2 | 5 | 10 | 20 | |
|---|---|---|---|---|---|
| Semantic Chunking | 29.50 | 35.31 | 40.67 | 43.14 | 44.74 |
| Paragraph-Level | 36.54 | 42.11 | 45.87 | 47.72 | 49.00 |
| Recursive Chunking | 39.04 | 45.37 | 50.66 | 53.25 | 54.72 |
| HyDE† | 33.47 | 39.74 | 45.06 | 48.14 | 49.92 |
| Proposition-Level | 36.91 | 42.42 | 44.88 | 45.65 | 46.19 |
| LumberChunker | 48.28 | 54.86 | 59.37 | 60.99 | 62.09 |
| 1 | 2 | 5 | 10 | 20 | |
|---|---|---|---|---|---|
| Semantic Chunking | 29.50 | 38.70 | 50.60 | 58.21 | 64.51 |
| Paragraph-Level | 36.54 | 45.37 | 53.67 | 59.34 | 64.34 |
| Recursive Chunking | 39.04 | 49.07 | 60.64 | 68.62 | 74.35 |
| HyDE† | 33.47 | 43.41 | 55.11 | 64.61 | 71.61 |
| Proposition-Level | 36.91 | 45.64 | 51.04 | 53.41 | 55.54 |
| LumberChunker | 48.28 | 58.71 | 68.58 | 73.58 | 77.92 |
Downstream QA: Targeted Retrieval Outperforms Large Context Windows
We find that even with very large context windows, a non-retrieval setup still performs worse than RAG, showing that selecting focused, relevant passages is more effective than simply increasing the amount of raw context. Under this setting, when integrated into a standard RAG pipeline on a GutenQA subset, our RAG-LumberChunker is second only to RAG-Manual, which uses hand-segmented ground-truth chunks.
Downstream QA Accuracy (%)
A Sweet Spot Around θ ≈ 550 Tokens
We sweep θ ∈ [450, 1000] tokens and find that θ ≈ 550 consistently maximizes retrieval quality: large enough for context, small enough to keep the model focused on the current turn in the story.
DCG@k vs Token Budget (θ)
This does not mean the resulting chunks are large. In practice, as the table shows, the average chunk size is about 334 tokens, which suggests that LumberChunker often detects earlier semantic shifts within the window.
| Method | Avg. #Tokens / Chunk | Total #Chunks |
|---|---|---|
| Semantic Chunking | 185 tokens | 191059 |
| Paragraph Level | 79 tokens | 248307 |
| Recursive Chunking | 399 tokens | 31787 |
| Proposition-Level | 12 tokens | 914493 |
| LumberChunker | 334 tokens | 36917 |
Conclusion
LumberChunker reframes document chunking as a semantic boundary detection problem. Instead of relying on fixed token limits or surface structure, it uses a rolling context window to identify the earliest point where the meaning of the text becomes independent from what came before, producing segments that better align with the underlying narrative structure.
On the GutenQA benchmark, LumberChunker consistently improves retrieval and downstream QA over traditional fixed-size and recursive methods, approaching the quality of manual, human-curated segmentations.
These results suggest that segmentation is not just a preprocessing step, but a core design choice for retrieval systems. By creating semantically independent chunks, LumberChunker provides a practical way to improve how long-form documents are retrieved and used in RAG pipelines.
Citation
If you find LumberChunker useful in your research, please consider citing:
@inproceedings{duarte-etal-2024-lumberchunker,
title = "{L}umber{C}hunker: Long-Form Narrative Document Segmentation",
author = "Duarte, Andr{'e} V. and Marques, Jo{~a}o DS and Gra{c{c}}a, Miguel and Freire, Miguel and Li, Lei and Oliveira, Arlindo L.",
editor = "Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.377/",
doi = "10.18653/v1/2024.findings-emnlp.377",
pages = "6473--6486",
abstract = "LumberChunker reframes document chunking as a semantic boundary detection problem..."
}
Blog created by Raymond Jiang and André Duarte