
Reproducing: No Free Lunch Theorems for Optimization
Understanding Why There’s no Universally Best Algorithm

The Big Idea
There is no universally best algorithm — every algorithm that excels at some problems must necessarily fail at others, unless you make assumptions about what kinds of problems actually matter.
Overview
This post is part of a different style of writing I am experimenting with: exploring, reproducing, and deeply understanding foundational papers in artificial intelligence and machine learning, along with their implications for the trajectory of the field.
In this piece, I focus on the No Free Lunch (NFL) theorem, one of the most important theoretical results in machine learning. The theorem is often referenced, but rarely explained in a way that is useful for practicing engineers or researchers.
The goal of this post is to bridge that gap.
First, I explain the core idea of the theorem simply. Then I walk through what the theorem actually proves and the assumptions it relies on. Finally, I present a small empirical reproduction that makes the intuition concrete and discuss the broader implications of the result.
For the reproduction, I use a fixed dataset of MNIST embeddings as the input space and compare two learning approaches: logistic regression and k-nearest neighbors. The goal is not to prove the theorem empirically (which would require averaging over all possible problems), but to illustrate its central insight: different learning algorithms encode different assumptions about the structure of the world.
Due to these assumptions, each algorithm will perform well on some problems and poorly on others. Ultimately, the No Free Lunch theorem changes how we should think about algorithm comparisons.
Before understanding the theorem, it is easy to fall into the mindset:
“Algorithm X is better than Algorithm Y.”
But after understanding the No Free Lunch theorem, the framing becomes much more precise :
“Algorithm X assumes structure S. Algorithm Y assumes structure T.
If the problem exhibits structure S, algorithm X will perform well.
If the problem exhibits structure T, algorithm Y will perform well.
Averaged across all possible problems (including completely random ones), their performance is identical.”
In other words, there is no universally superior learning algorithm. What matters is the alignment between the assumptions encoded by the algorithm and the structure present in the problem.
As shown in this post, this perspective has deep implications for how we evaluate models, design learning systems, and think about progress in artificial intelligence.
There is no universally superior learning algorithm. What determines performance is the alignment between the assumptions encoded by the algorithm and the structure present in the problem to solved.
Introduction: What the Theorem Actually Says
In 1997, David Wolpert and William Macready proved the seemingly counterintuitive No free Lunch theorems. In summary, it puts forward that if averaged across all possible problems, every optimization algorithm performs equally well (or equally poorly). This is often misquoted as “all algorithms are equal” but that’s misleading and misses the point.
If averaged across all possible problems, every optimization algorithm performs equally well (or equally poorly)
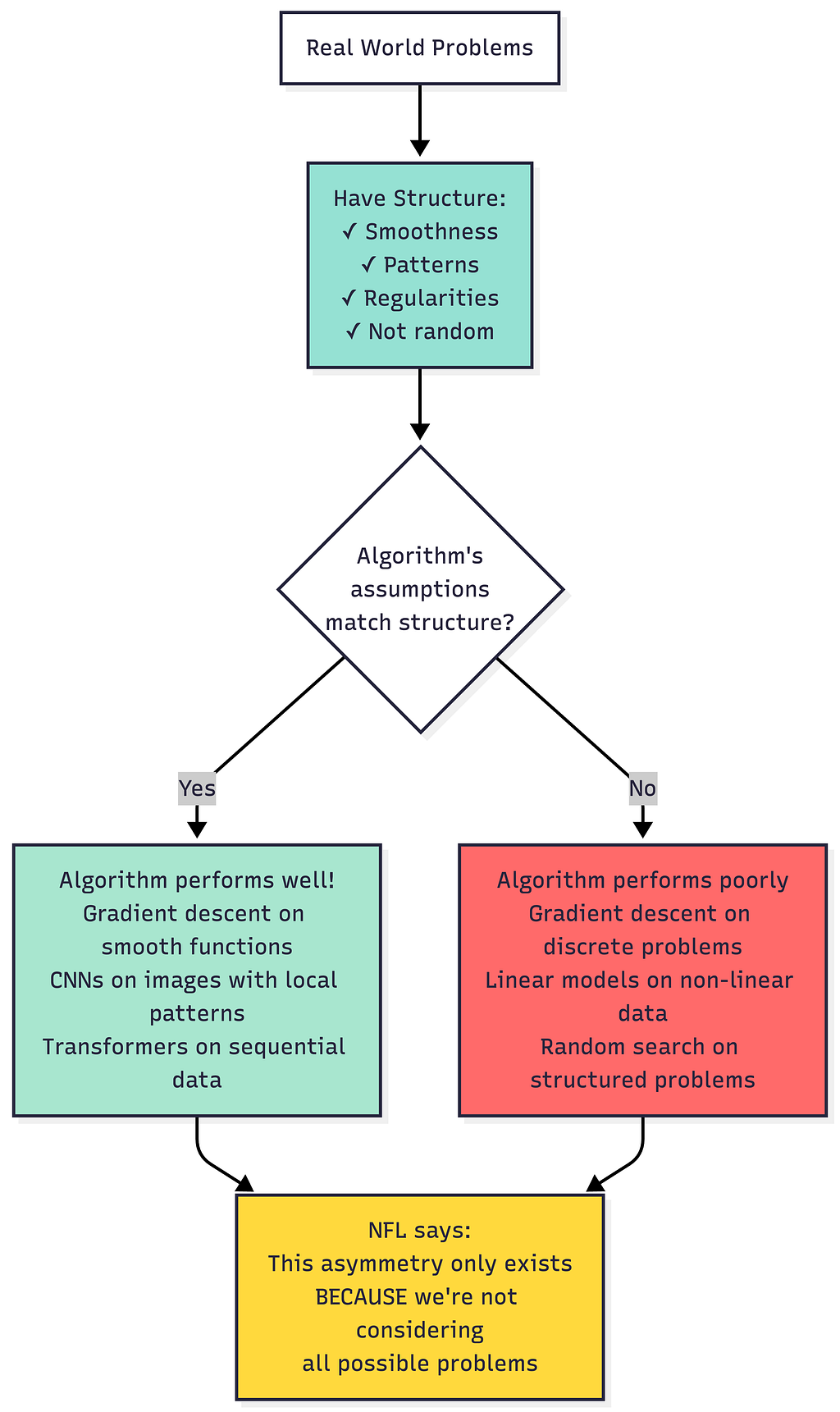
The theorem explains that performance isn’t free. To get good results, you must pay with assumptions about your problem. The more your algorithm’s built-in biases match the problem’s structure, the better it performs. What does this look like in the real world?
- Gradient descent works great for smooth optimization problems (it assumes smoothness)
- Random search works terribly for those same problems (it assumes nothing)
But on completely random problems, they’re equally useless.
The theorem doesn’t say optimization is pointless. It says optimization works because the real world where problems occur has structure, and good algorithms exploit that structure.
Performance isn’t free. To get good results, you must pay with assumptions about your problem. The more your algorithm’s built-in biases match the problem’s structure, the better it performs.
An Analogy: The Lock-Picking Problem
Imagine you have 1,000 different locks to open, and you can choose different strategies for this task:
- Strategy A could be to try keys in order (1, 2, 3, …) — This works great if locks use sequential keys. It will be terrible if keys are random
- Strategy B could be to try keys randomly — This would work equally poorly on all locks. This makes no assumptions and has no peculiar advantage.
- Strategy C: Try master keys first — This works great if locks share common patterns. A terrible choice if every lock is unique
The insight from NFL in this illustration is that If the 1,000 locks are completely random (i.e every possible arrangement is equally likely), all three strategies perform equally on average. Strategy A’s advantage on sequential locks is exactly canceled by its disadvantage on reverse-sequential locks. But in reality, locks aren’t random. They follow patterns — manufacturers reuse designs, security standards exist. So Strategy C wins because its assumption (common patterns exist) matches reality.
The point here is your strategy only works if your assumptions match the world which the strategy would be leveraged.
Your strategy only works if your assumptions match the world which the strategy would be leveraged.
Explaining The Core Proof
The No Free Lunch theorem is purely a theoretical study. It is not based on experiments or datasets. It uses formal definitions and a symmetry argument about the space of possible problems. The proof is made in 3 steps
Step 1: Define the playing field or what counts as a problem
First, the authors define a “problem” as an objective function

- X is the set of possible candidate solutions.
- Y is the set of possible scores or outcomes.
Different problems correspond to different ways of assigning scores to the same set of candidate solutions. The space of all possible problems is simply the set of all such functions.

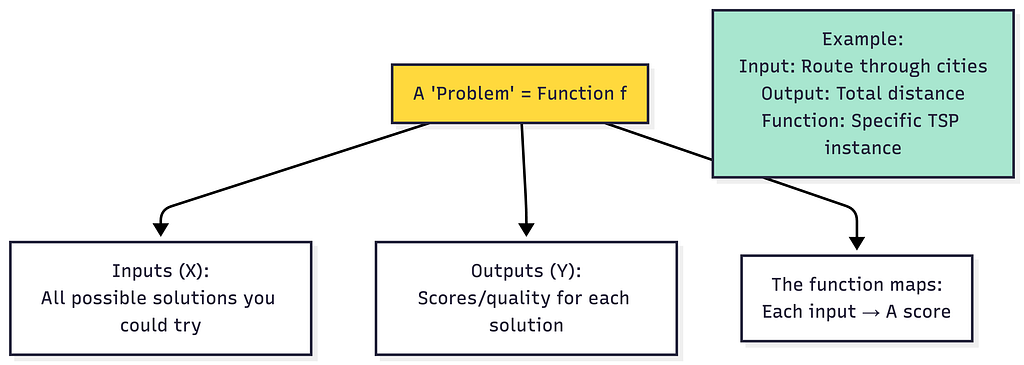
An important constraint here is that both inputs and outputs are finite (as computers can only represent finite numbers). This makes the math work.
Step 2: Make an assumption about how problems are distributed — The “all problems equally likely” assumption
The critical assumption of the paper is that: every possible function is treated as equally likely. There is no smoothness, no structure, no pattern — just all possible mappings from inputs to outputs, weighted uniformly. This assumption represents complete ignorance about the problem-generating process. And it is this assumption that drives the result.
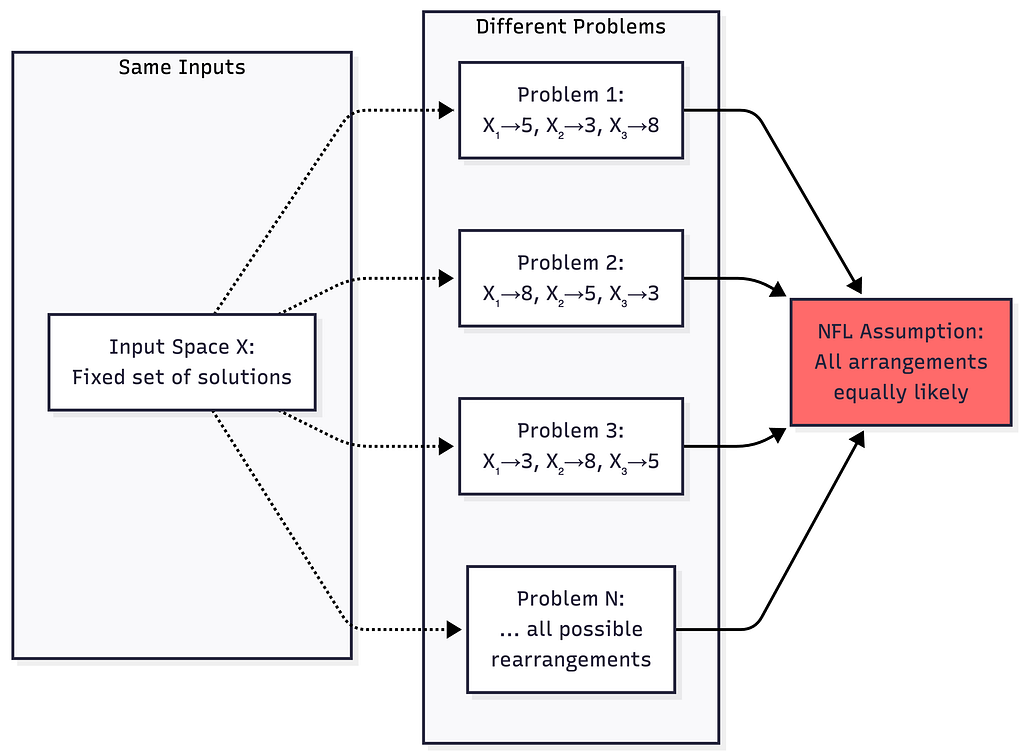
The assumption represents complete ignorance — you know nothing about which problems are likely.
Step 3: Induce a symmetry based on the assumption (The permutation argument)
For any problem where Algorithm A performs well, there exists a “mirror problem” where it performs poorly:
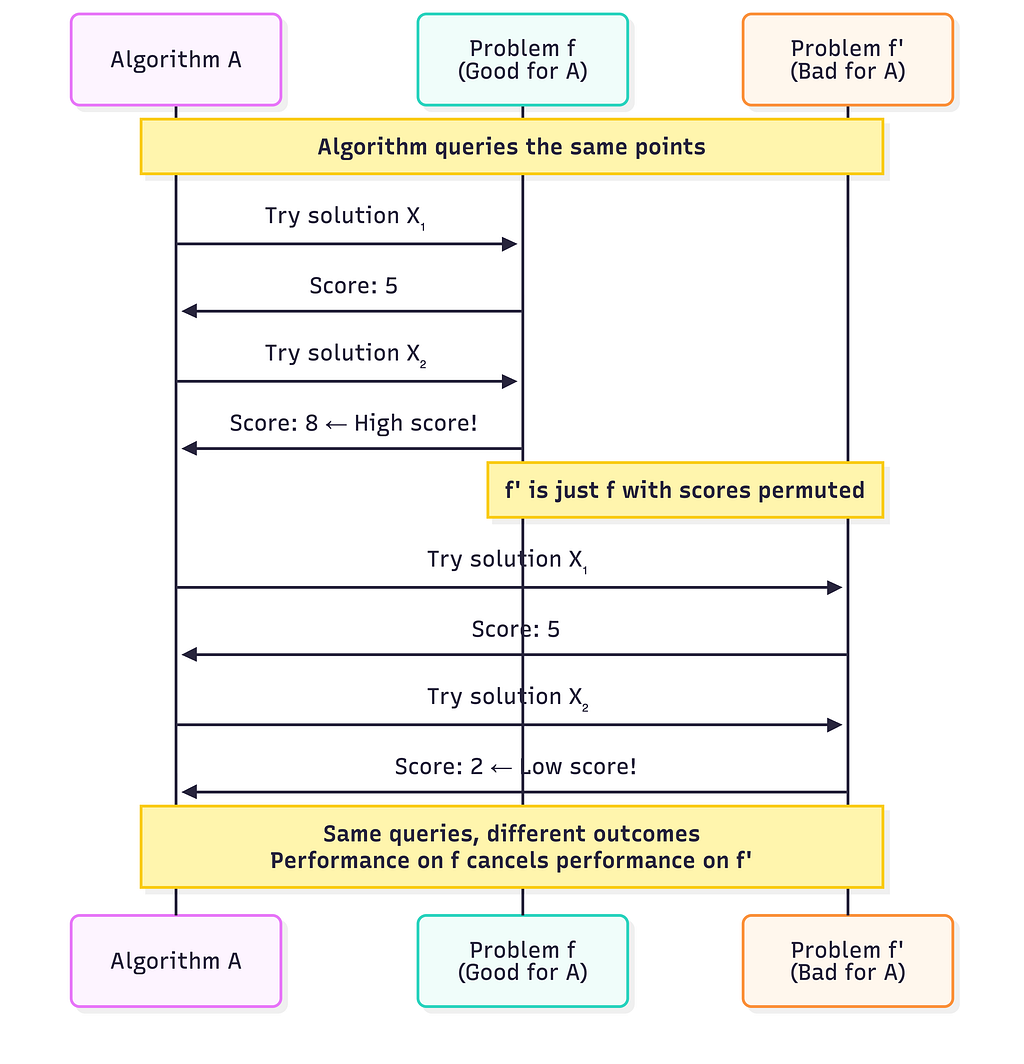
The key insight here is that the algorithm sees the same sequence of scores (5, then 8 vs. 5, then 2). However because scores are attached to different inputs in f’, the algorithm’s final performance is different. Every good problem for the algorithm has a corresponding bad problem. These pairs exactly cancel when you average across all problems
Every good problem for the algorithm has a corresponding bad problem
When you average performance across all possible problems, the good and bad cancel perfectly. i.e :
Average performance of Algorithm A = Average performance of Algorithm B = Average performance of Random Search
The crux of what NFL proofs isn’t that all algorithms are equally good in practice. Neither is it that Optimization doesn’t work or Random search is as good as gradient descent. Rather it says performance advantage on some problems requires performance disadvantage on others. That every algorithm makes assumptions that work for some problems but not others and that if you claim your algorithm is better, you must specify: better for which kinds of problems?
Reproduction: Same Inputs, Different Labelings, Different Winners
To make the No Free Lunch intuition concrete, I built a small reproduction in a supervised-learning setting. The core idea here is to hold the inputs fixed and change only the task. i.e the inputs stay the same, but the labeling function changes. This lets us cleanly separate what the world looks like from what problem we are trying to solve on it. In NFL terms, the labeling function is “the problem.”
You can find all the executed code for this experiment in this notebook.
The Setup

I start by fixing a dataset of inputs X. Specifically, I use MNIST images, but not in raw pixel form. Instead, I first train a small convolutional neural network on MNIST, freeze it, and extract the activations from its penultimate layer. Each image is now represented as a vector of real-valued features, giving a fixed point cloud
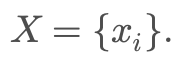
This design choice is deliberate. By working in an embedding space rather than raw pixels, the experiment focuses on differences in inductive bias — how algorithms prefer to generalize — rather than differences in feature engineering or representational power.
At this point, the input space is frozen. Nothing about the images or embeddings will change.
The Competitors
Algorithm 1: Logistic Regression
- Assumption: Decision boundary is linear (a hyperplane)
- Strength: Finds optimal hyperplane quickly
- Weakness: Can’t handle non-linear boundaries
Algorithm 2: k-Nearest Neighbors (kNN)
- Assumption: Nearby points have similar labels (local structure)
- Strength: Captures complex local patterns
- Weakness: Struggles with global linear patterns, needs lots of data
The Results
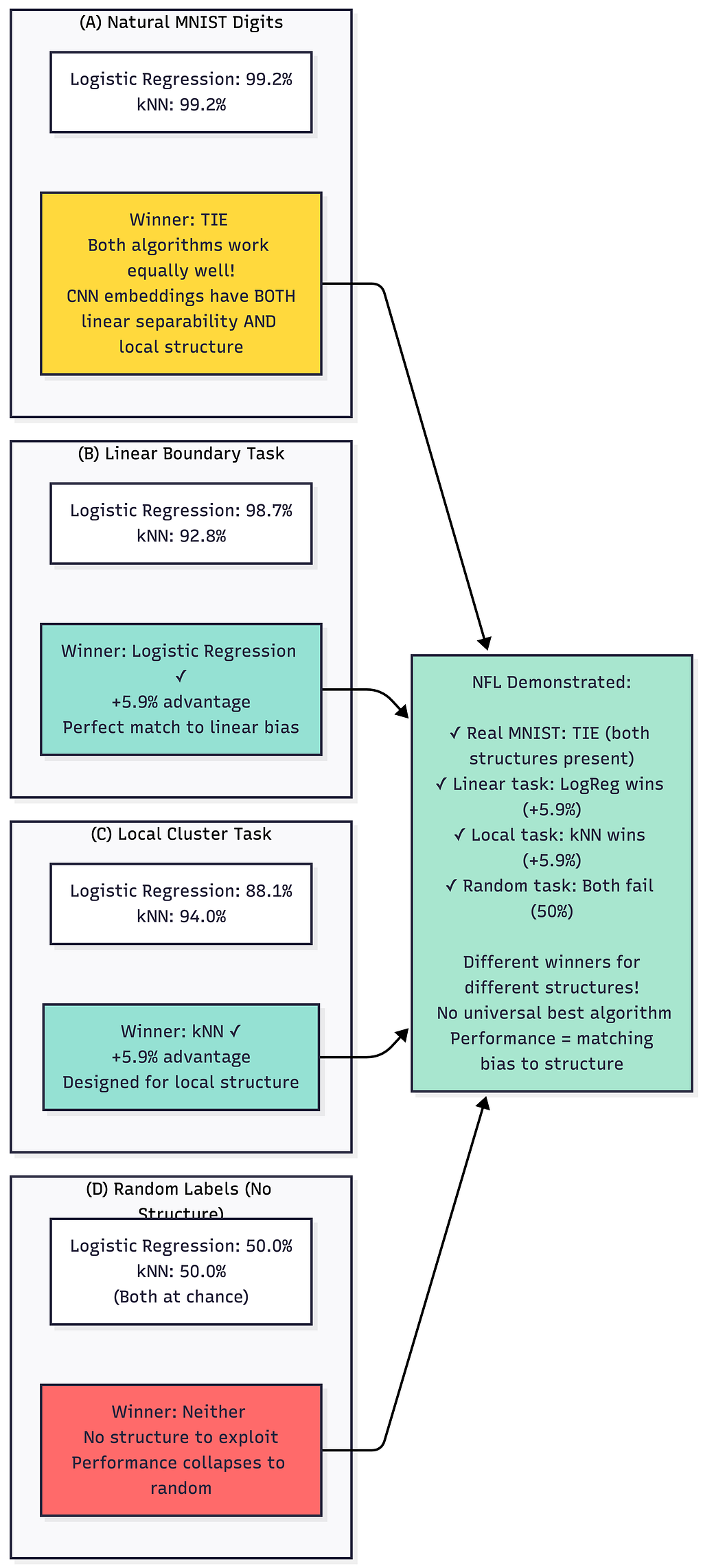
What this shows:
- Same inputs (MNIST embeddings), different tasks (different labelings)
- Winner changes based on which task
- No structure (random labels) equals no winner
This is NFL in action
Practical Implications of the No Free Lunch (NFL) Theorems for AI
1. The Necessity of Problem-Specific Customization
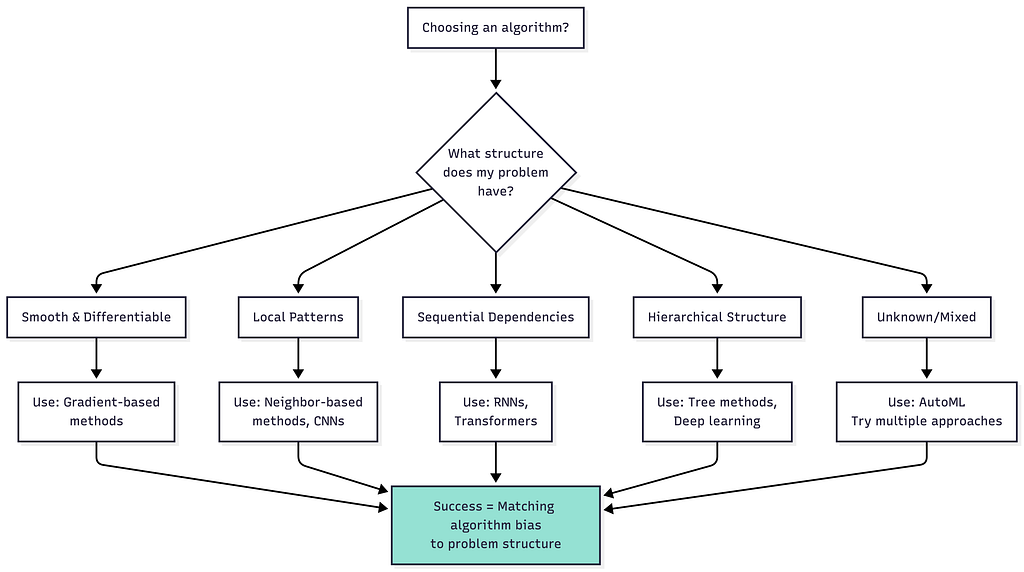
The most immediate implication for AI engineers is that effective optimization is impossible without domain assumptions. There is no algorithm that is inherently better than all others across all problems. When choosing algorithms, ask:
- What structure does my problem have?
- Which algorithm’s biases match that structure?
- What am I assuming about future problems?
There is no algorithm that is inherently better than all others across all problems.
2. Benchmarks Only Tell Part of the Story
NFL places strict limits on how experimental results should be interpreted in AI research.
Strong performance on a small collection of benchmark tasks does not justify broad claims of superiority. Mathematically, excelling on one subset of problems guarantees underperformance on others unless the task distribution is explicitly restricted. Without specifying which kinds of problems matter, benchmark results alone have limited meaning.

Strong performance on a small collection of benchmark tasks does not justify broad claims of superiority.
This does not make benchmarking useless — but it does mean benchmarks must be treated as representatives of a distribution, not as universal tests. When researchers claim generalization, they are implicitly assuming that future problems will resemble the benchmark distribution. NFL makes this assumption explicit and unavoidable. The practical implication of this is not to trust benchmarks blindly. Test on your data distribution as well.
3. Why AutoML and Meta-Learning Exist
NFL provides a theoretical justification for AutoML and meta-learning approaches.
Since no single algorithm is best across all problems, effective systems must adaptively select and tune algorithms based on the task. AutoML pipelines exist precisely to automate this matching process — choosing models, architectures, hyperparameters, and representations that align with the dataset at hand. Meta-learning goes a step further by learning how to match algorithms to problems based on prior experience. In effect, it learns priors over problem families, trading universality for structured adaptability.
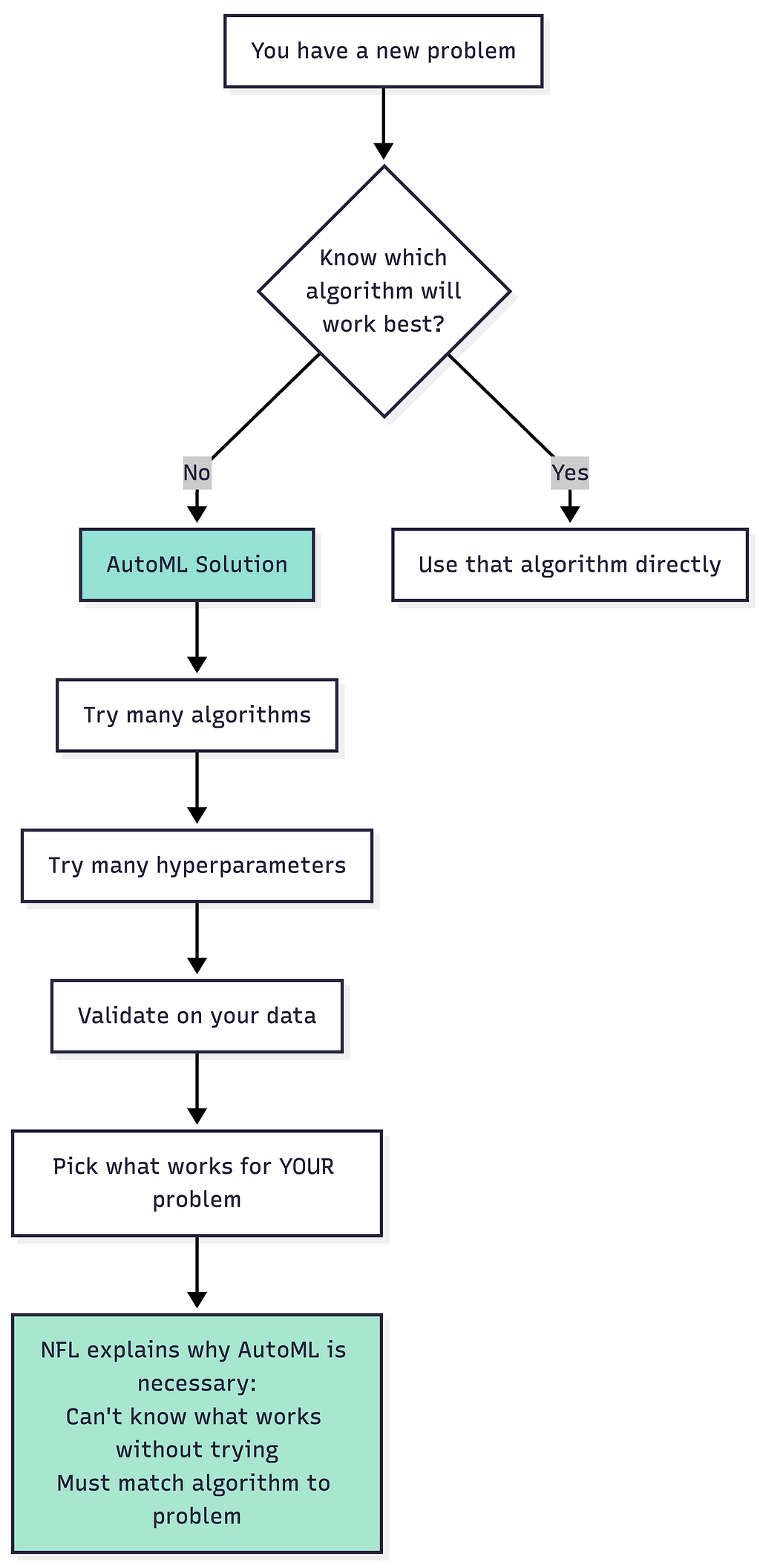
AutoML isn’t lazy — it’s a rational response to NFL. You have to match algorithms to problems.
4. Rethinking Artificial General Intelligence (AGI)
NFL fundamentally reshapes how AGI should be understood. There is no distribution-independent notion of intelligence. Generality is always relational: an agent is general only relative to a family of tasks and a probability distribution over those tasks. Remove those assumptions, and the concept collapses.
This means claims of universal intelligence or distribution-free robustness are mathematically empty. Even small changes in the task distribution can invalidate an agent’s performance guarantees. What looks robust in one environment may fail abruptly in another.

The implication here is that AGI is not about universality; it is about broad but still bounded alignment to a structured world. Per NFL, true universality is impossible.
Per NFL, true universality is impossible
5. Implications for AI Safety
Taken together, NFL and related theoretical results impose serious constraints on AI safety which include
- No Universal Safety: You can’t prove an AI is “safe in general” — only safe for specific problem distributions
- Robustness is Fragile: Small distribution shifts can break systems because the assumptions no longer hold
- Self-Certification is Impossible: An AI can’t verify its own safety across all possible futures (would require solving NFL)
This implies that AI safety requires continuous monitoring and assumption validation, not a one-time certification.

Conclusion + Key Takeaways
The NFL theorem shows that there is no magic algorithm that’s universally best. Success comes from understanding your problem’s structure and choosing (or designing) algorithms that exploit that specific structure. Also Performance isn’t free — you pay with assumptions. Make good assumptions, get good performance. Make wrong assumptions, get poor performance. A quick recap of the core tenets explored:
- The Theorem: When averaged across all possible problems, every algorithm performs equally.
- The Assumption: All problems are equally likely (complete ignorance about structure).
- The Proof: For every problem where algorithm A excels, there’s a mirror problem where it fails. These cancel perfectly in the average.
- The Reality: Real-world problems aren’t random — they have structure (smoothness, locality, patterns).
- The Implication: Algorithms work by exploiting structure. The better your algorithm’s assumptions match reality, the better it performs. Miss the match, performance collapses.
- The Lesson: For engineers — choose algorithms whose biases match your problem. For researchers — specify which problem distributions you’re optimizing for. For safety — understand that performance guarantees are always conditional on assumptions holding
References
- Wolpert, D. H., & Macready, W. G. (1997). No free lunch theorems for optimization.IEEE Transactions on Evolutionary Computation, 1(1), 67–82. https://doi.org/10.1109/4235.585893
- ayoakin. (2026). No Free Lunch (NFL) demo. GitHub notebook.
I write weekly posts explaining AI systems, ML models, and technical ambiguity for builders and researchers. Follow if you want the clarity without the hype.
For more on AI & ML Algorithms 🤖, Check out other posts in this series:
List: Machine Learning Algorithms from Scratch | Curated by Ayo Akinkugbe | Medium
Reproducing: No Free Lunch Theorems for Optimization was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.