
Why AI Products Need a Data Strategy, Not Just a Feature Strategy
Companies like to talk about AI products as if they were ordinary software. You define a feature, build it, launch it, and improve it.
That language is familiar. It is also misleading.
In ordinary software, a new feature is mostly a matter of logic and implementation. In AI, a new feature often depends on something far less visible: new examples, new corrections, new evidence about where the system fails, and new ways of turning those failures into something useful.
That changes the nature of product design. An AI product is not just something that performs tasks for users. It is also a system for discovering what it still does not know.
Many companies still miss that distinction. They spend months debating architecture, model choice, latency, cost, and interface details. All of those matter. But the real ceiling often appears elsewhere. The product was never built to expose its own weaknesses in a form that the company can learn from.
So the team keeps tuning. It edits prompts. It changes workflows. It swaps one model for another. Sometimes that helps. Often, it only buys time. The deeper problem remains: the system cannot improve in directions it has not been designed to observe.
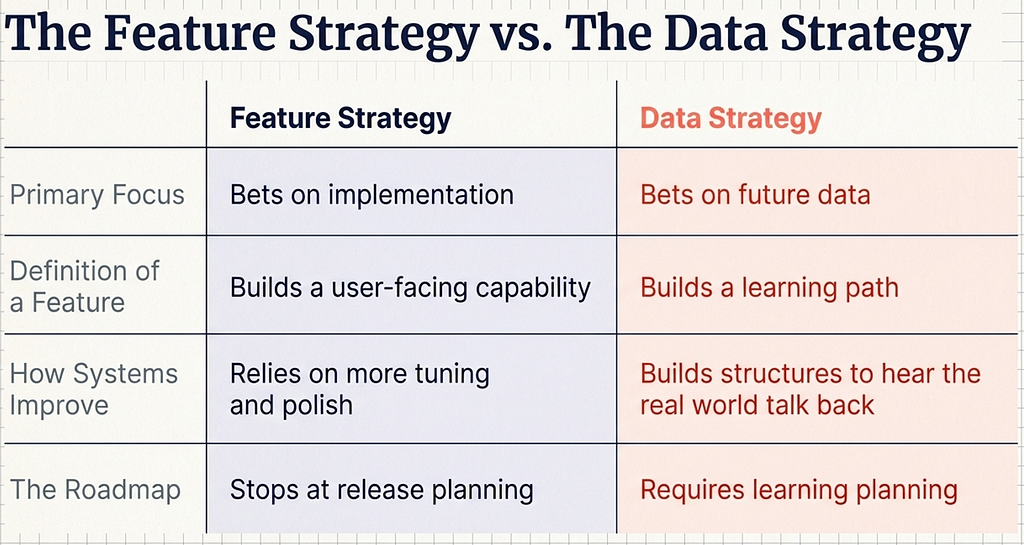
That is why AI products need a data strategy, not just a feature strategy.
The hidden half of every AI feature
When a company adds a feature to ordinary software, most of the work is building it.
When a company adds a feature to an AI product, the work is split into two. One half is visible: the interface, the workflow, the model behavior the user encounters. The other half is quieter but just as important: the product’s ability to gather the data that will make that feature reliable in the real world.
Take a writing assistant that introduces “brand voice.” On paper, that sounds like a feature. In practice, it is also a demand for new data: examples of preferred phrasing, rejected tone, accepted edits, and repeated corrections. A meeting assistant that begins extracting action items does not only need a better prompt. It needs corrected ownership assignments, messy examples of indirect commitments, and evidence from overlapping, imperfect conversations. A support bot entering a new industry does not only need a new interface and some documentation. It needs real failures from real users speaking in the vocabulary of that field.
The visible feature is only half the product. The other half is the path by which the product learns to do that feature well.
The question product teams often forget to ask
Most feature planning still revolves around the same familiar questions: What will the user see? How will the workflow change? What model will power it? What metric will define success?
AI products require another question, and it may be the most important one:
What will this product need to learn next, and how exactly will it learn it?
That question forces a team to think differently. A new feature is no longer just a user-facing capability. It is also a bet about future data.
A team launching multilingual support is also introducing new ambiguity, formatting conventions, and failure modes. A system moving into a new customer segment is also moving into new long-tail behavior. A feature that looks complete in a demo may still be immature if the product lacks a reliable way to capture corrections, identify weak spots, and turn them into better evaluation and training data.
In other words, a roadmap for AI cannot stop at release planning. It has to include learning planning.
What useful learning signals actually look like
This is where many teams get vague. They say they will “collect feedback,” but feedback is not one thing, and much of it is weak.
Some of the most useful learning signals are direct corrections. A clinician fixes a dosage extracted by a medical assistant. A user chooses the better of three generated versions. A reviewer reassigns an action item to the correct person. These are valuable because they do not merely express dissatisfaction; they show what better looks like.
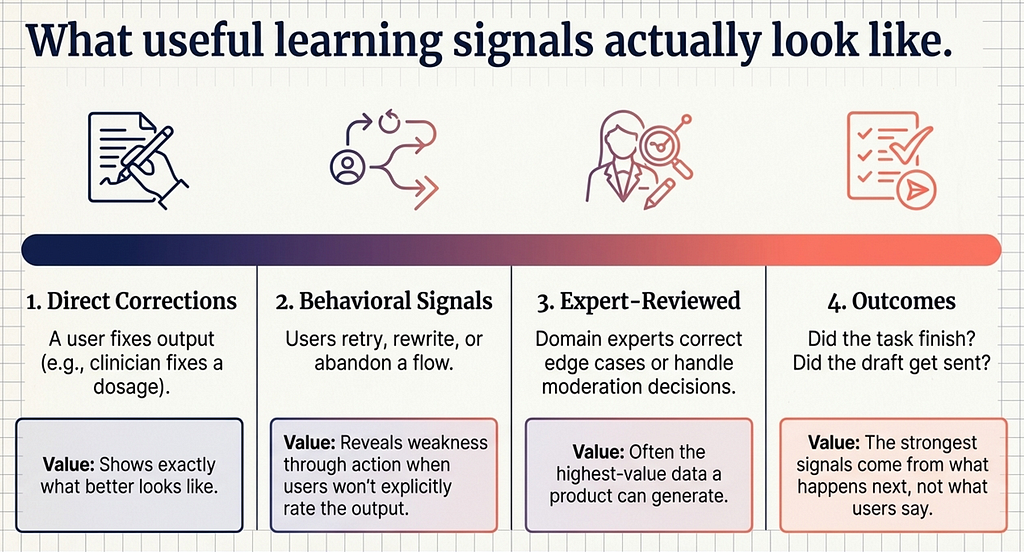
Other signals are behavioral. Users rarely explain their disappointment with neat labels, but they reveal it through their actions. They retry the request. They rewrite the output. They abandon the flow. They escalate to a human. An email assistant may receive almost no explicit ratings and still clearly show its weakness if users consistently rewrite greetings and closings before sending.
Then there are expert-reviewed cases, often the highest-value data a product can generate. Borderline fraud cases reviewed by analysts, difficult moderation decisions handled by specialists, uncertain legal or medical outputs corrected by domain experts — these can become far more important than vast amounts of passive logging.
And then there are outcomes. Did the user finish the task? Did the recommendation lead to action? Did the draft get sent? Did the alert change a decision? Some of the strongest signals in AI do not come from what the user says about the output, but from what happens next.
The point is not to collect everything. It is to collect evidence that reveals weakness in a form that the system can learn from.
More data is not the same as better data
This is where the conversation often becomes simplistic. Once teams realize they need more data, they assume volume will solve the problem.
Usually it does not.
Raw logs are not learning. A thumbs-down without context says very little. A user edit may reflect taste, not error. Large amounts of messy operational data can create the appearance of progress while making the system harder to improve. If the data is noisy, poorly categorized, or disconnected from real outcomes, the product may be collecting activity rather than knowledge.

What matters is whether the product creates trustworthy learning signals.
That usually means preserving context around a failure, distinguishing between weak hints and validated corrections, defining failure types early, tracking where examples came from, maintaining stable evaluation sets, and checking performance across meaningful slices rather than relying on averages.
A system can look healthy overall yet fail badly for one language, document type, user population, or environment. Aggregate success is often the best place for serious weakness to hide.
Why this is a product design problem, not just a machine learning problem
It is tempting to treat all of this as backend infrastructure: something for the ML team, the data team, or the evaluation team to deal with later.
But AI products do not learn from abstract pipelines. They learn through the structures the product makes possible.
A correction flow is not just a user experience detail. It may become future training data. A clarification question is not only good interaction design. It may expose recurring ambiguity that the company did not know it had. A review queue is not merely an operations tool. It may become the best labeled dataset in the business. A logging schema is not administrative plumbing. It determines whether a failure becomes a lesson or disappears into noise.

This is the deeper shift AI introduces. The product is no longer just delivering intelligence. It is shaping the conditions under which intelligence can improve.
That is why the strongest AI companies will not think of their systems as model-powered features. They will think of them as learning systems: products that create value today while deliberately generating the evidence needed to get better tomorrow.
What companies still misunderstand
The common fantasy is that AI can be inserted into a product and then improved in roughly the same way as any other feature: more tuning, more polish, better prompts, perhaps a better model.
Sometimes that works for a while. But eventually, the product reaches the edge of what its original data can support. At that point, the issue is no longer brilliance in implementation. It is whether the product was built to hear the real world talking back.

That is the mistake many roadmaps still make. They treat launch as the moment the product begins serving users. In AI, launch is also the moment the product begins teaching the company what it failed to understand.
The future of an AI product depends not only on what was built for release. It depends on whether the product was built to discover, capture, and organize its own ignorance.
That is what a real data strategy is for.
More from the AI Product Management Series
Why Your AI Product Isn’t Software: The New Rules of Uncertainty, Evidence, and Economics
AI Changes the Most Basic Assumption of Software Product Design
Why AI Products Need a Data Strategy, Not Just a Feature Strategy
Why AI Products Need a Data Strategy, Not Just a Feature Strategy was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.